WoTE: End-to-End Driving with Online Trajectory Evaluation via BEV World Model
Overview
End-to-end driving models typically output a single trajectory and trust it entirely, with no mechanism to evaluate whether the predicted path is safe before execution. WoTE (World model for Trajectory Evaluation) introduces the principle of "simulate before you act" -- analogous to tree search in game playing (AlphaGo/AlphaZero) -- by generating multiple candidate trajectories, simulating future states for each through a BEV world model, and selecting the safest trajectory before committing to execution.
The key efficiency insight is operating in BEV space rather than image space for the world model simulation. Prior work on world models for driving (e.g., GAIA-1, DriveDreamer) typically generated full RGB image predictions of future states, which is computationally prohibitive for real-time online evaluation of multiple trajectories. BEV representations encode only what matters for safety evaluation -- positions, lanes, and obstacles -- in a compact 2D top-down format. This makes it feasible to simulate K candidate trajectories in parallel within the latency budget of a real-time driving system.
WoTE achieves state-of-the-art on both NAVSIM (open-loop) and Bench2Drive (closed-loop CARLA) benchmarks, validating that online trajectory evaluation improves driving safety across evaluation paradigms. The fully differentiable pipeline integrating perception, BEV world model prediction, and planning in a unified framework represents a promising direction for combining learned world models with planning in autonomous driving.
Key Contributions
- BEV-space world model for trajectory evaluation: Predicts future BEV states conditioned on each candidate trajectory, evaluating collision, off-road, and smoothness criteria in compact top-down representation rather than expensive image-level rendering
