GaussianFlowOcc: Sparse and Weakly Supervised Occupancy Estimation using Gaussian Splatting and Temporal Flow
:page_facing_up: Read on arXiv
Overview
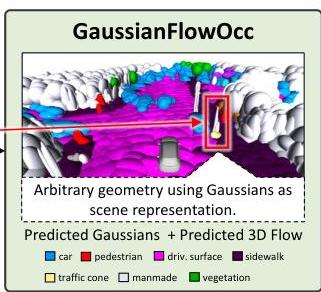
GaussianFlowOcc (ICCV 2025) introduces a transformative approach to 3D semantic occupancy estimation for autonomous driving by replacing traditional dense voxel grids with sparse 3D Gaussian distributions. The key insight is that most driving scenes are dominated by free space -- dense voxel grids waste computation on empty regions. By representing occupied space as a sparse collection of 3D Gaussians, the method achieves dramatically better efficiency while improving accuracy.
The method combines three innovations: (1) sparse Gaussian representation instead of dense voxels, (2) a Gaussian Transformer with deformable cross-attention and induced self-attention to avoid expensive 3D convolutions, and (3) a temporal flow module that estimates 3D motion for each Gaussian to handle dynamic objects. Trained with only 2D pseudo-labels from Grounded-SAM (semantics) and Metric3D (depth) — no expensive 3D annotations — GaussianFlowOcc achieves 17.08% mIoU on Occ3D-nuScenes, a 29% relative improvement over the prior weakly-supervised SOTA (GaussTR at 13.26%), while running at 10.2 FPS on an A100 — 50x faster than GaussTR's 0.2 FPS.
Key Contributions
- Sparse Gaussian occupancy representation: Replaces dense voxel grids with collections of 3D Gaussian distributions, focusing computation only on occupied regions
- Gaussian Transformer with induced attention: Avoids expensive 3D convolutions by using inducing-point attention mechanisms that scale efficiently with the number of Gaussians
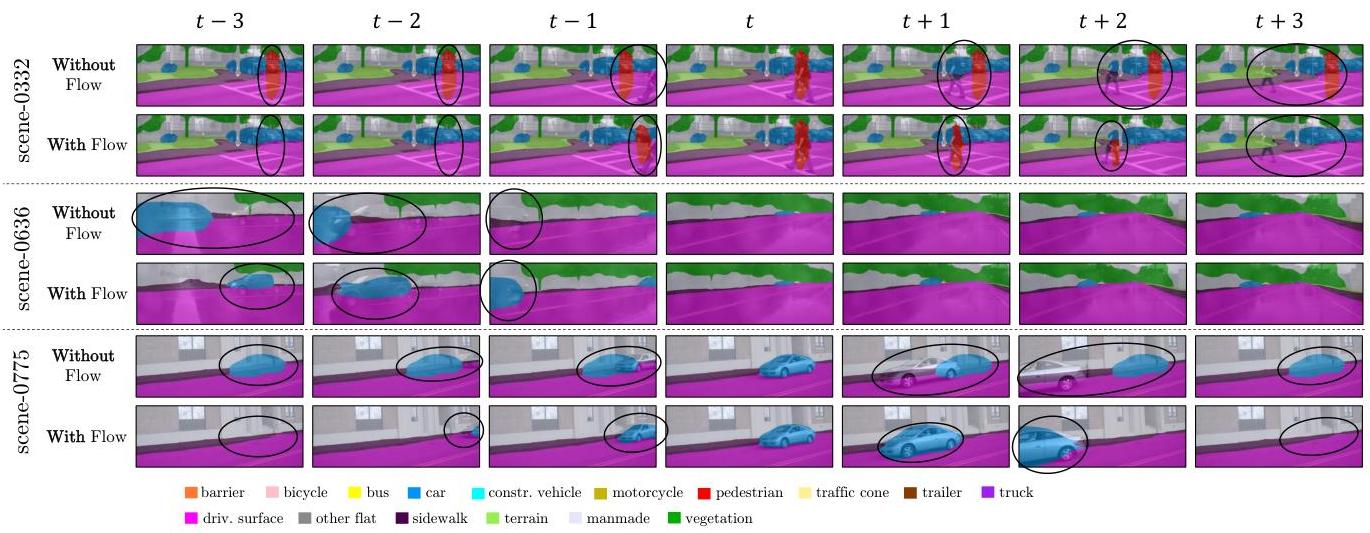
- Temporal flow module: Estimates 3D flow vectors for each Gaussian to model dynamic object motion across frames, improving temporal consistency
- Weak supervision from 2D pseudo-labels: Trains using only 2D semantic pseudo-labels projected from pre-trained models, eliminating the need for costly 3D voxel annotations
