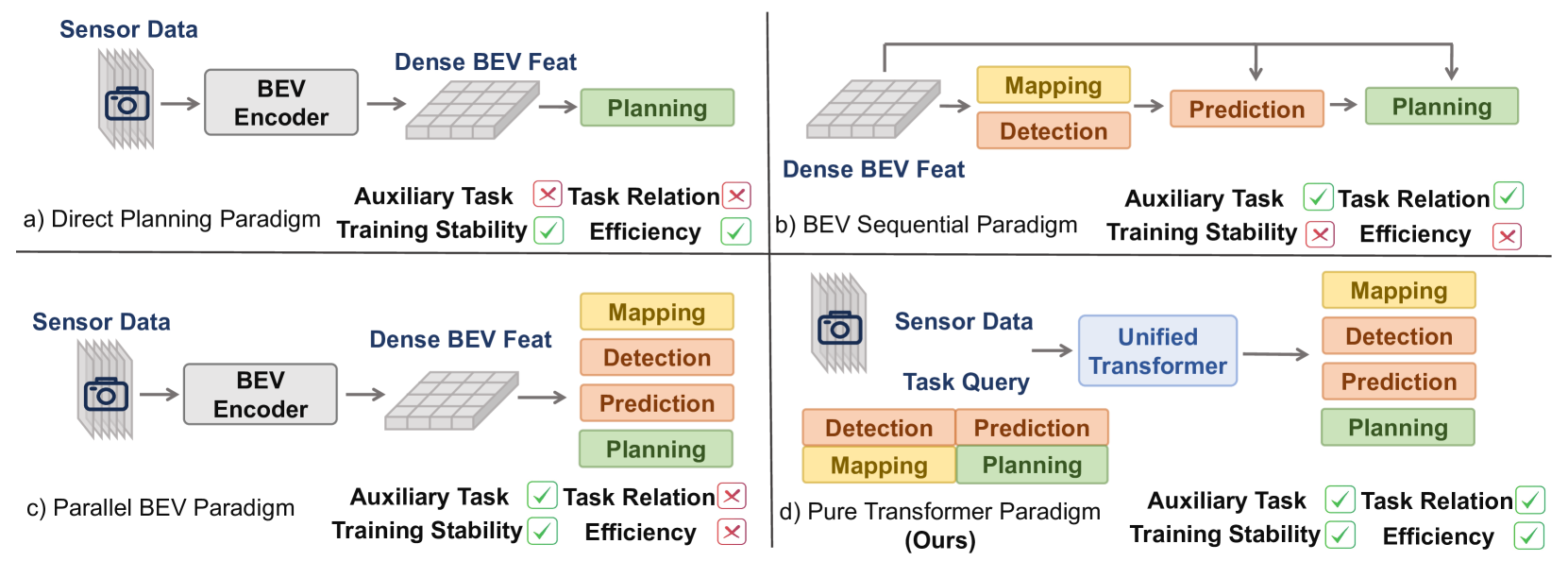
Overview
DriveTransformer represents a fundamental departure from existing end-to-end autonomous driving approaches. Rather than following sequential perception-prediction-planning pipelines with dense BEV representations, the framework implements three core principles: task parallelism, sparse representation, and streaming processing. This design directly addresses the limitations of prior methods like UniAD and VAD, which suffer from cumulative error propagation, training instability due to multi-stage optimization, and computational inefficiency from dense BEV processing.
