BEVFormer: Learning Bird's-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
Citation
Li, Wang, Li, Xie, Sima, Lu, Yu, Dai (Shanghai AI Lab / Nanjing University / HKU), ECCV, 2022.
Canonical link
Overview
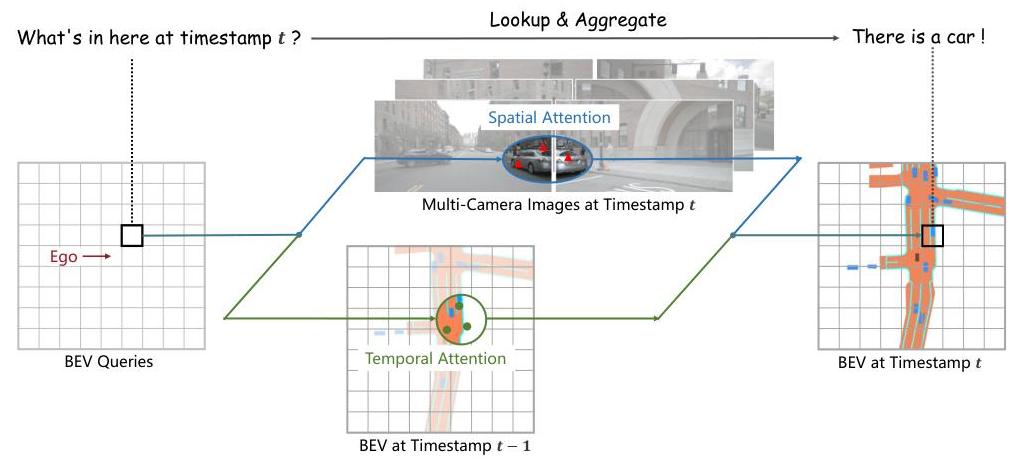
BEVFormer generates a unified bird's-eye-view (BEV) representation from multi-camera images using spatiotemporal transformers, enabling 3D object detection and map segmentation from cameras alone -- without LiDAR. The core idea is to maintain a set of learnable BEV queries arranged on a spatial grid, and use custom attention mechanisms to aggregate features from multi-camera images (spatial cross-attention) and from previous timesteps (temporal self-attention) into this BEV representation.
Prior camera-based 3D detection methods either used depth estimation to lift 2D features to 3D (LSS, BEVDet) or treated the problem as monocular 3D detection per camera. BEVFormer instead uses deformable attention to let each BEV query attend to the relevant regions across all camera views simultaneously, avoiding explicit depth estimation while still producing a geometrically grounded BEV feature map. The temporal self-attention fuses information from the previous frame's BEV features (aligned via ego-motion), enabling velocity estimation and temporal reasoning.
BEVFormer achieved state-of-the-art results on the nuScenes 3D detection and BEV segmentation benchmarks among camera-only methods, and its design became the de facto backbone for subsequent camera-based autonomous driving perception systems. The work demonstrated that transformers could replace the complex geometric projection pipelines previously needed for multi-camera BEV fusion, establishing a cleaner and more flexible approach that downstream planning modules can directly consume.
Key Contributions
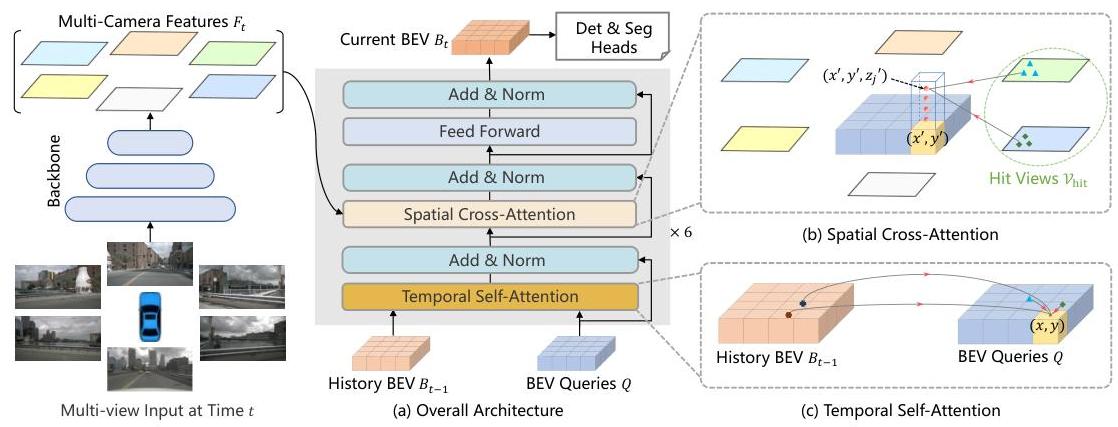
- Spatial cross-attention with predefined 3D reference points: Each BEV query is associated with a pillar of 3D reference points at different heights. These points are projected onto camera image planes, and deformable attention aggregates features from the relevant camera views, avoiding explicit depth prediction
- Temporal self-attention for BEV feature fusion: Previous-frame BEV features are aligned to the current frame using ego-motion, then fused via self-attention with current BEV queries, enabling the model to reason about object motion and improve velocity estimation
- Unified BEV representation for multiple tasks: The same BEV feature map supports both 3D object detection (via DETR-style detection head) and BEV map segmentation (via simple convolutional decoder), demonstrating the representation's generality
- End-to-end trainable without depth supervision: Unlike LSS/BEVDet which require explicit depth estimation, BEVFormer learns the 2D-to-3D mapping implicitly through the attention mechanism
