SparseOcc: Fully Sparse 3D Occupancy Prediction
Overview
3D occupancy prediction has become a critical perception paradigm for autonomous driving, but existing methods process dense 3D volumes even though over 90% of voxels in typical driving scenes are empty. This results in enormous computational waste -- dense methods like SurroundOcc and OccFormer run at only 2-3 FPS, far below real-time requirements. SparseOcc addresses this fundamental inefficiency by introducing the first fully sparse architecture for vision-centric 3D occupancy prediction, operating only on the small fraction of voxels that actually matter.
Beyond architectural efficiency, SparseOcc makes an equally important contribution on the evaluation side. The standard voxel-level mIoU metric has critical flaws: it applies inconsistent depth penalties (errors at nearby surfaces are penalized more than distant ones due to voxel discretization) and can be "gamed" by predicting artificially thick surfaces that inflate intersection counts without improving geometric accuracy. SparseOcc proposes RayIoU, a new metric that emulates LiDAR ray-casting behavior by shooting query rays into the predicted occupancy volume and measuring agreement with ground truth at the ray-surface intersection points. RayIoU became the official evaluation metric for the CVPR 2024 Occupancy Challenge, establishing it as the community standard.
SparseOcc achieves 34.0 RayIoU at 17.3 FPS with 7 history frames -- significantly faster than FB-Occ (33.5 RayIoU, 10.3 FPS) and BEVFormer (3.0 FPS) while maintaining competitive or superior accuracy. With 15 frames, performance reaches 35.1 RayIoU while maintaining real-time capability.
Key Contributions
- Fully sparse two-stage architecture: A Sparse Voxel Decoder reconstructs sparse 3D geometry through coarse-to-fine pruning, retaining only 5-7.5% of voxels, followed by a Mask Transformer Decoder for semantic and instance prediction
- RayIoU evaluation metric: A ray-casting-based metric that fixes the inconsistent depth penalties and metric gaming vulnerabilities of voxel-level mIoU; adopted as the official metric for the CVPR 2024 Occupancy Challenge
- Mask-guided sparse sampling: Efficient 3D-2D interaction through sparse sampling guided by predicted masks, avoiding dense cross-attention over the full volume
- Real-time performance: 17.3 FPS with competitive accuracy, demonstrating that sparse processing can achieve both speed and quality
Architecture / Method
Multi-Camera Images (6x)
│
▼
┌──────────────────┐
│ 2D Backbone │
│ (Multi-View) │
└────────┬─────────┘
│
▼
┌───────────────────────────────────────────────────┐
│ Stage 1: Sparse Voxel Decoder │
│ │
│ Dense Voxel Candidates │
│ │ │
│ ▼ Layer 1: predict occupancy, prune low │
│ ┌─────────┐ │
│ │ Prune │──► ~50% remain │
│ └────┬────┘ │
│ ▼ Layer 2: predict occupancy, prune low │
│ ┌─────────┐ │
│ │ Prune │──► ~20% remain │
│ └────┬────┘ │
│ ▼ Layer N: final pruning │
│ ┌─────────┐ │
│ │ Prune │──► 5-7.5% remain (32K-48K voxels) │
│ └────┬────┘ │
└───────┼───────────────────────────────────────────┘
│ sparse voxel features
▼
┌───────────────────────────────────────────────────┐
│ Stage 2: Mask Transformer Decoder │
│ │
│ Learnable queries ──► mask-guided sparse sampling│
│ │ (attend only to voxels │
│ ▼ within predicted mask) │
│ ┌──────────────────┐ │
│ │ Semantic Classes │ │
│ │ + Instance Masks │ │
│ └──────────────────┘ │
└───────────────────────────────────────────────────┘
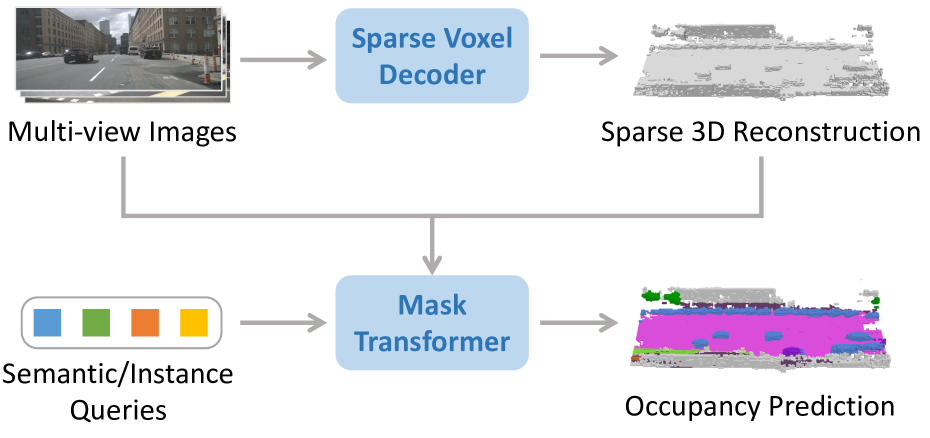
SparseOcc consists of two main stages:
Stage 1: Sparse Voxel Decoder. Starting from multi-camera image features, the decoder reconstructs sparse 3D geometry through a coarse-to-fine pruning strategy. An initial dense set of voxel candidates is progressively pruned across multiple decoder layers, with each layer predicting occupancy scores and discarding low-confidence voxels. After pruning, only 5-7.5% of the original voxels (typically 32,000-48,000 out of the full volume) are retained, dramatically reducing computation in subsequent stages. The retained voxels represent the occupied surfaces and objects in the scene.
