BridgeAD: Bridging Past and Future End-to-End Autonomous Driving with Historical Prediction
Overview
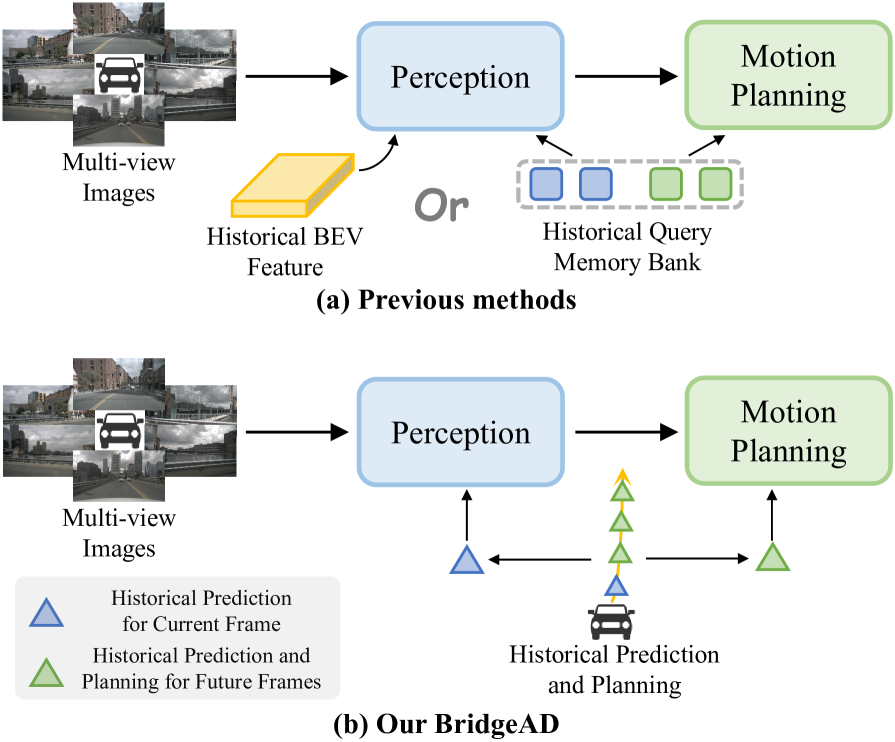
BridgeAD tackles a critical limitation in end-to-end autonomous driving: the ineffective utilization of historical temporal information. Current systems either aggregate historical BEV features primarily for perception (dense approaches like UniAD, VAD) or interact coarsely with historical planning data by treating entire trajectories as single units (sparse methods like SparseDrive). BridgeAD's core insight is that "the future is a continuation of the past" and requires granular temporal modeling that distinguishes different future timesteps and their historical contexts.
The framework reformulates motion and planning queries as multi-step entities -- explicitly adding a temporal dimension to query representations -- enabling fine-grained, timestep-specific interactions with historical information. A FIFO memory queue stores historical multi-step queries, and three history-enhanced modules (perception, motion prediction, and planning) selectively attend to relevant historical context at each timestep. A novel step-level motion-to-planning interaction ensures dynamic consistency between predicted agent behaviors and ego planning.
Developed at Fudan University and Eastern Institute of Technology, BridgeAD demonstrates significant improvements in both open-loop and closed-loop settings on nuScenes. Its superior closed-loop collision avoidance performance (1.52 vs SparseDrive's 0.92 NeuroNCAP score without post-processing) suggests the temporal modeling approach produces more consistent, safer planning trajectories.