- Extreme efficiency: 50x faster inference than prior SOTA (GaussTR) at 10.2 FPS vs. 0.2 FPS, with 29% relative mIoU improvement (17.08% vs. 13.26%) on Occ3D-nuScenes
Architecture / Method
┌─────────────────────────────────────────────────────────────────┐
│ GaussianFlowOcc Pipeline │
│ │
│ ┌──────────┐ ┌────────────┐ ┌──────────────────┐ │
│ │ Multi-cam │───►│ ResNet-50 │───►│ Per-cam Features │ │
│ │ Images │ │ Backbone │ └────────┬─────────┘ │
│ └──────────┘ └────────────┘ │ │
│ ▼ │
│ ┌───────────────────────────┐ │
│ │ Gaussian Initialization │ │
│ │ (sparse, occupied regions │ │
│ │ only -- not full volume) │ │
│ └─────────────┬─────────────┘ │
│ │ │
│ ▼ │
│ ┌───────────────────────────┐ │
│ │ Gaussian Transformer │ │
│ │ ┌─────────────────────┐ │ │
│ │ │ Induced Attention │ │ │
│ │ │ (inducing pts reduce │ │ │
│ │ │ quadratic cost) │ │ │
│ │ ├─────────────────────┤ │ │
│ │ │ Self-Attn + Cross- │ │ │
│ │ │ Attn to BEV features │ │ │
│ │ └─────────────────────┘ │ │
│ └─────────────┬─────────────┘ │
│ │ │
│ ┌────────────────────────────┼─────────────┐ │
│ ▼ ▼ │ │
│ ┌────────────────────┐ ┌──────────────────────┐ │ │
│ │ Temporal Flow │ │ Gaussian Splatting │ │ │
│ │ Module │ │ ──► 2D Rendered Views │ │ │
│ │ (3D flow per │ └──────────┬───────────┘ │ │
│ │ Gaussian for │ │ │ │
│ │ dynamic objects) │ ▼ │ │
│ └────────────────────┘ 2D Pseudo-label Loss │ │
│ (weak supervision) │ │
└─────────────────────────────────────────────────────────────────┘
The architecture consists of four main components:
1. BEV Feature Extraction: Multi-camera images are encoded using a ResNet-50 backbone into per-camera features, which are then lifted to 3D via learnable initial Gaussian queries (not a standard LSS voxel volume).
2. Gaussian Initialization: From BEV features, a set of 3D Gaussians is initialized. Each Gaussian has a 3D center position, covariance (shape/orientation), opacity, and semantic feature vector. Unlike dense voxels that cover the entire volume, Gaussians are placed only in regions likely to be occupied.
