Planning-oriented Autonomous Driving
Overview
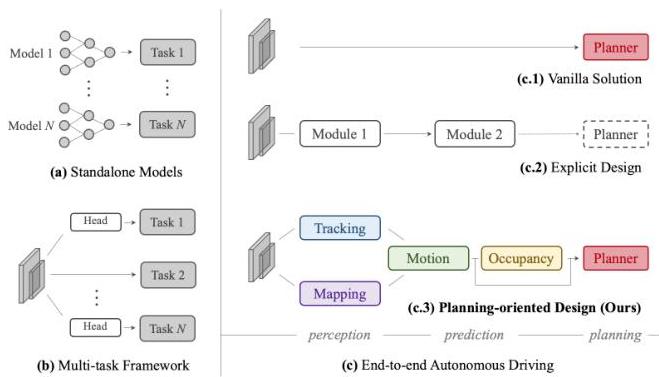
UniAD (Unified Autonomous Driving) is a planning-oriented end-to-end framework that unifies perception, prediction, and planning into a single differentiable network trained with a planning-centric objective. The key argument is that autonomous driving modules (detection, tracking, mapping, motion forecasting, occupancy prediction, planning) should not be developed in isolation -- they should be jointly optimized so that upstream perception learns features that are maximally useful for the downstream planning task. UniAD connects these modules through query-based interfaces within a transformer architecture, allowing gradients from the planning loss to flow back through the entire stack.
Prior to UniAD, the dominant paradigm in autonomous driving was a modular pipeline where each component (detector, tracker, predictor, planner) was trained independently with task-specific losses. This created a well-known information bottleneck: upstream modules optimize for metrics (e.g., mAP for detection) that do not necessarily correlate with planning quality. UniAD demonstrated that joint training with a planning objective significantly improves both planning performance and, surprisingly, the intermediate perception and prediction tasks as well, because the planning gradient signal provides a more informative learning signal than task-specific metrics alone.
UniAD achieved state-of-the-art results on the nuScenes benchmark across multiple tasks simultaneously and became one of the most cited autonomous driving papers of 2023. It established the template for subsequent unified driving architectures and provided strong empirical evidence for the end-to-end approach over modular pipelines, directly influencing work like VAD, GameFormer, and planning-aware perception designs.
Key Contributions
- Planning-oriented joint optimization: All modules (detection, tracking, mapping, motion prediction, occupancy prediction, planning) are trained end-to-end with a planning loss that propagates gradients through the entire architecture
- Query-based module interfaces: Transformer queries serve as the communication protocol between modules -- detection queries become tracking queries, which become motion queries, ensuring information flows smoothly across tasks without hand-designed interfaces
- Comprehensive task coverage: A single model handles 3D detection, multi-object tracking, online HD mapping, agent motion forecasting, occupancy prediction, and trajectory planning -- the most complete set of tasks unified in one architecture at the time
- Empirical evidence for joint training: Ablation studies show that removing any module or its connection to the planning objective degrades planning performance, quantifying the value of each intermediate representation