Stage 2: Mask Transformer Decoder. The surviving sparse voxels are processed by a Mask2Former-style transformer decoder that predicts semantic classes and instance masks. Rather than applying dense cross-attention between queries and all voxel features, the decoder uses mask-guided sparse sampling: each query attends only to voxels within its predicted mask region, making the 3D-2D interaction efficient even with large numbers of queries. This produces both semantic occupancy labels and instance-level groupings.
Temporal fusion. Multi-frame history is incorporated by warping and aggregating sparse voxel features from previous timesteps using ego-motion compensation, providing velocity and temporal context without requiring dense 4D volumes.
Training. The model is trained with a combination of binary cross-entropy (BCE) for voxel occupancy at each pruning stage (with class weighting for imbalance), and focal loss for semantic classification plus dice loss and BCE mask loss for mask prediction in the Mask Transformer stage. Hungarian matching associates ground-truth segments with predictions. The coarse-to-fine pruning is supervised at multiple scales to ensure geometry is preserved through progressive refinement.
RayIoU Metric
The paper's most lasting contribution may be the RayIoU metric. Standard mIoU computes voxel-level intersection-over-union, which has two critical problems:
- Inconsistent depth penalty: Due to voxel discretization, a 1-voxel surface prediction error at 5m range covers a much larger angular extent than the same error at 50m, creating an implicit bias toward nearby accuracy.
- Metric gaming: Methods can predict artificially thick surfaces (inflating occupied voxels around true surfaces) to increase intersection counts, improving mIoU without any real geometric improvement.
RayIoU addresses both issues by emulating LiDAR behavior: query rays are cast from the sensor origin through the predicted and ground-truth occupancy volumes. For each ray, the first surface intersection point is recorded. IoU is then computed based on whether predicted and ground-truth rays agree on surface location (within a distance threshold). This provides uniform evaluation across all depths and is immune to surface-thickening tricks.
Ablation studies demonstrate that training strategies which inflate traditional mIoU (e.g., thicker surface predictions) actually degrade RayIoU scores, confirming that RayIoU better reflects true geometric accuracy.
Results
| Method | RayIoU | FPS | Frames |
|---|---|---|---|
| SparseOcc | 34.0 | 17.3 | 7 |
| SparseOcc | 35.1 | 12.5 | 15 |
| FB-Occ | 33.5 | 10.3 | -- |
| BEVFormer | -- | 3.0 | -- |
Key experimental findings:
- Optimal sparsity: Ablation studies show best performance with 32,000-48,000 retained voxels (5-7.5% of the dense volume), confirming that aggressive pruning does not sacrifice accuracy
- Speed-accuracy Pareto: SparseOcc significantly advances the speed-accuracy frontier, being the first occupancy method to achieve real-time inference with competitive accuracy
- RayIoU vs mIoU divergence: Methods that score well on mIoU through surface inflation score poorly on RayIoU, validating the new metric's ability to detect gaming
- CVPR 2024 Occ Challenge: RayIoU was adopted as the official metric, and SparseOcc-based approaches won the challenge
Limitations & Open Questions
- LiDAR ground truth dependency: Like most occupancy methods, relies on aggregated LiDAR scans for supervision; self-supervised alternatives (GaussianOcc, GaussTR) may reduce this dependency
- Static scene assumption in pruning: The coarse-to-fine pruning strategy may struggle with fast-moving objects that occupy different voxels across frames
- RayIoU threshold sensitivity: The metric depends on a distance threshold for matching predicted and ground-truth ray intersections; the sensitivity to this threshold choice deserves further study
- Instance-level evaluation: RayIoU primarily evaluates semantic occupancy; extending ray-based evaluation to instance-level panoptic occupancy remains open
Connections
Related papers in the wiki:
- Surroundocc Multi Camera 3D Occupancy Prediction For Autonomous Driving -- foundational dense occupancy method that SparseOcc explicitly improves upon in efficiency
- Occformer Dual Path Transformer For Vision Based 3D Semantic Occupancy Prediction -- dual-path transformer baseline; SparseOcc replaces its dense processing with sparse pruning
- Flashocc Fast And Memory Efficient Occupancy Prediction Via Channel To Height Plugin -- alternative efficient occupancy approach using 2D-only processing; complementary efficiency strategy
- Gaussianformer Scene As Gaussians For Vision Based 3D Semantic Occupancy Prediction -- another sparse occupancy approach using Gaussians instead of pruned voxels (ECCV 2024)
- Gaussianformer 2 Probabilistic Gaussian Superposition For Efficient 3D Occupancy Prediction -- probabilistic Gaussian extension; shares the sparse occupancy philosophy
- Sparsedrive End To End Autonomous Driving Via Sparse Scene Representation -- extends sparse representations to full end-to-end driving beyond perception
- Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers -- BEV baseline whose slow speed (~3 FPS) motivates SparseOcc's sparse approach
- Fb Bev Bev Representation From Forward Backward View Transformations -- FB-Occ variant used as direct comparison in results
- Perception -- broader context on occupancy prediction and BEV representations