FlashOcc: Fast and Memory-Efficient Occupancy Prediction via Channel-to-Height Plugin
Overview
Occupancy prediction has emerged as a powerful perception paradigm for autonomous driving, predicting per-voxel semantic labels in 3D space to handle arbitrary object geometries that detection-based systems miss. However, existing occupancy methods rely heavily on 3D convolutions or 3D transformer decoders to process volumetric features, which are computationally expensive and memory-intensive -- making real-time deployment on resource-constrained automotive platforms impractical.
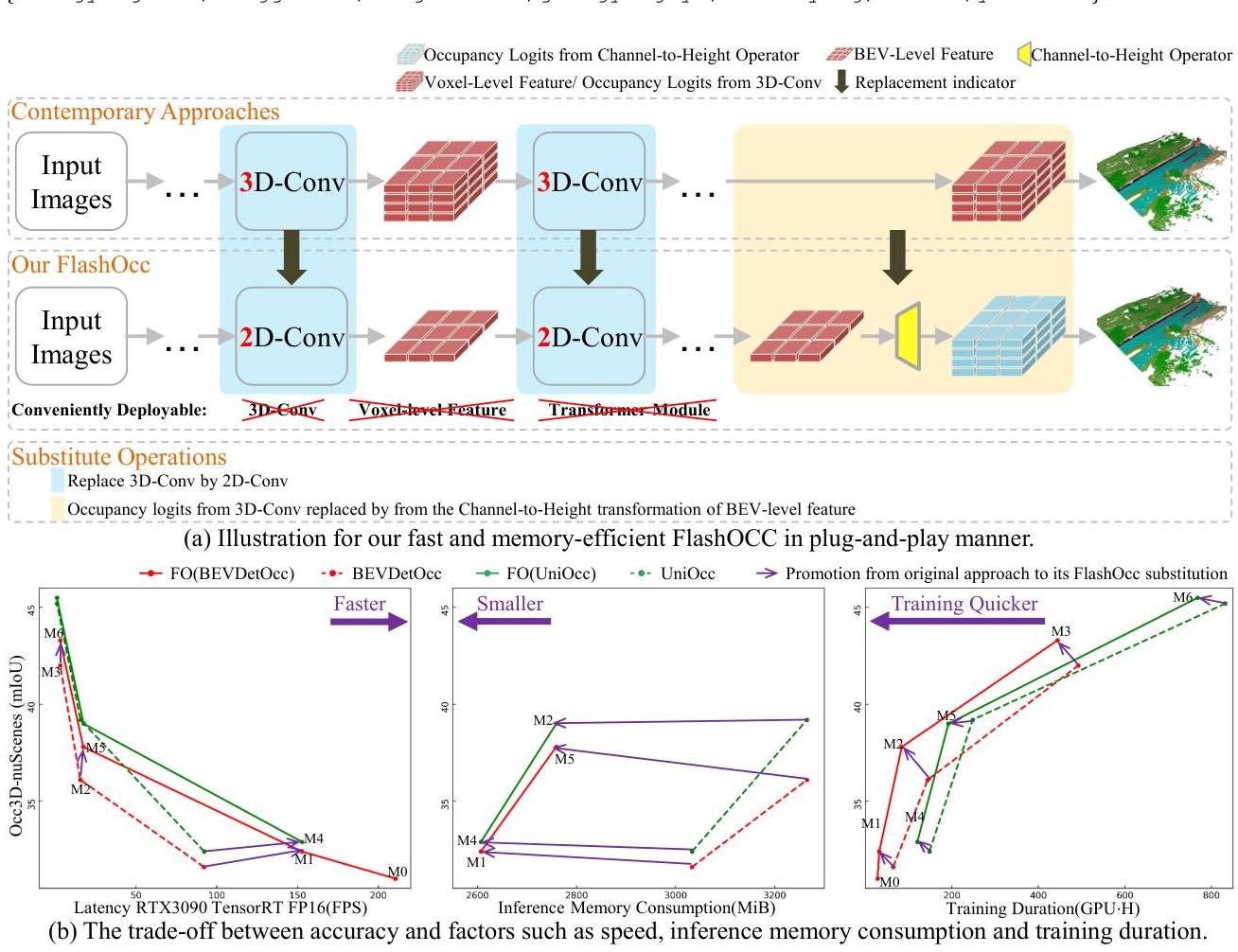
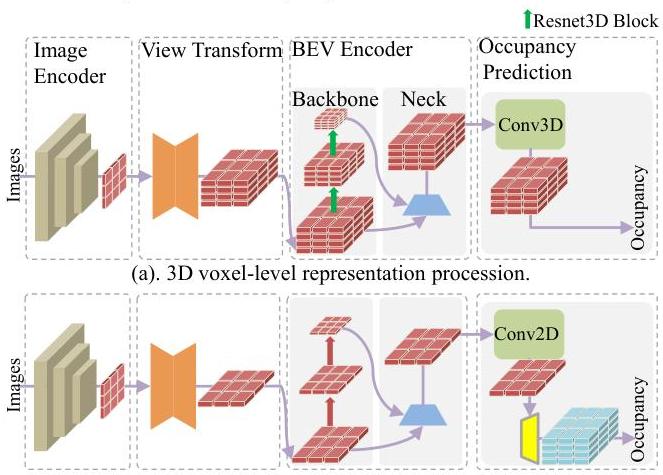
FlashOcc addresses this efficiency bottleneck with a surprisingly simple insight: the heavy 3D processing can be entirely replaced by 2D convolutions on BEV features, followed by a Channel-to-Height (C2H) transformation that reshapes the channel dimension of 2D BEV features into the height dimension to produce 3D occupancy volumes. The key observation is that BEV features already encode sufficient height information in their channel dimension when properly trained, so explicit 3D processing is redundant.
The framework is designed as a plug-and-play module that integrates with existing BEV-based perception pipelines such as BEVDetOcc, UniOcc, and FBOcc. On the Occ3D-nuScenes benchmark, FlashOcc keeps occupancy quality competitive while substantially reducing the cost of the occupancy head itself; on some baselines it improves mIoU, while on others it is roughly on par rather than uniformly better.
Key Contributions
- Channel-to-Height (C2H) plugin: A simple reshape operation that converts 2D BEV features with rich channel dimensions into 3D occupancy volumes, completely eliminating the need for 3D convolutions or 3D decoders
- Fully 2D processing pipeline: All feature processing (backbone, neck, BEV encoder) operates in 2D, with the 3D volume produced only at the final output stage via C2H, dramatically reducing compute and memory