Key Contributions
- Multi-step query formulation: Reformulates motion queries from
N_a x M_mot x CtoN_a x M_mot x T_mot x C, adding an explicit temporal dimension that enables timestep-specific reasoning about future states - History-enhanced perception: Integrates historical motion predictions into current perception via cross-attention, leveraging past movement knowledge to improve detection and tracking
- History-enhanced motion planning: Three interconnected sub-modules refine motion and planning queries using historical context with step-level and mode-level self-attention
- Step-level Mot2Plan interaction: Ensures dynamic consistency by having planning queries interact with the highest-probability motion prediction mode at corresponding future timesteps
- Strong closed-loop safety: Achieves 1.52 NeuroNCAP score vs SparseDrive's 0.92, demonstrating that fine-grained temporal modeling translates to safer driving
Architecture / Method
┌────────────────────────────────────────────────────────────────┐
│ BridgeAD Architecture │
├────────────────────────────────────────────────────────────────┤
│ │
│ Multi-View Cameras ──► Image Encoder ──► Image Features │
│ │ │
│ ┌────────────────────────────────┐ │ │
│ │ FIFO Memory Queue (K=3 frames) │ │ │
│ │ Historical multi-step queries │ │ │
│ └────────────┬───────────────────┘ │ │
│ │ │ │
│ ┌─────────┼────────────────────────────────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────────────────────────────┐ │
│ │ History-Enhanced Perception │ │
│ │ Q_obj + CrossAttn(K,V=Q_m2d) │ Hist. motion ──► │
│ │ ──► 3D Detection + Tracking │ improved detection │
│ └──────────────┬───────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────┐ │
│ │ History-Enhanced Motion Pred. │ │
│ │ Multi-step queries: │ │
│ │ N_a x M_mot x T_mot x C │ ◄── explicit temporal │
│ │ + Step-level self-attention │ dimension │
│ │ + Mode-level self-attention │ │
│ └──────────────┬───────────────────┘ │
│ │ │
│ Best mode ▼ (per timestep) │
│ ┌──────────────────────────────────┐ │
│ │ Step-Level Mot2Plan Interaction │ │
│ │ Planning queries attend to │ │
│ │ highest-prob motion mode at │ │
│ │ corresponding future timestep │ │
│ └──────────────┬───────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────┐ │
│ │ History-Enhanced Planning │ │
│ │ + Historical planning context │ │
│ │ ──► Ego Trajectory │ │
│ └──────────────────────────────────┘ │
└────────────────────────────────────────────────────────────────┘
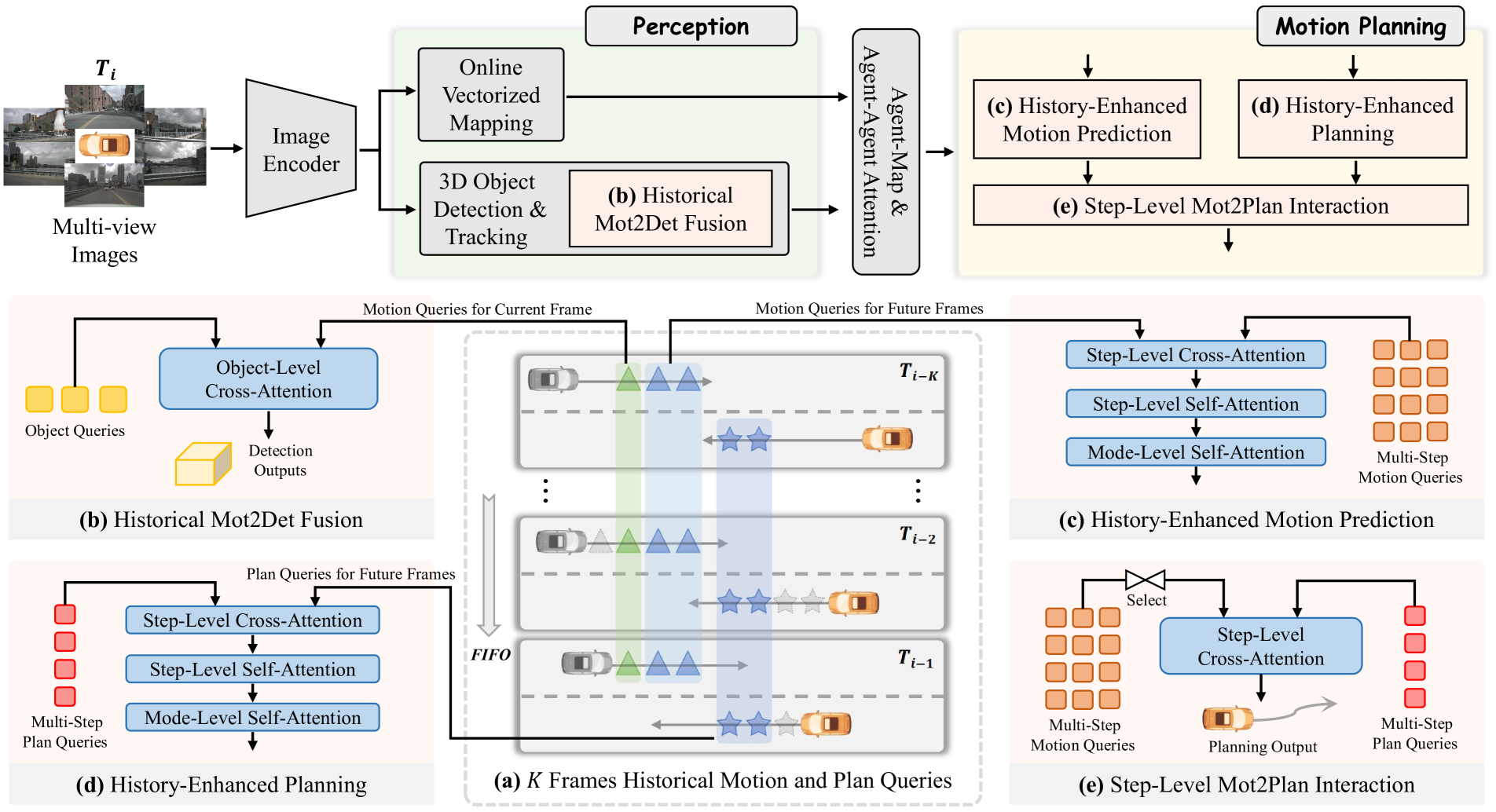
BridgeAD processes multi-view camera images through an image encoder, then feeds features through history-enhanced perception and motion planning modules. A FIFO memory queue of K frames stores historical multi-step queries for temporal continuity.
