SurroundOcc: Multi-camera 3D Occupancy Prediction for Autonomous Driving
Overview
SurroundOcc addresses the problem of dense 3D semantic occupancy prediction from multi-camera images for autonomous driving. Unlike 3D object detection, which represents the scene as a set of bounding boxes and struggles with irregular objects and novel classes, occupancy prediction assigns a semantic label to every voxel in a discretized 3D volume around the ego vehicle. This is a strictly more expressive representation: it captures arbitrary geometry (construction debris, fallen trees, curbs) that box-based methods miss, making it directly useful for safe motion planning.
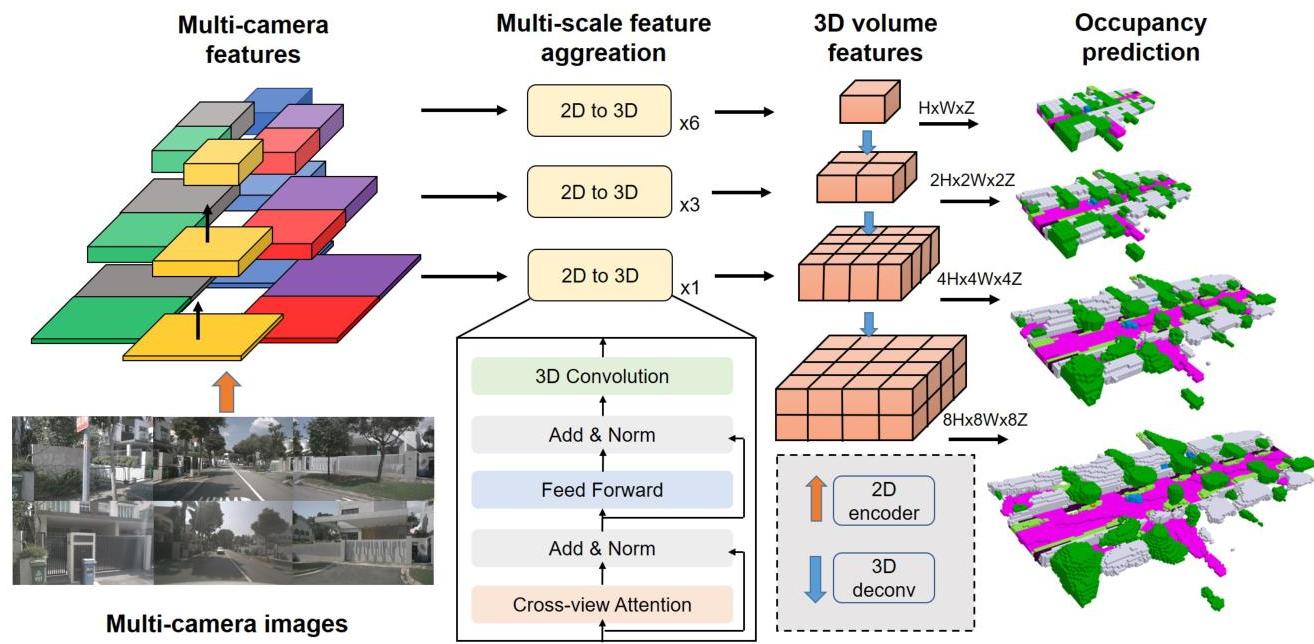
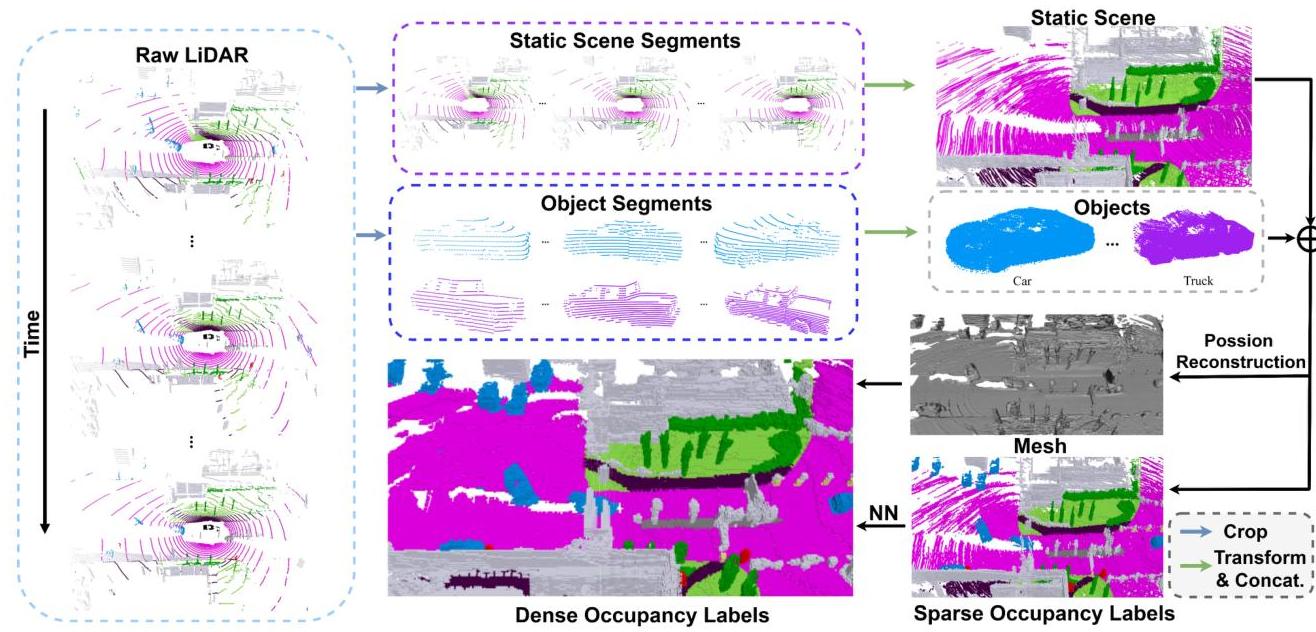
The core approach combines three ideas: (1) a multi-scale 2D-to-3D feature lifting mechanism using spatial cross-attention between 3D volume queries and multi-view image features, (2) a coarse-to-fine 3D U-Net decoder that progressively upsamples voxel features from low to high resolution with multi-scale supervision at each level, and (3) an automated dense ground truth generation pipeline that circumvents the prohibitive cost of manual 3D voxel annotation by aggregating multi-frame LiDAR sweeps, applying Poisson surface reconstruction, and propagating semantic labels via nearest-neighbor lookup.
SurroundOcc achieved state-of-the-art results on both nuScenes and SemanticKITTI occupancy benchmarks at the time of publication, significantly outperforming prior methods like MonoScene and TPVFormer. The dense ground truth pipeline it introduced became an important contribution in its own right, enabling subsequent occupancy prediction research. SurroundOcc is widely regarded as one of the foundational papers that established 3D occupancy prediction as a core perception task for camera-based autonomous driving.
