GaussianOcc: Fully Self-supervised and Efficient 3D Occupancy Estimation with Gaussian Splatting
:page_facing_up: Read on arXiv
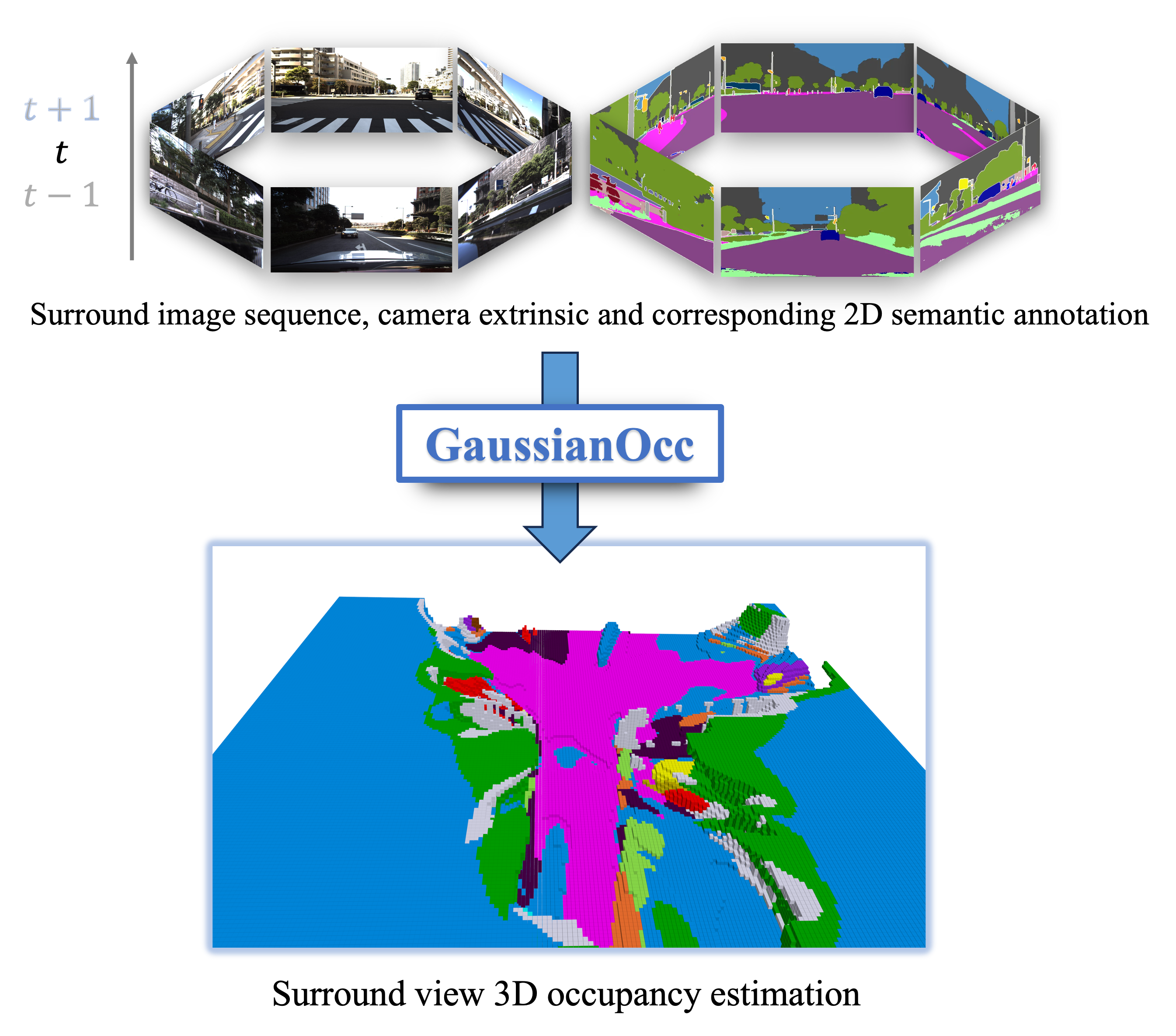
Overview
GaussianOcc by Gan et al. (University of Tokyo / RIKEN / South China University of Technology / SIAT-CAS) is a systematic method that applies Gaussian splatting in two complementary ways to achieve fully self-supervised and efficient 3D occupancy estimation from surround-view cameras. The core problem is that prior self-supervised 3D occupancy methods still require ground-truth 6D sensor poses during training, and they rely on computationally expensive volume rendering for learning voxel representations from 2D signals. GaussianOcc eliminates both limitations.
The method enables fully self-supervised training (no ground-truth pose, no 3D annotations) while being 2.7x faster in training and 5x faster in rendering compared to volume-rendering baselines, with competitive or superior occupancy accuracy on the nuScenes-Occupancy benchmark.