- Strong nuScenes results: State-of-the-art or competitive on all six tasks simultaneously, demonstrating no fundamental trade-off between generality and performance
Architecture / Method
┌─────────────────────────────────────────────────────────┐
│ Multi-Camera Images │
└──────────────────────┬──────────────────────────────────┘
▼
┌──────────────────────────┐
│ BEV Encoder (BEVFormer) │
└────────────┬─────────────┘
│ BEV Features B
▼
┌──────────────────────────┐
│ TrackFormer │──► Q_A (agent queries)
│ (Detection + Tracking) │ + ego query
└────────────┬─────────────┘
│
▼
┌──────────────────────────┐
│ MapFormer │──► Q_M (map queries)
│ (Online HD Mapping) │
└────────────┬─────────────┘
│
▼
┌──────────────────────────┐
│ MotionFormer │──► K multimodal
│ (Motion Forecasting) │ future trajectories
│ agent-agent attention │
│ agent-map attention │
│ agent-goal attention │
└────────────┬─────────────┘
│
┌───────┴───────┐
▼ ▼
┌────────────────┐ ┌──────────────┐
│ OccFormer │ │ Planner │
│ (Occupancy │ │ (Ego Traj + │
│ Prediction) │ │ Collision │
└────────┬───────┘ │ Optim.) │
│ └──────┬───────┘
└─────────────────┘
collision optimization
tau* = argmin[||tau-tau_hat||² + lambda*CollCost]
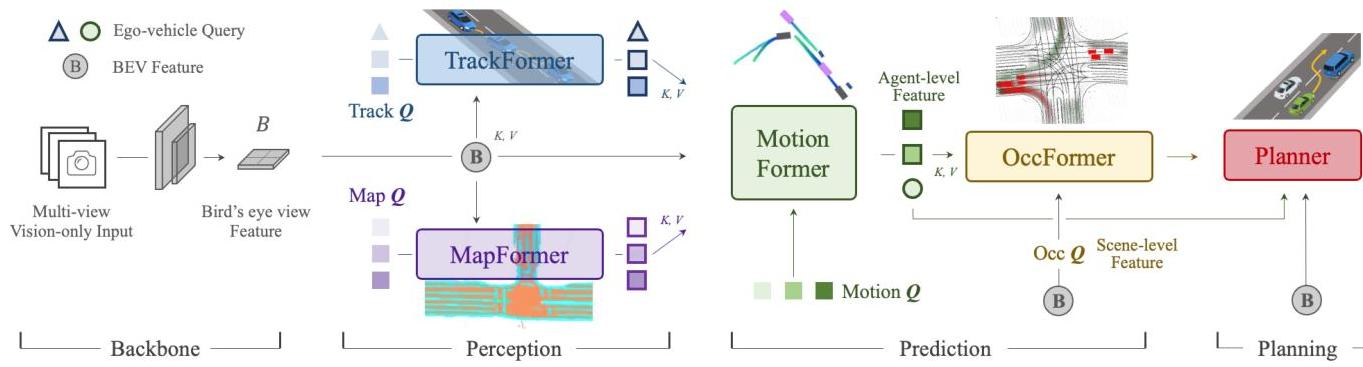
UniAD processes multi-camera images through a BEV feature encoder (BEVFormer-style) to produce a foundational bird's-eye view spatial representation B for all subsequent tasks. The architecture then cascades through five modules connected by transformer queries:
TrackFormer (detection + tracking): Performs joint 3D detection and tracking using detection queries for new agents and track queries maintaining identity across time through self-attention. Outputs agent features Q_A including an ego-vehicle query.
MapFormer (online mapping): Conducts online semantic mapping using sparse map queries Q_M, performing panoptic segmentation categorizing road elements into "things" (lanes, dividers, crossings) and "stuff" (drivable areas).
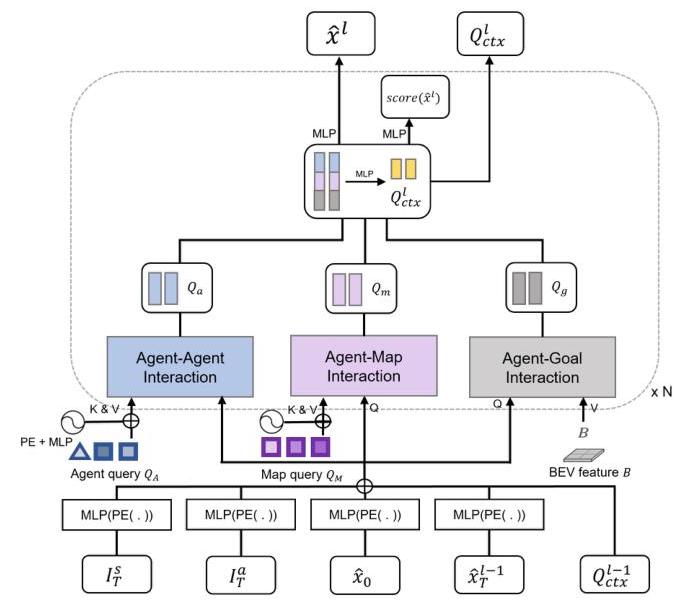
MotionFormer (motion forecasting): Predicts K multimodal future trajectories capturing agent-agent interactions via self-attention, agent-map interactions via cross-attention, and agent-goal interactions via deformable attention. Motion queries integrate scene-level anchors, agent-level anchors, current locations, and predicted goal points. The mathematical formulation: tau_i^(k) = MLP(MotionFormer(Q_A^i, Q_M, Q_ctx)). A critical innovation employs non-linear optimization during training using a multiple-shooting approach, adjusting target trajectories for physical feasibility given imperfect starting points with kinematic constraints like jerk and curvature limits.
