VADv2: End-to-End Vectorized Autonomous Driving via Probabilistic Planning
Overview
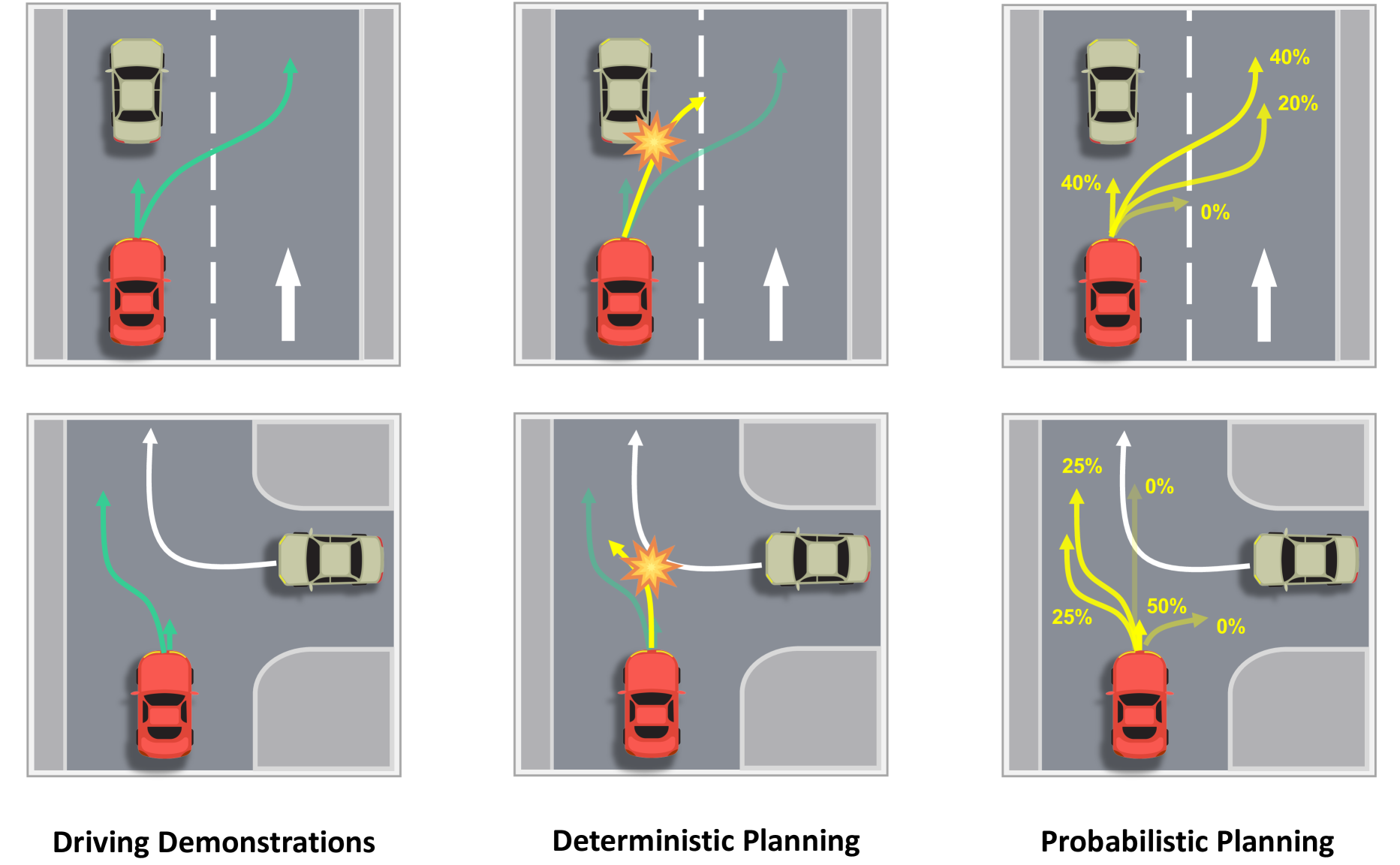
VADv2 by Chen et al. (2024) is the successor to VAD, addressing a fundamental limitation of deterministic planners in autonomous driving: they output a single trajectory, ignoring that multiple viable driving actions exist in any given scenario. When other agents behave unexpectedly, a deterministic planner has no fallback. VADv2 reframes the planning problem as a probabilistic one, modeling the planning policy as an environment-conditioned stochastic process that outputs a distribution over actions rather than a single trajectory.