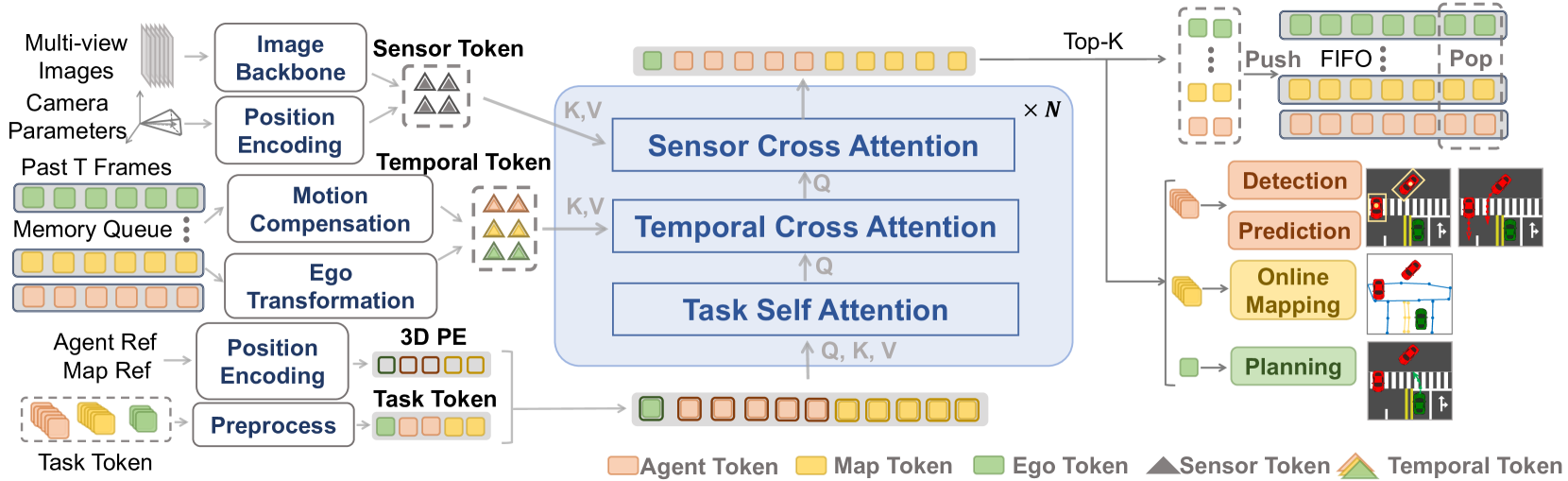
The unified architecture operates through three attention mechanisms that replace the traditional sequential pipeline. Sensor Cross Attention connects task queries directly to raw sensor features, eliminating intermediate representation bottlenecks. Task Self-Attention enables simultaneous interaction among all driving task types -- detection, prediction, mapping, and planning -- rather than processing them sequentially. Temporal Cross Attention incorporates historical information through FIFO queues of past task queries with ego transformation and motion compensation, replacing the expensive storage and processing of historical BEV features.
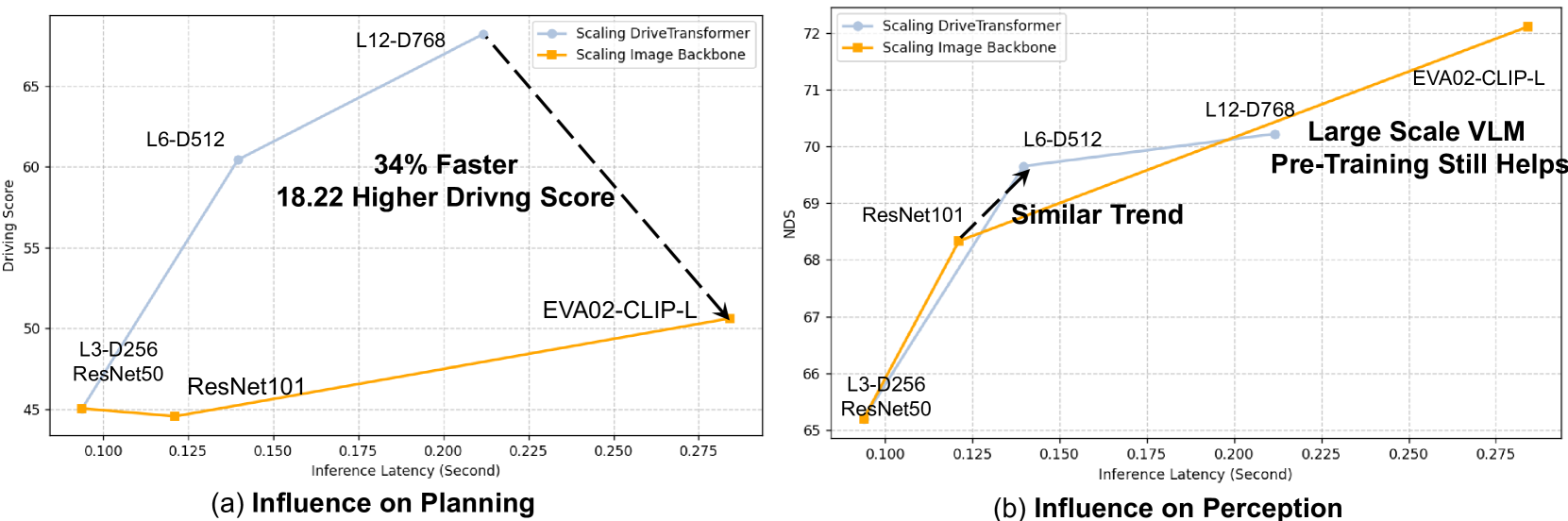
The framework demonstrates superior scaling properties: decoder scaling provides greater planning improvements than backbone scaling, suggesting the interaction between tasks matters more than raw perception capacity. DriveTransformer achieves state-of-the-art closed-loop driving performance on the Bench2Drive simulation benchmark with significantly lower inference latency than competing methods.