Key Contributions
- Multi-scale 2D-to-3D spatial attention: Lifts multi-view 2D image features into a 3D volume using cross-attention between learnable 3D volume queries and multi-scale image features, avoiding explicit depth estimation while preserving geometric structure
- Coarse-to-fine 3D decoder with multi-scale supervision: A 3D U-Net decoder progressively upsamples voxel features (e.g., from 25x25x2 to 200x200x16), with cross-entropy and scene-class affinity supervision applied at each resolution level to provide dense gradient signal
- Dense occupancy ground truth generation pipeline: Automatically generates voxel-level annotations by (1) aggregating multi-frame LiDAR point clouds across consecutive sweeps, (2) applying Poisson surface reconstruction to fill in sparse regions, and (3) propagating semantic labels from annotated points to reconstructed surfaces via nearest-neighbor assignment
- Strong benchmark results: Achieved SOTA on nuScenes occupancy and SemanticKITTI, demonstrating that camera-only systems can produce strong dense 3D scene understanding
Architecture / Method
Multi-Camera Images (N views)
│
▼
┌──────────────────────┐
│ ResNet-101 + FPN │
│ (1/8, 1/16, 1/32) │
└────────┬─────────────┘
│ multi-scale 2D features
▼
┌────────────────────────────────────────────────┐
│ 2D-to-3D Spatial Cross-Attention │
│ │
│ 3D Volume Queries ──► project ref pts to imgs │
│ │ deformable cross-attn │
│ ▼ │
│ Coarse 3D Volume (25x25x2) │
└────────┬───────────────────────────────────────┘
│
▼
┌────────────────────────────────────────────────┐
│ Coarse-to-Fine 3D U-Net Decoder │
│ │
│ ┌─────────┐ ┌─────────┐ ┌─────────────┐ │
│ │ Encoder │──►│ Decoder │──►│ Upsample │ │
│ │ (3D conv│ │ (3D │ │ stages + │ │
│ │ + pool)│ │ deconv │ │ skip conns │ │
│ └─────────┘ │ + skip)│ └──────┬──────┘ │
│ └─────────┘ │ │
│ ▼ │
│ Multi-Scale Supervision at each level: │
│ ├── Scene-class affinity loss │
│ └── Cross-entropy loss │
│ │
│ Final output: 200x200x16 semantic voxels │
└────────────────────────────────────────────────┘
Image Backbone and Multi-Scale Features
SurroundOcc uses a standard image backbone (e.g., ResNet-101 with FPN) to extract multi-scale 2D features from each of the N surrounding cameras. The FPN produces feature maps at multiple resolutions (1/8, 1/16, 1/32), which are used to construct the 3D volume at different scales.
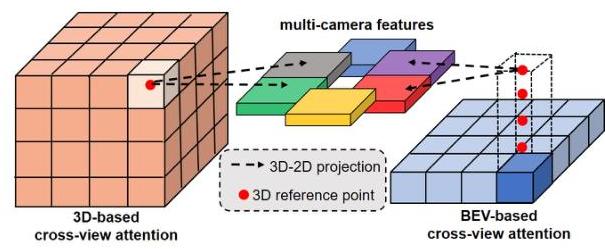
2D-to-3D Spatial Cross-Attention
The 2D-to-3D transformation uses a spatial cross-attention mechanism inspired by BEVFormer but extended to full 3D volumes rather than 2D BEV planes. Learnable 3D volume queries are defined on a coarse voxel grid. Each query is associated with a set of 3D reference points, which are projected onto the image planes of all cameras using known intrinsics and extrinsics. Deformable cross-attention aggregates features from the relevant camera views at these projected locations, producing an initial coarse 3D volume representation.
Coarse-to-Fine 3D U-Net Decoder
The initial coarse 3D volume is progressively refined through a 3D U-Net architecture with skip connections:
- Encoder: Processes the initial volume with 3D convolutions to capture context at multiple scales
- Decoder: Upsamples through multiple stages using 3D transposed convolutions and skip connections, producing increasingly fine-grained voxel predictions
- Multi-scale heads: At each decoder level, a classification head predicts per-voxel semantic labels, and supervision is applied at every scale
The multi-scale supervision is critical -- it provides dense gradients throughout the network rather than only at the final high-resolution output. The losses used include:
- Scene-class affinity loss: Encourages voxels of the same class to have similar features while pushing apart features of different classes, applied in a pairwise manner across neighboring voxels
- Cross-entropy loss: Standard per-voxel classification loss
Dense Ground Truth Generation
A major practical contribution is the pipeline for generating dense occupancy labels without manual voxel annotation:
- Multi-frame LiDAR aggregation: Accumulate LiDAR sweeps from multiple consecutive frames, transforming all points into world coordinates; static scene and dynamic object points are aggregated separately across sequences
- Poisson surface reconstruction: Apply Poisson reconstruction to the aggregated point cloud to generate a continuous surface mesh, filling in gaps between sparse LiDAR returns
- Voxelization: Discretize the reconstructed surface into a regular voxel grid at the target resolution
- Semantic label propagation: For each filled voxel, assign the semantic label of the nearest annotated LiDAR point using k-nearest-neighbor lookup
This pipeline produces much denser ground truth than single-frame LiDAR annotations (which are inherently sparse), enabling meaningful supervision for fine-grained occupancy prediction.