The core technical insight draws from large language models: VADv2 discretizes the continuous action space into a finite "planning vocabulary" of representative trajectories derived from human driving demonstrations using furthest-point sampling. A transformer-based architecture then predicts a probability distribution over this vocabulary conditioned on the vectorized scene representation, analogous to how LLMs predict token distributions over a language vocabulary. This enables the planner to express uncertainty across multiple plausible driving modes (e.g., yielding vs. proceeding through an intersection) rather than averaging them into a single unsafe trajectory.
VADv2 achieved state-of-the-art closed-loop performance on the CARLA Town05 benchmark using only camera sensors, demonstrating higher route completion rates and fewer infractions (collisions and traffic rule violations) than prior methods. The probabilistic formulation directly addresses the mode-averaging problem that plagues deterministic planners in multi-modal driving scenarios, making it a significant architectural advance in the vectorized end-to-end driving paradigm.
Key Contributions
- Probabilistic planning via action vocabulary: Discretizes continuous trajectory space into a finite set of representative trajectories (planning vocabulary) derived by furthest-point sampling from human demonstrations, enabling the planner to output a categorical distribution over actions rather than regressing a single trajectory
- LLM-inspired planning formulation: Frames autonomous driving planning as predicting a probability distribution over an action vocabulary, drawing a direct parallel to language modeling; trained with KL divergence between predicted and data distributions
- Scene-conditioned action distribution: Uses a transformer decoder that attends to vectorized scene tokens (map polylines, agent trajectories, ego state) to produce action probabilities, preserving the efficiency of vectorized representations from VAD
- Conflict-aware action selection: Introduces a conflict resolution mechanism that evaluates candidate trajectories from the predicted distribution for safety violations (collision checking against predicted agent futures), selecting the highest-probability collision-free trajectory at inference time
- State-of-the-art closed-loop performance: Achieves best results on CARLA Town05 Long benchmark among camera-only methods, validating that probabilistic planning substantially improves closed-loop driving over deterministic alternatives
Architecture
┌──────────────────────────────────────────────────────────┐
│ VADv2 Pipeline │
│ │
│ Multi-camera Images │
│ │ │
│ ▼ │
│ ┌──────────────┐ │
│ │ BEV Encoder │ (backbone + BEV lifting) │
│ └──────┬───────┘ │
│ │ │
│ ┌────┴──────────────┐ │
│ ▼ ▼ │
│ ┌──────────┐ ┌──────────┐ │
│ │ Map Det │ │ Agent │ │
│ │(polylines)│ │ Pred │ │
│ └────┬─────┘ └────┬─────┘ │
│ │ Vectorized │ │
│ │ Scene Tokens │ │
│ └───────┬───────┘ │
│ ▼ │
│ ┌────────────────────────────┐ ┌───────────────────┐ │
│ │ Probabilistic Planning │ │Planning Vocabulary│ │