Key Contributions
- Task parallelism: All driving tasks (detection, prediction, mapping, planning) are processed simultaneously through shared attention, eliminating sequential error propagation
- Sparse representation: Task-specific queries replace dense BEV maps, reducing computation and memory while preserving task-relevant information
- Streaming temporal processing: FIFO queues of compact past task queries with ego-motion compensation replace expensive historical BEV feature storage
- Unified training: Single-stage end-to-end optimization replaces complex multi-stage training schedules
- Favorable scaling laws: Decoder scaling improves planning more than backbone scaling, revealing where compute is best allocated
Architecture / Method
DriveTransformer (right) eliminates the sequential pipeline structure of UniAD-style systems (left) in favor of parallel task processing with shared attention.
┌──────────────────────────────────────────────────────────────┐
│ DriveTransformer Architecture │
│ │
│ Multi-Camera Images │
│ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ │
│ │Cam 1│ │Cam 2│ │Cam 3│ │Cam 4│ │Cam 5│ │Cam 6│ │
│ └──┬──┘ └──┬──┘ └──┬──┘ └──┬──┘ └──┬──┘ └──┬──┘ │
│ └───────┴───────┴───┬───┴───────┴───────┘ │
│ ▼ │
│ ┌──────────────────────────────┐ │
│ │ Image Backbone │ │
│ │ (Multi-scale features) │ │
│ └──────────────┬───────────────┘ │
│ ▼ │
│ ┌──────────────────────────────────────────────────┐ │
│ │ Unified Decoder (repeated L layers) │ │
│ │ │ │
│ │ Task Queries (all processed in parallel): │ │
│ │ ┌──────┐ ┌──────┐ ┌───────┐ ┌────────┐ │ │
│ │ │Detect│ │ Map │ │Predict│ │Planning│ │ │
│ │ └──┬───┘ └──┬───┘ └───┬───┘ └───┬────┘ │ │
│ │ │ │ │ │ │ │
│ │ ▼ ▼ ▼ ▼ │ │
│ │ ┌─────────────────────────────────────┐ │ │
│ │ │ 1. Sensor Cross-Attention │ │ │
│ │ │ (queries attend to image feats) │ │ │
│ │ ├─────────────────────────────────────┤ │ │
│ │ │ 2. Task Self-Attention │ │ │
│ │ │ (all tasks interact mutually) │ │ │
│ │ ├─────────────────────────────────────┤ │ │
│ │ │ 3. Temporal Cross-Attention │ │ │
│ │ │ (FIFO queue of past queries │ │ │
│ │ │ + ego-motion compensation) │ │ │
│ │ └─────────────────────────────────────┘ │ │
│ └──────────────────────────────────────────────────┘ │
│ ▼ │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ ┌──────────────┐ │
│ │3D Detect │ │HD Map │ │Motion │ │GMM Planning │ │
│ │Output │ │Output │ │Prediction│ │(multi-mode) │ │
│ └──────────┘ └──────────┘ └──────────┘ └──────────────┘ │
└──────────────────────────────────────────────────────────────┘
The architecture consists of a shared decoder with three attention types:
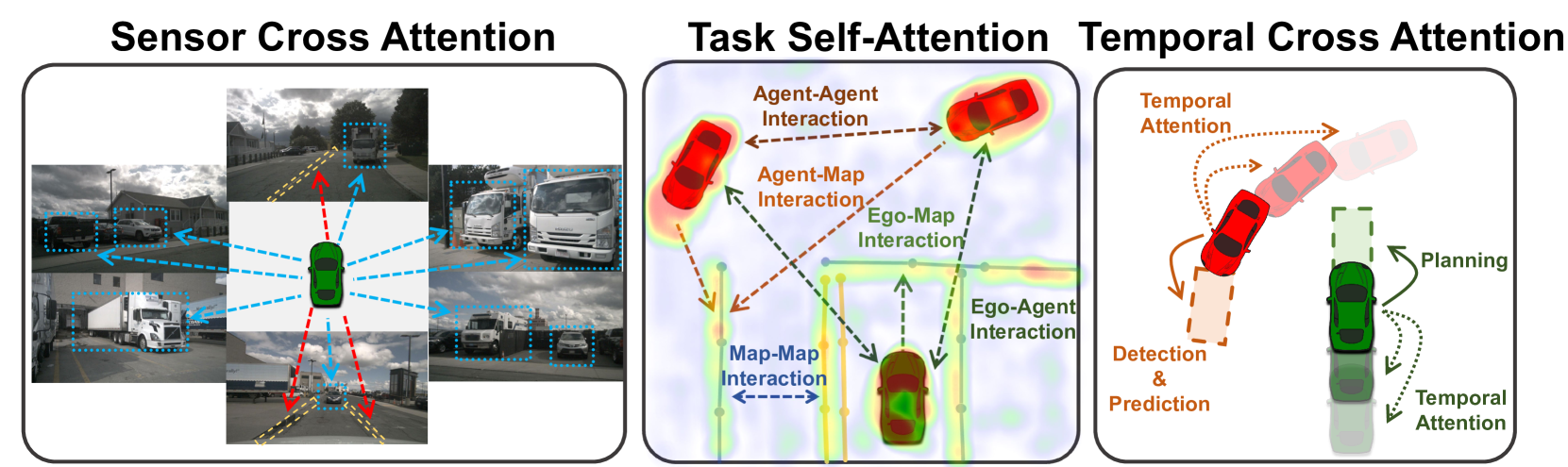
Sensor Cross Attention: Each task query (detection, mapping, planning) attends directly to multi-camera image features. This eliminates the BEV intermediate representation that creates an information bottleneck in prior systems.