Results
nuScenes Occupancy
| Method | Input | SSC mIoU |
|---|---|---|
| MonoScene | Camera | 7.31 |
| TPVFormer | Camera | 11.66 |
| SurroundOcc | Camera | 20.30 |
SurroundOcc dramatically outperformed prior camera-based methods, substantially improving over both MonoScene and TPVFormer on nuScenes semantic occupancy.
SemanticKITTI
SurroundOcc also demonstrated strong performance on SemanticKITTI's semantic scene completion benchmark, achieving competitive results with methods that use LiDAR input while relying only on cameras.
Key Ablations
- Multi-scale supervision: Removing multi-scale loss and only supervising at the final resolution drops mIoU significantly (~3-4%), confirming the importance of dense intermediate supervision
- Dense vs. sparse ground truth: Training with the dense Poisson-reconstructed GT substantially outperforms training with sparse single-frame LiDAR GT, validating the ground truth pipeline
- Volume resolution: Higher-resolution volumes (200x200x16) meaningfully outperform coarser grids, though with increased compute cost
Limitations & Open Questions
- Compute cost: The full 3D volume representation is memory-intensive, especially at high resolutions. Subsequent work (GaussianFormer, OccMamba) explored sparse representations to address this
- Static scene assumption: The ground truth pipeline aggregates multiple frames assuming a static world; dynamic objects can cause artifacts in the reconstructed surfaces
- Single-frame inference: SurroundOcc processes each frame independently without temporal fusion, missing motion cues that could improve prediction quality
- Long-range degradation: Like other camera-based methods, accuracy drops at longer ranges where depth ambiguity increases
- Occupancy vs. planning utility: The paper evaluates occupancy quality (mIoU) but does not demonstrate downstream planning improvements -- the link between occupancy quality and driving safety remains an open question
Connections
Related papers in the wiki:
- Lift Splat Shoot Encoding Images From Arbitrary Camera Rigs By Implicitly Unprojecting To 3D -- LSS introduced the lift-splat paradigm for multi-camera BEV; SurroundOcc extends this idea to full 3D volumes
- Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers -- BEVFormer's spatial cross-attention with 3D reference points directly inspires SurroundOcc's 2D-to-3D attention mechanism
- Nuscenes A Multimodal Dataset For Autonomous Driving -- Primary evaluation benchmark
- Planning Oriented Autonomous Driving -- UniAD uses perception outputs including occupancy for end-to-end driving
- Drive Occworld Driving In The Occupancy World -- Extends occupancy prediction to 4D forecasting for planning, building on the representation SurroundOcc established
- Gaussianformer Scene As Gaussians For Vision Based 3D Semantic Occupancy Prediction -- Replaces SurroundOcc's dense voxel representation with sparse 3D Gaussians for 5-6x memory reduction
- Gaussianformer 2 Probabilistic Gaussian Superposition For Efficient 3D Occupancy Prediction -- Further improves Gaussian occupancy efficiency over both SurroundOcc and GaussianFormer
- Occmamba Semantic Occupancy Prediction With State Space Models -- Replaces transformer/CNN occupancy decoder with linear-complexity Mamba, outperforming SurroundOcc
- Gaussianworld Gaussian World Model For Streaming 3D Occupancy Prediction -- Extends occupancy to streaming temporal prediction using Gaussian world models
- Perception -- SurroundOcc is a foundational paper in the occupancy prediction paradigm within driving perception
- Autonomous Driving -- Core perception component for camera-based autonomous driving systems