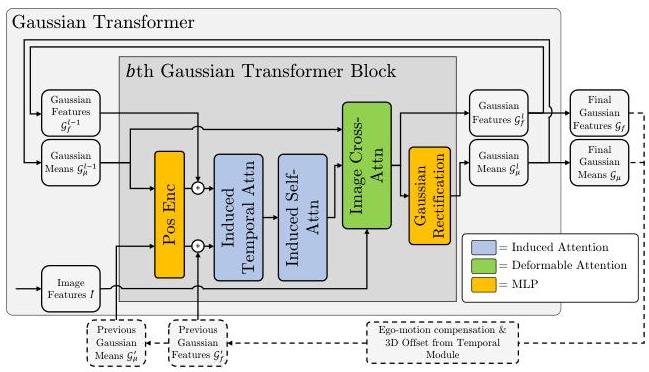
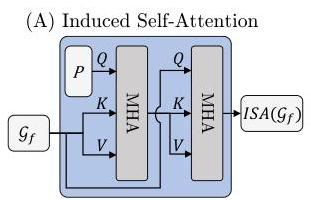
3. Gaussian Transformer: The core module refines Gaussian parameters through three sub-modules per block: (a) Gaussian-Image Cross-Attention (GICA) using deformable mechanisms to attend to multi-view image features, (b) Induced Self-Attention (ISA) with trainable bottleneck inducing points that compresses quadratic O(N²) self-attention to linear O(MN) cost (M inducing points, N Gaussians), and (c) Induced Temporal Attention (ITA) for efficient propagation of historical-frame context. This allows the model to handle 10,000+ Gaussians in memory-feasible fashion.
4. Temporal Flow Module: For multi-frame input, each Gaussian is assigned a 3D flow vector predicting its motion to the next timestep. This enables temporal alignment without requiring explicit object tracking or association. The flow is estimated via a temporal attention module that attends to previous-frame Gaussians.
For supervision, Gaussians are rendered into 2D views using differentiable Gaussian splatting and compared against 2D semantic pseudo-labels from Grounded-SAM and depth pseudo-labels from Metric3D. Loss functions include depth MSE and semantic BCE optimized across temporal frames.
Results
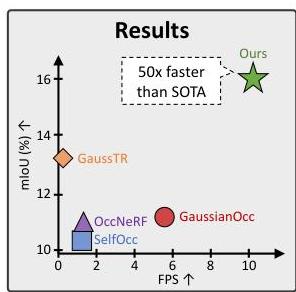
Occ3D-nuScenes Benchmark
| Method | mIoU | Supervision | Inference Speed |
|---|---|---|---|
| GaussTR (prior SOTA) | 13.26% | Self-supervised / weak | 0.2 FPS |
| GaussianFlowOcc | 17.08% | 2D pseudo-labels | 10.2 FPS |
GaussianFlowOcc achieves a 29% relative improvement in mIoU over the previous weakly-supervised SOTA (GaussTR) while running 50x faster (10.2 vs. 0.2 FPS on a single A100 GPU). The temporal flow module alone contributes a 20% relative mIoU improvement in ablation studies, demonstrating the critical importance of explicit dynamics modeling for dynamic object classes.

Limitations
- Weakly supervised with 2D pseudo-labels, so accuracy is bounded by the quality of the pseudo-label generator
- Sparse Gaussian representation may miss thin structures or small objects that don't generate enough support in the initial placement
- Temporal flow assumes approximately rigid motion per Gaussian; deformable objects may not be well handled
- Currently benchmarked only on nuScenes; generalization to other datasets needs validation
Connections
- Directly builds on the Gaussian occupancy paradigm from Gaussianocc Fully Self Supervised 3D Occupancy Estimation With Gaussian Splatting but adds temporal flow and weak supervision
- Complements Gaussrender Learning 3D Occupancy With Gaussian Rendering which uses Gaussians as a rendering loss rather than the core representation
- Related to Gaussianworld Gaussian World Model For Streaming 3D Occupancy Prediction which models occupancy evolution as a world model
- BEV backbone builds on Lift Splat Shoot Encoding Images From Arbitrary Camera Rigs By Implicitly Unprojecting To 3D
- Temporal reasoning connects to Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers (temporal BEV attention)
- Evaluated on Nuscenes A Multimodal Dataset For Autonomous Driving benchmarks