- Plug-and-play design: The C2H module can be dropped into existing BEV-based frameworks (BEVDetOcc, UniOcc, FBOcc) with minimal modification, replacing their 3D decoders
- Temporal fusion variant (FlashOcc-T): Optional temporal BEV fusion that aggregates multi-frame information in 2D BEV space before the C2H transformation, further improving accuracy without heavy 3D temporal modules
- Deployment-ready efficiency: Achieves real-time inference speeds suitable for automotive platforms with limited GPU resources
Architecture / Method
┌─────────────────────────────────────────────────────────────────────┐
│ FlashOcc Pipeline │
│ │
│ ┌──────────┐ ┌───────────────┐ ┌──────────────┐ │
│ │ Multi-cam │───►│ 2D Backbone │───►│ View │ │
│ │ Images │ │ (ResNet/Swin) │ │ Transformer │ │
│ │ (N views) │ └───────────────┘ │ (LSS/BEVFmr) │ │
│ └──────────┘ └──────┬───────┘ │
│ │ │
│ BEV Features (B, C, H, W) │
│ │ │
│ ┌──────────────────────────▼──────────────┐ │
│ │ [Optional] Temporal BEV Fusion │ │
│ │ Align + Concat multi-frame BEV features │ │
│ └──────────────────────────┬──────────────┘ │
│ │ │
│ ┌──────────────────────────▼──────────────┐ │
│ │ 2D BEV Encoder (ResNet/FPN) │ │
│ │ Output: (B, C*Z, H_bev, W_bev) │ │
│ └──────────────────────────┬──────────────┘ │
│ │ │
│ ┌──────────────────────────▼──────────────┐ │
│ │ Channel-to-Height (C2H) Reshape │ │
│ │ (B, C*Z, H, W) ──► (B, C, Z, H, W) │ │
│ │ [Zero-cost reshape, no learned params] │ │
│ └──────────────────────────┬──────────────┘ │
│ │ │
│ ┌──────────────────────────▼──────────────┐ │
│ │ Occupancy Head (1x1 Conv) │ │
│ │ Output: (B, num_classes, Z, H, W) │ │
│ └─────────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────────┘
The FlashOcc pipeline consists of five components operating entirely in 2D until the final output:
1. Image Backbone: A standard 2D backbone (e.g., ResNet-50 or Swin-T) extracts multi-scale features from surround-view camera images. Each of the N cameras (typically 6) produces feature maps at multiple resolutions.