│ │ Transformer Decoder │◄──│N trajectories │ │
│ │ (ego queries + cross-attn) │ │(furthest traj. │ │
│ │ │ │ sampling, N=4096) │ │
│ └────────────┬───────────────┘ └───────────────────┘ │
│ │ │
│ ▼ │
│ ┌────────────────────────────┐ │
│ │ P(action | scene) │ Categorical distribution │
│ │ [p1, p2, ..., pK] │ over K vocabulary entries │
│ └────────────┬───────────────┘ │
│ │ │
│ ▼ │
│ ┌────────────────────────────┐ │
│ │ Conflict-Aware Selection │ Check top trajectories │
│ │ (collision filtering) │ against predicted agents │
│ └────────────┬───────────────┘ │
│ ▼ │
│ Best safe trajectory │
└──────────────────────────────────────────────────────────┘
Architecture / Method
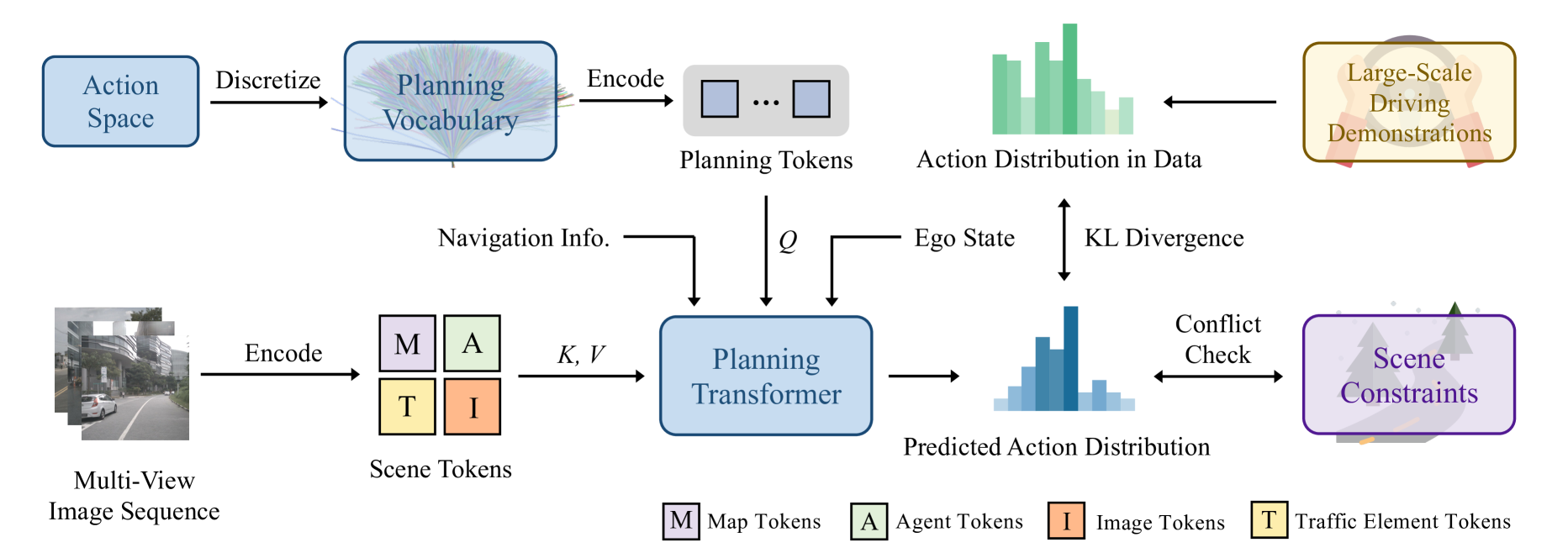
VADv2 builds on the VAD architecture but replaces the deterministic planning head with a probabilistic planning framework. The architecture has four main stages:
Stage 1 -- Scene Encoding: Multi-camera images are processed by an image backbone and lifted to BEV space. The BEV features are then used to extract vectorized scene representations: map polylines (lane boundaries, crosswalks, road edges) and agent trajectories (predicted futures of surrounding vehicles and pedestrians), following the same approach as VAD.
Stage 2 -- Planning Vocabulary Construction (offline): Before training, the continuous trajectory space is discretized by collecting all planning actions from driving demonstrations and applying furthest trajectory sampling to select N representative trajectories (the "planning vocabulary"). By default N=4096. Each vocabulary entry is a fixed-length sequence of 2D waypoints representing a canonical driving maneuver (straight, slight left, hard right, decelerate, etc.). This vocabulary is fixed during training and inference.
Stage 3 -- Probabilistic Planning Transformer: A transformer decoder takes learnable ego planning queries and attends to the vectorized scene tokens (map vectors, agent vectors, and ego state embeddings) via cross-attention. Instead of regressing waypoints, the decoder produces logits over the K vocabulary entries. A softmax produces a probability distribution over the planning vocabulary. The model is trained with three losses: - Distribution loss: KL divergence between the predicted action distribution and the empirical data distribution derived from human driving demonstrations (L_distribution = D_KL(p_data || p_pred)) - Scene token loss: Auxiliary losses on the scene encoding (map detection, agent prediction) inherited from VAD - Conflict loss: A penalty term that discourages high probability on vocabulary entries that would cause collisions with predicted agent trajectories
Stage 4 -- Conflict-Aware Inference: At test time, the model predicts the full action distribution. Rather than simply taking the argmax, VADv2 performs conflict checking: each high-probability trajectory candidate is evaluated against predicted agent futures for collision. The highest-probability collision-free trajectory is selected. This two-stage process (predict distribution, then filter) provides an additional safety layer without requiring a separate safety module.