- Online trajectory selection: Generates K candidate trajectories via diverse sampling, simulates consequences for each via the world model, and selects the best trajectory based on evaluation scores before execution
- BEV efficiency over image-level world models: Compact representation encodes only safety-relevant information (positions, lanes, obstacles), avoiding expensive pixel-level rendering while maintaining sufficient fidelity for trajectory evaluation
- Fully differentiable pipeline: End-to-end training of perception, BEV world model prediction, trajectory generation, and trajectory evaluation in a unified framework with shared gradients
- Dual benchmark state-of-the-art: Top performance on both NAVSIM (open-loop) and Bench2Drive (closed-loop CARLA), demonstrating robustness across evaluation paradigms
Architecture
┌──────────────────────────────────────────────────────────┐
│ WoTE Pipeline │
│ │
│ Multi-camera + LiDAR │
│ │ │
│ ▼ │
│ ┌──────────────┐ │
│ │ BEV Encoder │ Perception backbone │
│ └──────┬───────┘ │
│ │ BEV features │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ Trajectory Predictor │ K-means anchors + refinement │
│ │ N candidate trajs │ │
│ └──┬───┬───┬───┬───────┘ │
│ │ │ │ │ N trajectories │
│ ▼ ▼ ▼ ▼ │
│ ┌──────────────────────────────────┐ │
│ │ BEV World Model (per traj) │ │
│ │ B^i_{t+k} = WM(B^i_{t+k-1}, │ │
│ │ a^i_{t+k-1}) │ │
│ │ Predict future BEV states │ │
│ │ for K timesteps each │ │
│ └──────────────┬───────────────────┘ │
│ │ Predicted futures per trajectory │
│ ▼ │
│ ┌──────────────────────────────────┐ │
│ │ Reward-Based Evaluator │ │
│ │ r_im = imitation reward │ │
│ │ r_sim = collision + drivable │ │
│ │ + TTC + comfort + prog │ │
│ │ r_final = log(r_im) + │ │
│ │ Σ w_j·log(r_sim^j) │ │
│ └──────────────┬───────────────────┘ │
│ ▼ │
│ Best-rewarded trajectory │
│ (18.7ms for 256 candidates) │
└──────────────────────────────────────────────────────────┘
Architecture / Method
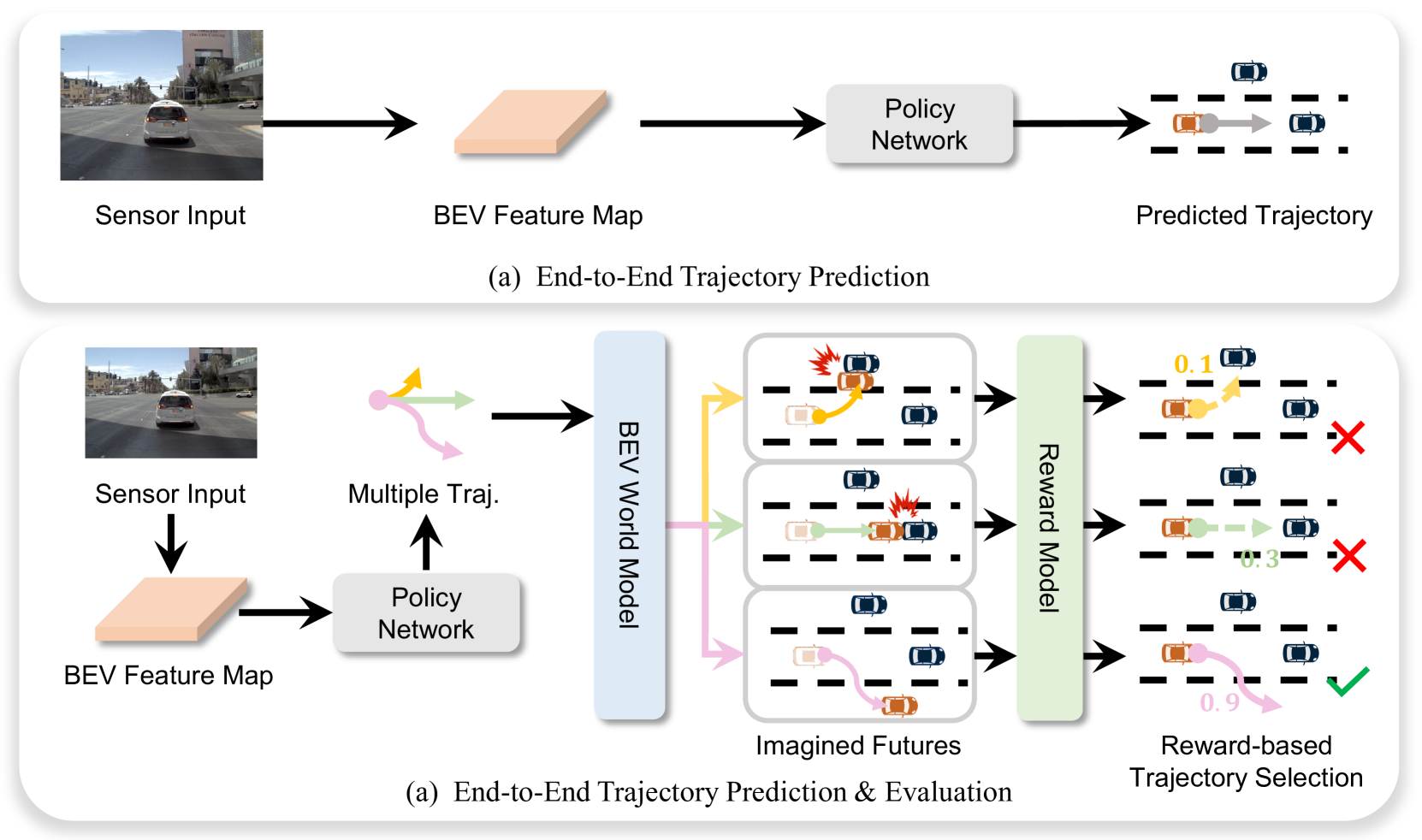
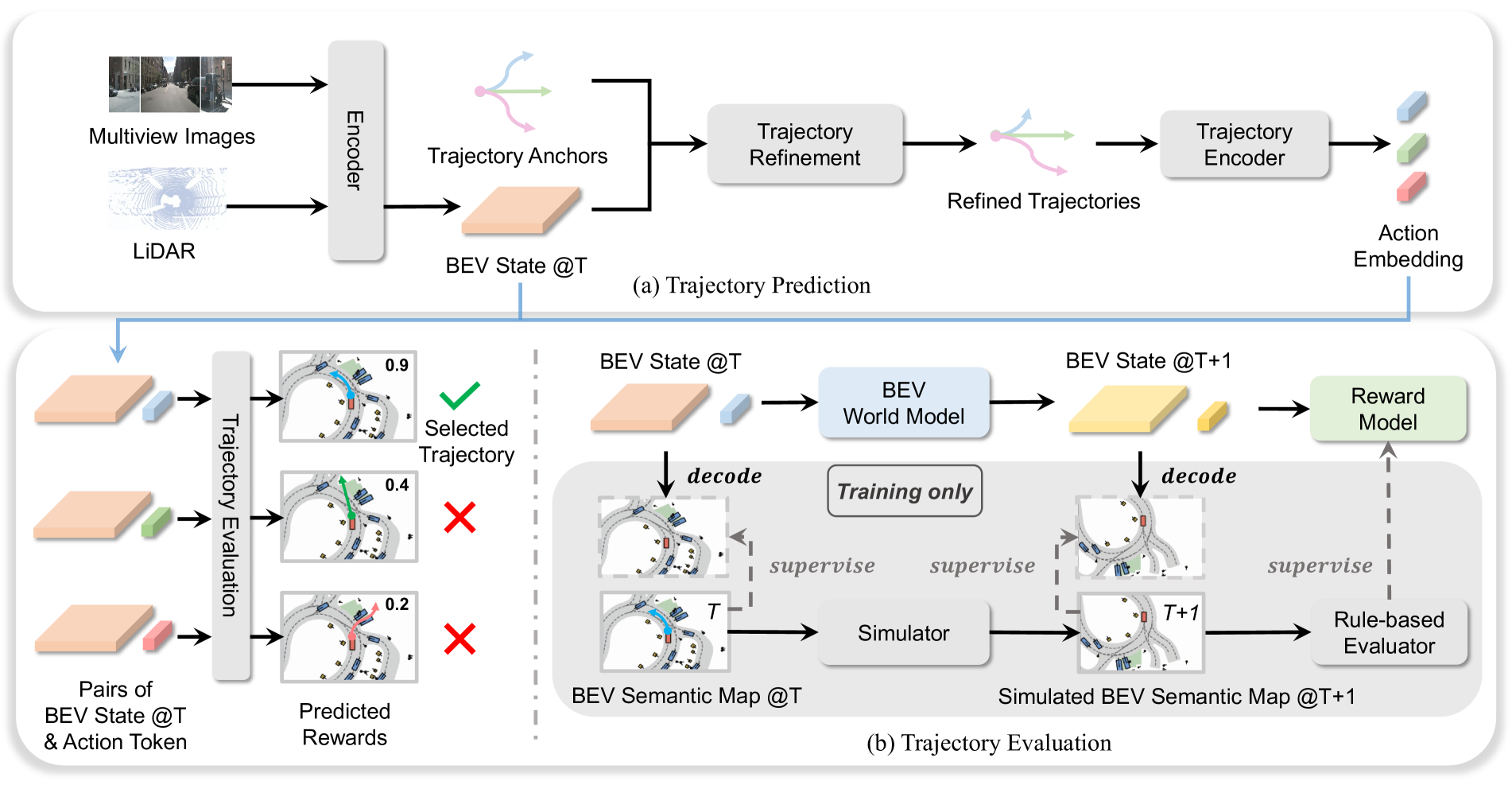