Task Self-Attention: All task queries from all task types attend to each other simultaneously. Detection queries can inform planning queries directly; mapping queries and prediction queries interact without sequential ordering.
Temporal Cross Attention: Past task queries are stored in FIFO queues and transformed to the current ego coordinate frame. Agent tokens receive additional motion compensation using predicted velocities. This is far more efficient than storing full BEV features from past timesteps.
Task-specific innovations include: - Shared agent queries for detection and motion prediction (single query handles both); motion prediction operates in local agent coordinate systems - Point-level mapping with PointNet aggregation instead of dense rasterized maps - Multi-mode planning with Gaussian Mixture Models with pre-defined modes (straight, turn left, turn right) to avoid dangerous trajectory averaging
Training: Single-stage end-to-end optimization without perception pre-training. Combined DETR-style losses are applied at task heads in all transformer blocks during training (only the final block's output is used at inference), enabling coarse-to-fine refinement.
Results
Bench2Drive (Closed-Loop Simulation)
| Model | Avg. L2 (m) | Driving Score | Success Rate | Inference Latency |
|---|---|---|---|---|
| DriveTransformer-Large | 0.62 | 63.46 | 35.01% | 211.7ms |
| UniAD-Base | -- | -- | -- | 663.4ms |
| VAD | -- | -- | -- | 278.3ms |
- Multi-ability score: 38.60% vs. UniAD-Base 15.94%
nuScenes (Open-Loop)
| Task | DriveTransformer | Baseline | Notes |
|---|---|---|---|
| Planning Avg. L2 | 0.33m | BEVPlanner++ 0.35m | Best non-ensemble |
| Planning Collision Rate | 0.07% | ParaDrive 0.48m L2 | -- |
| Detection NDS | 59.3 | UniAD 49.8 | -- |
| Motion Prediction minADE | 0.61 | UniAD 0.72 | -- |
| Online Mapping IoU-Road | 0.39 | UniAD 0.30 | -- |
Ablation highlights: - Without Sensor Cross Attention: Driving Score collapses to 8.41% - Local vs. global motion prediction coordinate system: minADE 1.34 vs. 2.68 - Point-level vs. line-level mapping: mAP 20.25 vs. 14.55 - Multi-mode vs. single-mode planning: Driving Score 60.45 vs. 49.19
The scaling analysis reveals a key insight: investing compute in the decoder (where tasks interact) yields greater planning improvements than investing in the backbone (raw perception capacity). This suggests that cross-task reasoning, not just better perception, is the bottleneck in end-to-end driving.
Robustness under sensor corruption (Driving Score drop vs. VAD-Base): - Camera crash: 2.9% drop vs. 9.2% - Incorrect calibration: 5.94% drop vs. 28.04% - Motion blur: 10.60% drop vs. 14.93% - Gaussian noise: 6.02% drop vs. 16.72%
The system maintains performance under various sensor corruption conditions, demonstrating robustness of the sparse representation approach.
Limitations & Open Questions
- Evaluated primarily in simulation (Bench2Drive); real-world closed-loop deployment is not demonstrated
- The sparse representation may lose fine-grained scene details that matter for rare edge cases (e.g., small debris, unusual road markings)
- Whether the favorable decoder scaling law continues to hold at significantly larger model scales is unknown
Connections
- Planning Oriented Autonomous Driving -- UniAD is the primary baseline; DriveTransformer replaces UniAD's sequential pipeline with parallel task processing
- Vad Vectorized Scene Representation For Efficient Autonomous Driving -- VAD introduced vectorized representations; DriveTransformer pushes further toward sparse task queries
- Transfuser Imitation With Transformer Based Sensor Fusion For Autonomous Driving -- TransFuser pioneered transformer-based sensor fusion for driving; DriveTransformer extends the transformer paradigm to all driving tasks
- Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers -- BEVFormer established dense BEV transformers; DriveTransformer argues for sparse alternatives
- Attention Is All You Need -- The underlying transformer architecture that enables the unified attention-based design
- End To End Architectures -- Type 3 jointly trained system that pushes toward full task parallelism
- Planning -- Novel multi-mode GMM planning within unified transformer
- Autonomous Driving -- Demonstrates favorable scaling laws for E2E driving