- Efficient multi-camera fusion: Deformable attention attends to only a small number of sampled points per query rather than all pixels, making the approach computationally tractable for 6-camera surround-view setups
Architecture / Method
┌────────────────────────────────────────────────────────────┐
│ BEVFormer Architecture │
├────────────────────────────────────────────────────────────┤
│ │
│ 6 Surround-View Cameras │
│ ┌───┐ ┌───┐ ┌───┐ ┌───┐ ┌───┐ ┌───┐ │
│ │ F │ │FL │ │FR │ │ B │ │BL │ │BR │ │
│ └─┬─┘ └─┬─┘ └─┬─┘ └─┬─┘ └─┬─┘ └─┬─┘ │
│ └──────┴──────┴──┬──┴──────┴──────┘ │
│ ▼ │
│ ┌──────────────────┐ │
│ │ Image Backbone │ (ResNet-101 / VoVNet-99) │
│ │ Multi-Scale FPN │ │
│ └────────┬─────────┘ │
│ │ │
│ BEV Queries │ Prev BEV Features │
│ (HxW grid) │ (ego-motion aligned) │
│ │ │ │ │
│ ▼ │ ▼ │
│ ┌─────────────────┴──────────────────────┐ ─┐ │
│ │ Encoder Layer (x6) │ │ │
│ │ │ │ │
│ │ 1. Temporal Self-Attention │ │ │
│ │ Q: BEV queries │ │ │
│ │ K,V: prev BEV (deformable attn) │ │ │
│ │ │ │ │ x6 │
│ │ ▼ │ │ │
│ │ 2. Spatial Cross-Attention │ │ │
│ │ BEV query ──► 3D ref points ──► │ │ │
│ │ project to cameras ──► │ │ │
│ │ deformable attn on image feats │ │ │
│ │ │ │ │ │
│ │ ▼ │ │ │
│ │ 3. Feed-Forward Network │ │ │
│ └────────────────────────────────────────┘ ─┘ │
│ │ │
│ ▼ │
│ BEV Feature Map (200x200) │
│ ┌───────┴────────┐ │
│ ▼ ▼ │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ DETR3D Head │ │ Segmentation │ │
│ │ (3D Det.) │ │ Head (BEV) │ │
│ └──────────────┘ └──────────────┘ │
└────────────────────────────────────────────────────────────┘
BEVFormer consists of a backbone (ResNet-101 or VoVNet-99), a set of 6 encoder layers, and task-specific heads. The input is 6 surround-view camera images. The backbone extracts multi-scale features from each camera independently.
The BEV queries are a learnable H x W grid (e.g., 200 x 200 covering 100m x 100m at 0.5m resolution). Each encoder layer applies three operations in sequence: (1) temporal self-attention -- each BEV query attends to the aligned BEV features from the previous timestamp at the same spatial location (using deformable attention with ego-motion compensation); (2) spatial cross-attention -- each BEV query generates a pillar of N_ref 3D reference points at predefined heights, projects them onto all camera views, and aggregates image features via deformable attention from the relevant cameras; (3) feedforward network.
For 3D detection, a DETR3D-style head with 6 decoder layers produces bounding box predictions from the BEV features. For segmentation, a simple convolutional head produces per-cell semantic labels on the BEV grid. The whole model is trained end-to-end with standard detection losses (focal loss + L1 for boxes) and/or segmentation cross-entropy loss.