Key Contributions
- Gaussian Splatting for Projection (GSP): Replaces ground-truth pose supervision with a learned module that provides accurate scale information for fully self-supervised training via adjacent-view projection using Gaussian splatting
- Gaussian Splatting from Voxel space (GSV): Treats 3D voxel vertices as Gaussian primitives for fast differentiable rendering, replacing slow volume rendering for occupancy representation learning from 2D depth/semantic signals
- Two-stage self-supervised pipeline: Stage 1 learns scale-aware poses via GSP; Stage 2 uses GSV for efficient voxel-to-image rendering supervision
- Fully self-supervised 3D occupancy: First method to achieve competitive 3D occupancy estimation without any ground-truth poses or 3D annotations
Architecture / Method
┌──────────────────────────────────────────────────────────────────┐
│ GaussianOcc Two-Stage Pipeline │
│ │
│ ╔═══════════════════════════════════════════════════════════╗ │
│ ║ Stage 1: Pose Learning (GSP) ║ │
│ ║ ║ │
│ ║ ┌──────────┐ ┌──────────┐ ┌───────────────────┐ ║ │
│ ║ │ Multi-cam│──►│ Shared │──►│ Depth Prediction │ ║ │
│ ║ │ Images │ │ Encoder │ │ + Lift to 3D │ ║ │
│ ║ └──────────┘ └──────────┘ └─────────┬─────────┘ ║ │
│ ║ │ ║ │
│ ║ 3D points as Gaussians ║ │
│ ║ │ ║ │
│ ║ ┌──────────▼──────────┐ ║ │
│ ║ │ Splat to adjacent │ ║ │
│ ║ │ camera views │ ║ │
│ ║ └──────────┬──────────┘ ║ │
│ ║ │ ║ │
│ ║ Photometric consistency ║ │
│ ║ loss ──► learn poses ║ │
│ ╚═══════════════════════════════════════════════════════════╝ │
│ │
│ ╔═══════════════════════════════════════════════════════════╗ │
│ ║ Stage 2: Occupancy Learning (GSV) ║ │
│ ║ ║ │
│ ║ ┌──────────┐ ┌──────────┐ ┌───────────────────┐ ║ │
│ ║ │ Multi-cam│──►│ Encoder │──►│ 3D Voxel Grid │ ║ │
│ ║ │ Images │ │ │ │ Construction │ ║ │
│ ║ └──────────┘ └──────────┘ └─────────┬─────────┘ ║ │
│ ║ │ ║ │
│ ║ Voxel vertices as Gaussians ║ │
│ ║ (with learned opacity) ║ │
│ ║ │ ║ │
│ ║ ┌──────────▼──────────┐ ║ │
│ ║ │ Fast Gaussian Splat │ ║ │
│ ║ │ ──► Depth + Semantic │ ║ │
│ ║ │ Maps │ ║ │
│ ║ └──────────┬──────────┘ ║ │
│ ║ │ ║ │
│ ║ Compare vs pseudo-labels ║ │
│ ║ (self-supervised loss) ║ │
│ ╚═══════════════════════════════════════════════════════════╝ │
└──────────────────────────────────────────────────────────────────┘
The architecture has two training stages:
Stage 1 -- Pose Learning (GSP): Multi-camera images are processed through a shared encoder. For each pixel, a depth distribution is predicted and "lifted" into 3D space. These 3D points are treated as Gaussians and splatted into adjacent camera views. The photometric consistency between the splatted view and the actual adjacent view provides a self-supervised signal for learning both depth and relative camera poses. This eliminates the need for ground-truth poses from expensive IMU/GPS sensors.
Stage 2 -- Occupancy Learning (GSV): With poses now available from Stage 1, the system constructs 3D voxel grids from multi-camera features. Instead of using volume rendering (marching rays through the voxel grid) to produce 2D supervision targets, GSV treats each occupied voxel vertex as a 3D Gaussian primitive with learned opacity. These Gaussians are splatted to camera image planes using the fast Gaussian splatting rasterizer, producing depth maps and semantic maps that are compared against pseudo-labels. This is orders of magnitude faster than ray marching.

Results
nuScenes-Occupancy Benchmark
| Method | Supervision | GT Pose | mIoU* | mIoU | Training Speed | Rendering Speed |
|---|---|---|---|---|---|---|
| SurroundOcc | Full 3D | Yes | -- | -- | 1x | 1x |
| SelfOcc | Self-supervised | Yes | -- | -- | 1x | 1x |
| GaussianOcc | Fully self-supervised | No | 11.26 | 9.94 | 2.7x faster | 5x faster |
GaussianOcc achieves 11.26 mIoU* and 9.94 mIoU on nuScenes-Occupancy (best among fully self-supervised methods), while eliminating both 3D annotations and ground-truth poses, with major speed improvements from replacing volume rendering with Gaussian splatting. Stage 1 depth estimation achieves Abs Rel of 0.258; Stage 2 rendered depth with semantic information achieves Abs Rel of 0.197. It is also the first method to achieve 3D occupancy estimation on the DDAD dataset.
Limitations
- Self-supervised pose estimation may be less accurate than sensor-fusion poses in challenging conditions (tunnels, GPS-denied areas)
- Gaussian splatting rendering quality depends on the number of Gaussians and their placement, which is constrained by voxel resolution
- Currently evaluated primarily on nuScenes; generalization to other datasets and sensor configurations needs validation
- The two-stage training pipeline adds complexity compared to end-to-end approaches
Connections
- Builds on the BEV paradigm from Lift Splat Shoot Encoding Images From Arbitrary Camera Rigs By Implicitly Unprojecting To 3D (lift-splat depth estimation)
- Directly comparable to Gaussianflowocc Sparse Occupancy With Gaussian Splatting And Temporal Flow which also uses Gaussians for occupancy but adds temporal flow
- Complements Gaussrender Learning 3D Occupancy With Gaussian Rendering which uses Gaussian rendering as a training loss rather than as the core representation
- Related to Gaussianlss Toward Real World Bev Perception With Depth Uncertainty Via Gaussian Splatting which applies Gaussian splatting to BEV perception
- Occupancy prediction paradigm connects to Drive Occworld Driving In The Occupancy World (4D occupancy world model)
- Evaluated on Nuscenes A Multimodal Dataset For Autonomous Driving benchmarks