History-Enhanced Perception: The perception module (3D detection, tracking, vectorized mapping) integrates historical motion predictions into current perception. A Historical Mot2Det Fusion Module combines cached motion queries with current object queries via cross-attention: CrossAttn(Q=Q_obj, K,V=Q_m2d), leveraging historical object movement knowledge for improved detection.
History-Enhanced Motion Prediction: Multi-step motion queries refine using historical motion queries through cross-attention, step-level self-attention for timestep consistency, and mode-level self-attention for prediction mode refinement. The explicit temporal dimension enables attending to the specific historical timestep most relevant for each future prediction step.
History-Enhanced Planning: Ego-planning queries enhance using historical planning queries through identical attention mechanisms, ensuring current plans benefit from the temporal continuity of past decisions.
Step-Level Mot2Plan Interaction: The highest-probability mode from multi-modal motion predictions interacts with planning queries at corresponding future timesteps, ensuring the ego-vehicle plan incorporates the most probable future agent movements at each specific moment.
Results
Open-Loop Performance
| Method | L2 Error (m) | Collision Rate (%) |
|---|---|---|
| UniAD | 0.73 | 0.61 |
| VAD | 0.72 | 0.21 |
| SparseDrive | 0.61 | 0.10 |
| BridgeAD-S | 0.59 | 0.09 |
| BridgeAD-B | 0.58 | 0.08 |
Closed-Loop Performance (NeuroNCAP)
| Method | NeuroNCAP Score | Collision Rate (%) |
|---|---|---|
| SparseDrive | 0.92 | -- |
| BridgeAD (no post-proc) | 1.52 | -- |
| BridgeAD (with post-proc) | 2.98 | 46.1 |
BridgeAD-S achieves 19% improvement in L2 error compared to UniAD (0.59m vs 0.73m) while maintaining lower collision rates. Motion prediction achieves 0.62m ADE and 0.98m FDE for cars. Ablation studies confirm optimal configuration at K=3 historical frames.
Limitations & Open Questions
- Post-processing dependency: Best closed-loop performance requires trajectory post-processing, indicating the raw planning output still has room for improvement
- Computational overhead: Multi-step query architecture and attention mechanisms introduce latency that may challenge real-time deployment
- Limited temporal window: Current K=3 frame window limits historical context; longer-term memory mechanisms could improve performance in complex scenarios
Connections
- Directly extends and improves upon Planning Oriented Autonomous Driving (UniAD) and Vad Vectorized Scene Representation For Efficient Autonomous Driving (VAD) through better temporal modeling
- The multi-step query formulation addresses limitations identified in SparseDrive's coarse trajectory interaction
- Temporal fusion approach is complementary to the BEV temporal modeling in Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers
- Planning improvements relate to the trajectory evaluation ideas in Wote End To End Driving With Online Trajectory Evaluation Via Bev World Model