Results
| Method | NDS | mAP | mAVE (m/s) | Backbone |
|---|---|---|---|---|
| BEVFormer (test) | 56.9% | 48.1% | 0.378 | V2-99 |
| BEVFormer (val) | 51.7% | 41.6% | - | R101 |
| DETR3D | 42.5% | 34.6% | 0.845 | R101 |
| SSN (LiDAR) | 56.9% | - | - | - |
- nuScenes 3D detection (val): 51.7% NDS and 41.6% mAP with ResNet-101 backbone, setting a new camera-only SOTA at the time
- nuScenes 3D detection (test): 56.9% NDS with V2-99 backbone, surpassing the previous best camera-based method (DETR3D at 47.9% NDS) by 9.0 points and reaching performance comparable to some LiDAR-based systems like SSN (56.9% NDS) -- a significant milestone for camera-based 3D perception
- Velocity estimation: mAVE of 0.378 m/s, approaching the accuracy of LiDAR-based methods and significantly better than methods without temporal fusion (DETR3D: 0.845). Accurate velocity prediction is fundamental for motion planning and collision avoidance
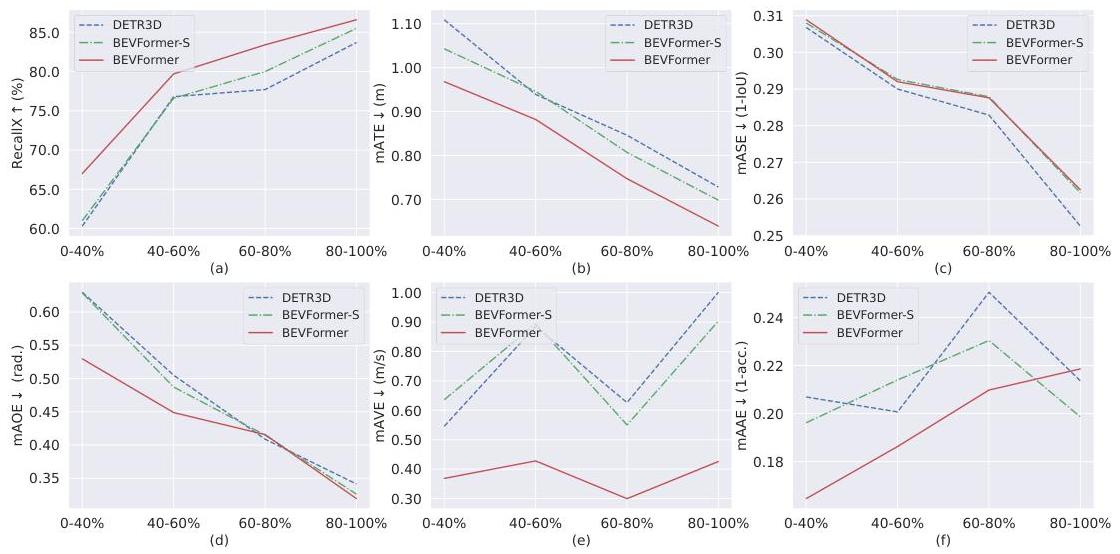
- Temporal occlusion handling: The temporal module achieves over 6.0% higher recall than static versions in low visibility conditions (0-40% visible objects), demonstrating the system's ability to infer hidden object information from temporal context
- BEV segmentation: 44.8% IoU for vehicle segmentation on nuScenes (segmentation-only head), outperforming prior methods such as Lift-Splat (42.1%)
- Robustness: BEVFormer shows improved robustness to camera calibration noise compared to other methods, making it more practical for real-world deployment where perfect sensor calibration is rarely maintained
- Ablation studies: Removing temporal self-attention drops NDS by 3.4 points; removing spatial cross-attention (using simple projection instead) drops mAP by 5.2 points; both components contribute substantially
Limitations & Open Questions
- Performance still lags significantly behind LiDAR-based methods (e.g., CenterPoint achieves 67% NDS), indicating the depth ambiguity inherent to camera-only perception remains a fundamental challenge
- The predefined height sampling for 3D reference points requires domain-specific tuning and does not handle highly variable terrain or overhead structures well
- Temporal fusion only uses one previous frame; longer temporal context could improve tracking and occlusion handling but increases memory and computation
Connections
- Perception
- Autonomous Driving
- End To End Architectures
- Attention Is All You Need
- Emma End To End Multimodal Model For Autonomous Driving
- Bevformer V2 Adapting Modern Image Backbones To Birds Eye View Recognition Via Perspective Supervision — successor that adds perspective supervision to enable modern 2D backbones