Results
CARLA Town05 Long Benchmark (Closed-Loop)
| Method | Driving Score | Route Completion | Infraction Score |
|---|---|---|---|
| VADv2 (camera-only) | 85.1 | 98.4% | 0.87 |
| VAD (camera-only) | 30.3 | 75.2% | -- |
| TransFuser† (camera+LiDAR) | 31.0 | 47.5% | 0.77 |
- 181% improvement in Driving Score over VAD: The probabilistic formulation yields a massive closed-loop gain (85.1 vs. 30.3), validating that expressing uncertainty over actions matters significantly for real driving performance
- Superior route completion: 98.4% route completion represents a substantial improvement over VAD (75.2%), indicating the probabilistic planner is far better at handling complex intersections and lane changes
- Reduced infractions: The conflict-aware selection mechanism reduces collision rates by filtering out trajectories that would intersect with predicted agent positions
- Camera-only advantage: VADv2 outperforms TransFuser† which uses both camera and LiDAR, demonstrating that a strong planning formulation can compensate for sensor limitations
- Ablation on vocabulary size N: Performance improves as N increases, with the default N=4096 used in main experiments; ablations confirm that finer action discretization captures more driving modes
- Conflict checking matters: Removing the conflict-aware selection at inference time degrades performance significantly, showing that the probabilistic distribution alone is not sufficient -- the safety filtering is essential
Limitations & Open Questions
- Vocabulary discretization: The fixed planning vocabulary cannot represent arbitrary trajectories -- only combinations of the K cluster centers. Unusual maneuvers not well-represented in the training data (e.g., rare swerves, U-turns) may be poorly covered
- Open-loop gap: While VADv2 demonstrates strong closed-loop results on CARLA, it inherits VAD's reliance on nuScenes-style training data which is primarily straight driving. The vocabulary reflects the training distribution
- Vocabulary construction is offline: The planning vocabulary is fixed before training and not adapted during learning. An end-to-end learnable vocabulary (analogous to learned tokenizers in NLP) could improve coverage
- Single-step planning: VADv2 selects one trajectory per timestep without explicit temporal consistency between consecutive selections, which could cause jittery driving in practice (cf. MomAD's momentum-aware approach)
- Conflict checking assumes accurate prediction: The safety filtering is only as good as the agent prediction quality. If predicted agent futures are wrong, the conflict check may filter good trajectories or pass unsafe ones
Connections
Related papers in the wiki: - Vad Vectorized Scene Representation For Efficient Autonomous Driving -- direct predecessor; VADv2 builds on VAD's vectorized scene representation and replaces the deterministic planner - Planning Oriented Autonomous Driving -- UniAD, the jointly trained modular E2E system that VAD and VADv2 improve upon - Diffusiondrive Truncated Diffusion Model For End To End Autonomous Driving -- alternative approach to multimodal planning using truncated diffusion instead of discrete vocabulary - Goalflow Goal Driven Flow Matching For Multimodal Trajectory Generation -- flow matching approach to multimodal trajectory generation, another solution to the mode-averaging problem - Momad Momentum Aware Planning In End To End Autonomous Driving -- addresses temporal consistency in E2E planning, complementary to VADv2's probabilistic formulation - Sparsedrive End To End Autonomous Driving Via Sparse Scene Representation -- SparseDrive/V2 also uses trajectory vocabulary scoring but with a factorized vocabulary - Carplanner Consistent Autoregressive Rl Planner For Autonomous Driving -- RL-based planner that also addresses multimodal planning but through autoregressive generation - Planning -- broader context on planning evolution - End To End Architectures -- taxonomy of E2E approaches (VADv2 is Type 3: jointly trained modular)