2. View Transformer: Converts perspective-view image features into a unified BEV representation. FlashOcc is agnostic to the view transformation method -- it works with both lift-splat-based (BEVDet-style depth prediction + pillar pooling) and query-based (BEVFormer-style spatial cross-attention) approaches. The output is a BEV feature map of shape (B, C, H_bev, W_bev).
3. BEV Encoder: A 2D convolutional encoder (e.g., ResNet or FPN-based) that processes the BEV features to enrich spatial representations. Crucially, this operates entirely in 2D -- no 3D convolutions. The encoder expands the channel dimension to C * Z, where Z is the number of height bins in the target occupancy grid.
4. Channel-to-Height (C2H) Transformation: The core innovation. The 2D BEV feature map of shape (B, C*Z, H_bev, W_bev) is reshaped into a 3D volume (B, C, Z, H_bev, W_bev) by splitting the channel dimension into semantic channels and height bins. This is a zero-cost reshape operation -- no learned parameters, no computation. The insight is that a sufficiently expressive 2D BEV encoder can learn to encode height-specific information in different channel groups.
5. Occupancy Head: A lightweight 1x1 convolution (or linear layer) that maps the C-dimensional features at each voxel to semantic class logits, producing the final occupancy prediction of shape (B, num_classes, Z, H_bev, W_bev).
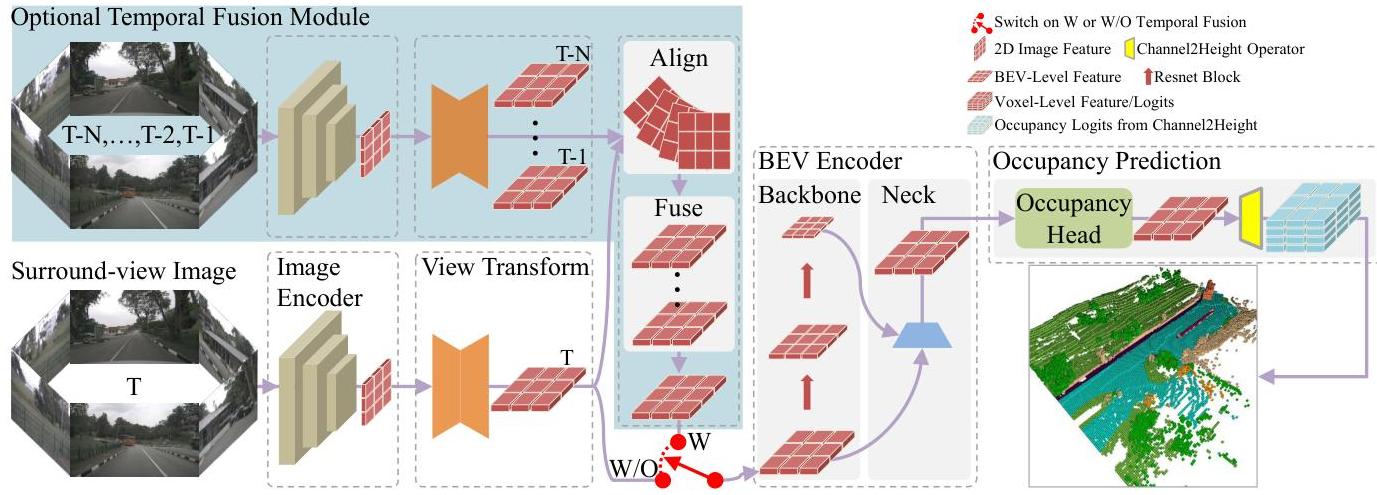
Temporal Fusion (FlashOcc-T): For the temporal variant, BEV features from multiple frames are aligned to the current ego frame using known ego-motion transforms (rotation + translation in 2D BEV space) and concatenated or fused before being passed through the BEV encoder. This adds multi-frame context while keeping all processing in 2D.
