SelfOcc: Self-Supervised Vision-Based 3D Occupancy Prediction
Overview
SelfOcc (Huang et al., Tsinghua University, CVPR 2024) introduces the first self-supervised framework for vision-based 3D occupancy prediction that works with multi-camera surround-view setups. The core problem is that supervised occupancy methods require expensive 3D voxel-level annotations (or LiDAR-derived dense ground truth), which are costly and difficult to scale. SelfOcc eliminates this requirement by learning 3D occupancy from unlabeled video sequences using only photometric self-supervision.
The key insight is to lift 2D image features into explicit 3D representations (BEV or TPV), encode them as Signed Distance Fields (SDFs) via a lightweight MLP decoder, and then use differentiable volume rendering (following the NeuS formulation) to synthesize novel views. The synthesized images serve as the self-supervision signal -- if the 3D representation is accurate, rendered views should match real camera observations. Critically, SelfOcc introduces an MVS-embedded depth learning strategy that samples multiple depth proposals along each camera ray, expanding the receptive field beyond traditional single-depth photometric losses and addressing a core convergence limitation in self-supervised depth learning.
SelfOcc achieves 45.01% geometric IoU on the nuScenes surround-view occupancy benchmark, surpassing LiDAR-supervised TPVFormer (17.20% IoU) and outperforming supervised mIoU baselines. On SemanticKITTI monocular occupancy, it sets a new self-supervised state of the art at 21.97% mIoU -- a 58.7% improvement over the previous best (13.84%). This demonstrates that self-supervised methods can not only close the gap with supervised approaches but actually surpass them when the supervision quality of the labeled data is limited.
Key Contributions
- First self-supervised surround-view occupancy: Demonstrates that reasonable 3D occupancy can be learned from multi-camera video without any 3D ground truth annotations, opening occupancy prediction to large-scale unlabeled driving datasets
- SDF-based volume rendering for occupancy: Encodes the 3D scene as a signed distance field and uses differentiable NeuS-style volume rendering to project back to 2D, creating a clean self-supervision loop between 3D representation and 2D observations
- MVS-embedded depth learning: Samples multiple depth proposals along camera rays (inspired by multi-view stereo), expanding the effective receptive field during training and significantly improving convergence compared to single-depth photometric losses
- Strong results without 3D annotations: Surpasses supervised MonoScene on nuScenes geometric IoU and achieves 58.7% improvement over prior self-supervised SOTA on SemanticKITTI
Architecture / Method
┌──────────────────────────────────────────────────────────────┐
│ SelfOcc Pipeline │
├──────────────────────────────────────────────────────────────┤
│ │
│ ┌───────────────────┐ │
│ │ Multi-Camera │ │
│ │ Surround Images │ │