OccFormer (occupancy prediction): Predicts future occupancy grids incorporating scene-level BEV features and agent-level knowledge. Dense scene features serve as queries while instance-level agent features provide keys and values for cross-attention, with attention masks ensuring each pixel only attends to relevant agents. Instance-wise occupancy maps are generated through matrix multiplication: O_t^A = MatMul(AgentFeatures_t, SceneFeatures_t^T), enabling direct generation without complex post-processing.
Planner: Generates ego-vehicle trajectories combining the ego-vehicle query from MotionFormer with learned command embeddings. The plan query attends to BEV features, with an MLP decoding initial waypoints further optimized using occupancy predictions. During inference, initial trajectory predictions undergo collision optimization using Newton's method: tau* = argmin_tau [||tau - tau_hat||^2 + lambda * CollisionCost(tau, O_hat)], where lambda balances adherence to initial prediction with collision avoidance.
Training strategy: Two-stage training for stability. Stage 1 (perception pre-training): TrackFormer and MapFormer jointly train for 6 epochs using pre-trained BEVFormer weights with gradients stopped at the image backbone. Stage 2 (end-to-end training): The complete model trains end-to-end for 20 epochs with frozen image backbone and BEV encoder. The system uses shared bipartite matching across tracking and mapping tasks. Task-specific losses include focal and L1 losses for detection, multi-path loss for motion forecasting, BCE and Dice losses for occupancy prediction, and imitation L2 plus collision losses for planning.
Results
| Task | UniAD | Best Baseline | Improvement |
|---|---|---|---|
| Motion Forecasting (minADE) | 0.71m | PnPNet: 1.15m | -38.3% |
| Planning (avg. L2 error) | 1.03m | ST-P3: 2.11m | -51.2% |
| Planning (avg. collision rate) | 0.31% | ST-P3: 0.71% | -56.3% |
| Tracking (AMOTA) | 35.9 | MUTR3D: 29.4 | +6.5 |
- System-level gains over naive multi-task learning: 15.2% reduction in minADE and 17.0% reduction in minFDE for motion forecasting, 4.9% improvement in occupancy IoU, 0.15m reduction in average L2 error and 0.51% reduction in collision rate for planning
- Multi-object tracking: 6.5 higher AMOTA than MUTR3D and 14.2 higher than ViP3D (35.9 AMOTA overall)
- Motion forecasting: 38.3% minADE reduction compared to PnPNet and 65.4% reduction compared to ViP3D; 0.71m minADE overall (across the full prediction horizon)
- Occupancy prediction: 4.0% higher IoU-near compared to FIERY
- Planning: 51.2% reduction in average L2 error and 56.3% reduction in average collision rate compared to ST-P3 (1.03m average L2 error and 0.31% average collision rate; per-horizon breakdown: L2 0.48m/0.96m/1.65m at 1s/2s/3s, collision 0.05%/0.17%/0.71%)
- On nuScenes detection: 45.3 mAP and 55.8 NDS, competitive with dedicated detectors while also performing all downstream tasks
- Qualitative robustness: The system shows robustness to upstream perception failures, with the planner maintaining awareness of missed objects through its attention mechanism; the planner's attention adapts dynamically to navigation commands
- Ablation studies show removing the tracking module increases planning L2 by 23%, and removing mapping increases it by 18%, quantifying each module's contribution to planning quality
- The framework's success compared even to LiDAR-based methods highlights the potential of vision-centric integrated systems
Limitations & Open Questions
- The multi-stage training procedure is complex and computationally expensive (~8 A100 GPUs for several days), and the sensitivity to training schedule and loss weights makes reproduction challenging
- Evaluation is on nuScenes with replayed logs (open-loop), not closed-loop simulation; the gap between open-loop metrics and actual driving competence remains an open concern
- The architecture assumes a fixed set of tasks and module ordering; adding new tasks (e.g., traffic light recognition) requires architectural changes rather than modular plug-in, limiting extensibility
Connections
- Planning -- planning-centric design philosophy
- Autonomous Driving -- comprehensive AV architecture
- End To End Architectures -- canonical example of unified end-to-end driving
- Perception -- jointly optimized perception backbone
- Prediction -- motion forecasting integrated into the planning objective
- Lift Splat Shoot Encoding Images From Arbitrary Camera Rigs By Implicitly Unprojecting To 3D -- BEV feature encoding foundation
- Nuscenes A Multimodal Dataset For Autonomous Driving -- primary evaluation benchmark