The key equation is simply a reshape:
F_3D[b, c, z, h, w] = F_BEV[b, c * Z + z, h, w]
where F_BEV is the 2D BEV feature of shape (B, C*Z, H, W) and F_3D is the resulting 3D volume of shape (B, C, Z, H, W).
Results
FlashOcc demonstrates that replacing voxel-level 3D processing with C2H can preserve or improve occupancy quality while cutting the cost of the occupancy head:
| Method | Backbone | 3D Processing | mIoU |
|---|---|---|---|
| BEVDetOcc | Swin-B | 3D voxel processing | 36.1 |
| FO(BEVDetOcc) | Swin-B | C2H (2D only) | 37.8 |
| UniOcc | Swin-B | 3D voxel processing | 39.2 |
| FO(UniOcc) | Swin-B | C2H (2D only) | 39.0 |
| FBOcc | ResNet-101 | 3D voxel processing | 37.2 |
| FO(FBOcc) | ResNet-101 | C2H (2D only) | 37.3 |
Key findings:
- Plug-and-play quality: On the paper's direct plug-in tests, FlashOcc improves BEVDetOcc from 36.1 to 37.8 mIoU, keeps UniOcc roughly unchanged (39.2 to 39.0), and slightly improves FBOcc from 37.2 to 37.3.
- Resource savings: For the BEVDetOcc setting without temporal fusion, the occupancy head latency drops from 7.5 ms to 3.1 ms, inference memory drops from 398 MiB to 124 MiB, and training duration drops from 64 to 32 GPU-hours.
- End-to-end runtime: In the same BEVDetOcc setting, total TensorRT FPS on a single RTX 3090 rises from 92.1 to 152.7 without temporal fusion; with temporal fusion, it rises from 15.5 to 17.3.
- Temporal behavior is baseline-dependent: Temporal fusion still helps FlashOcc variants, but the gains are not uniform across all backbones and do not support a blanket claim that the temporal version always matches or exceeds heavier 3D baselines.
Ablation Results
Key ablations demonstrate:
- The BEV encoder capacity (number of channels) is critical -- the 2D encoder must have enough channels (C * Z) to encode height information.
- Temporal fusion helps both the voxel baselines and FlashOcc variants, but the exact gain depends on the underlying method.
- The C2H substitution cuts resource use sharply while preserving occupancy quality better than a naive 2D-to-3D replacement would.
Limitations & Open Questions
- Accuracy ceiling: While efficient, fully 2D processing may have an inherent accuracy ceiling compared to methods that explicitly reason in 3D, particularly for fine-grained height distinctions (e.g., distinguishing overhanging signs from ground-level barriers)
- Channel capacity: The BEV encoder must allocate
C * Zchannels to represent all height bins, which can become expensive for fine vertical resolution. The method works best with moderate height discretization - Semantic-height disentanglement: The C2H reshape assumes that the network naturally learns to separate height information across channel groups, but there is no explicit supervision to ensure this factorization
- Limited to BEV-based pipelines: Requires an existing BEV representation as input, so it cannot be applied to methods that skip BEV (e.g., direct 3D query-based approaches like GaussianFormer)
Connections
Related papers in the wiki:
- Lift Splat Shoot Encoding Images From Arbitrary Camera Rigs By Implicitly Unprojecting To 3D -- LSS provides the foundational lift-splat view transformation that FlashOcc builds upon for generating BEV features
- Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers -- Alternative query-based BEV generation; FlashOcc's C2H plugin is compatible with BEVFormer-style view transformers
- Drive Occworld Driving In The Occupancy World -- Uses occupancy prediction for world modeling and planning; FlashOcc could provide efficient occupancy inputs to such systems
- Gaussianformer 2 Probabilistic Gaussian Superposition For Efficient 3D Occupancy Prediction -- Alternative efficient occupancy approach using sparse Gaussians instead of dense voxels
- Gaussianlss Toward Real World Bev Perception With Depth Uncertainty Via Gaussian Splatting -- Complementary work on efficient BEV perception via Gaussian splatting
- Perception -- FlashOcc contributes to the efficient occupancy prediction trend within the broader perception landscape