│ └────────┬──────────┘ │
│ ▼ │
│ ┌───────────────────┐ │
│ │ 2D Backbone │ │
│ │ (ResNet-50) │ │
│ └────────┬──────────┘ │
│ ▼ │
│ ┌───────────────────────────────────────┐ │
│ │ 2D-to-3D Feature Lifting │ │
│ │ (Deformable Cross-Attention, │ │
│ │ BEVFormer/TPVFormer style) │ │
│ └────────┬──────────────────────────────┘ │
│ ▼ │
│ ┌───────────────────────────────────────┐ │
│ │ 3D Feature Volume (BEV or TPV) │ │
│ └────────┬──────────────────────────────┘ │
│ ▼ │
│ ┌───────────────────────────────────────┐ │
│ │ SDF MLP Decoder │ │
│ │ query point ──► signed distance + color│ │
│ └────────┬──────────────────────────────┘ │
│ │ │
│ ┌─────┴──────┐ │
│ ▼ ▼ │
│ ┌────────┐ ┌───────────────────────────────────────────┐ │
│ │Occupancy│ │ Differentiable Volume Rendering (NeuS) │ │
│ │Output │ │ SDF ──► opacity weights ──► rendered img │ │
│ │(SDF < 0 │ └──────────────────┬────────────────────────┘ │
│ │=occupied)│ ▼ │
│ └─────────┘ ┌──────────────────────────────────────────┐ │
│ │ Self-Supervision: L1 + SSIM photometric │ │
│ │ + Eikonal + Hessian + Sparsity losses │ │
│ │ + MVS-embedded multi-depth proposals │ │
│ └──────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────┘
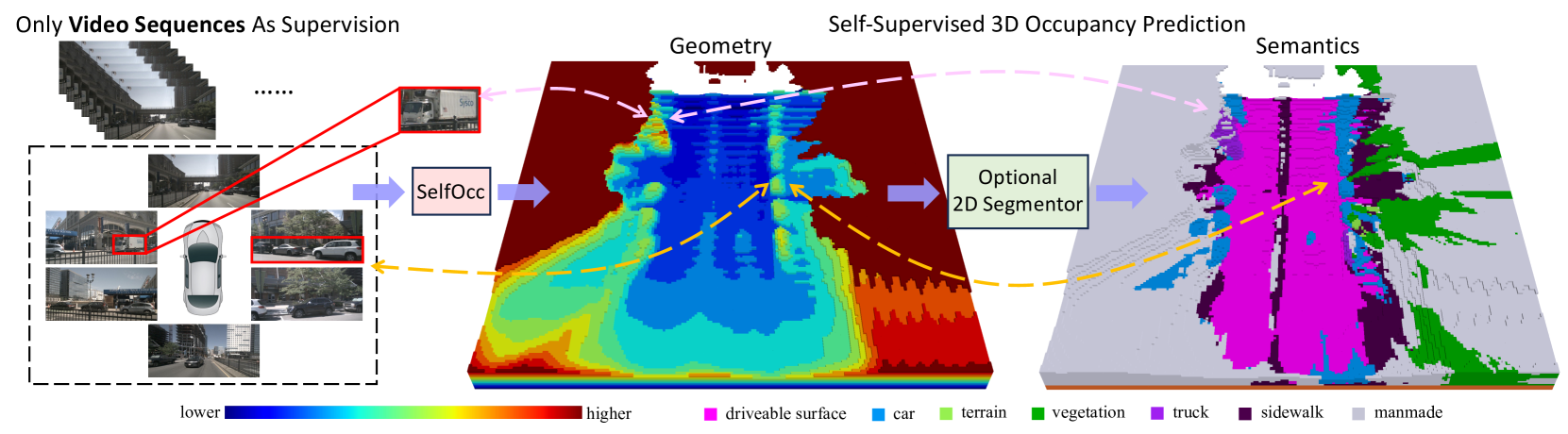
SelfOcc follows a three-stage pipeline: (1) 2D-to-3D feature lifting, (2) SDF field encoding, and (3) differentiable volume rendering for self-supervision.
2D-to-3D Feature Lifting. Multi-camera images are processed by a 2D backbone (e.g., ResNet-50) to extract multi-scale features. These are then lifted into a 3D representation using deformable cross-attention, following the BEVFormer or TPVFormer architecture. The result is a dense 3D feature volume (or tri-perspective view) representing the scene around the ego vehicle.
SDF Field Encoding. A lightweight MLP decoder takes the 3D features at any query point and predicts a signed distance value and an appearance feature. The SDF implicitly defines the occupancy: regions where the SDF is negative are inside surfaces (occupied), and regions where it is positive are free space. This continuous representation is more flexible than discrete voxel grids and naturally handles arbitrary geometry.
Differentiable Volume Rendering. Following the NeuS formulation, SelfOcc converts the SDF values along each camera ray into opacity weights using the logistic density function. Colors/features are accumulated along rays via volume rendering to produce synthetic images. The photometric loss between rendered and real images drives the entire system.
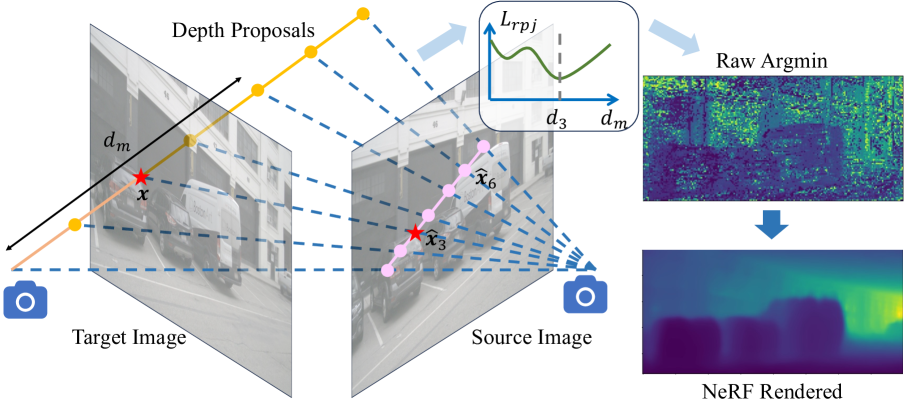
MVS-Embedded Depth Learning. Instead of predicting a single depth per pixel (as in standard self-supervised depth estimation), SelfOcc samples multiple depth proposals along each ray and evaluates the photometric consistency of each. This multi-view stereo-inspired strategy provides a wider receptive field during training, helping the network avoid local minima and converge faster. The multiple depth hypotheses are combined using a soft argmin operation.
Regularization Losses. The training objective combines: (1) photometric reconstruction loss (L1 + SSIM between rendered and real images), (2) Eikonal loss (enforcing unit-norm SDF gradients for geometric regularity), (3) Hessian loss (smoothness of the SDF field), and (4) sparsity loss (encouraging the SDF to be decisively positive or negative, reducing ambiguous regions).
Results

nuScenes Surround-View Occupancy (Geometric IoU)
| Method | Supervision | IoU (%) | mIoU (%) |
|---|---|---|---|
| MonoScene | 3D supervised | — | 6.06 |
| TPVFormer | LiDAR supervised | 17.20 | 13.57 |
| SelfOcc (BEV) | Self-supervised | 44.33 | 6.76 |
| SelfOcc (TPV) | Self-supervised | 45.01 | 9.30 |
SemanticKITTI Monocular Occupancy (IoU)
| Method | Supervision | IoU (%) |
|---|---|---|
| MonoScene | 3D supervised | 13.53 |
| SceneRF (prev. SS-SOTA) | Self-supervised | 13.84 |
| SelfOcc (TPV) | Self-supervised | 21.97 |
The results are striking: SelfOcc's self-supervised approach significantly outperforms earlier supervised methods, primarily because the self-supervised objective leverages the rich photometric signal in video data rather than depending on potentially sparse or noisy LiDAR-derived ground truth. The TPV representation outperforms the BEV representation on nuScenes, indicating that the tri-perspective view captures more fine-grained vertical structure.

Limitations & Open Questions
- Semantic occupancy gap: While geometric occupancy is strong, semantic occupancy (predicting what class occupies each voxel) is harder to learn purely self-supervised -- the photometric signal does not directly encode object categories
- Dynamic objects: The SDF + volume rendering formulation assumes a mostly static scene; fast-moving objects may create artifacts in the photometric loss
- Computational cost: Differentiable volume rendering along many rays is expensive during training, though inference only requires the 3D encoder + SDF MLP (no rendering needed)
- Scale ambiguity: Self-supervised depth and occupancy can suffer from scale drift without absolute depth cues; the multi-camera setup partially mitigates this via known extrinsics
- Can self-supervised occupancy replace supervised methods at scale? SelfOcc shows promise but the semantic gap remains -- subsequent work like GaussianOcc and GaussTR explores complementary paths to closing it
Connections
Related papers in the wiki: - Surroundocc Multi Camera 3D Occupancy Prediction For Autonomous Driving — foundational supervised occupancy method; SelfOcc shows self-supervision can surpass early supervised approaches - Occformer Dual Path Transformer For Vision Based 3D Semantic Occupancy Prediction — efficient dual-path transformer for supervised occupancy; complementary architectural approach - Gaussianocc Fully Self Supervised 3D Occupancy Estimation With Gaussian Splatting — extends the self-supervised occupancy paradigm with Gaussian splatting, eliminating even the need for GT poses - Gausstr Foundation Model Aligned Gaussian Transformer For Self Supervised 3D — alternative self-supervised path using foundation model alignment instead of photometric loss - Gaussrender Learning 3D Occupancy With Gaussian Rendering — plug-and-play Gaussian rendering loss for 3D-2D consistency, shares the rendering-as-supervision philosophy - Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers — SelfOcc uses BEVFormer-style deformable cross-attention for 2D-to-3D lifting - Lift Splat Shoot Encoding Images From Arbitrary Camera Rigs By Implicitly Unprojecting To 3D — foundational lift-splat paradigm that SelfOcc builds upon for multi-camera feature lifting - Gaussianformer Scene As Gaussians For Vision Based 3D Semantic Occupancy Prediction — sparse Gaussian alternative to dense voxel occupancy representation - Perception — broader context on occupancy prediction as a perception paradigm