WoTE's architecture consists of four main components operating in sequence.
Perception Encoder: Multi-camera images are processed by a backbone network and lifted to BEV feature space using a standard BEV encoder. This produces a dense BEV feature map representing the current scene state, including ego vehicle position, other agents, lane markings, and obstacles.
Trajectory Predictor: Processes multi-view RGB images and LiDAR point clouds through a BEV encoder producing unified Bird's Eye View features. Uses pre-computed trajectory anchors from K-means clustering of expert driving patterns. A refinement network adjusts anchors based on current BEV state, producing N candidate trajectories.
BEV World Model: For each candidate trajectory, creates state-action pairs where action embedding corresponds to the trajectory. A Transformer Encoder recurrently predicts future BEV states for K time steps via: B^i_{t+k}, a^i_{t+k} = WorldModel(B^i_{t+k-1}, a^i_{t+k-1}). This captures temporal dependencies and realistic future scenarios while operating entirely in the compact BEV space, making it much faster than image-level world models.
Reward-Based Trajectory Evaluator: Evaluates trajectory quality using current and predicted future states with two complementary reward types: (1) Imitation Reward (r_im) measuring alignment with expert driving behavior, and (2) Simulation Rewards (r_sim) comprising five safety/efficiency metrics -- No Collisions, Drivable Area Compliance, Time-to-Collision, Comfort, and Ego Progress. Final reward: r_final = log(r_im + epsilon) + sum_j w_j log(r_sim^j + epsilon), where w_j are learned weights. The highest-rewarded trajectory is selected for execution.
BEV Space Supervision: A key challenge is that real-world datasets provide only one observed future per situation. WoTE addresses this using the nuPlan simulator to generate diverse future BEV semantic maps and rule-based rewards for multiple trajectory hypotheses. The BEV world model minimizes: L_BEV = FocalLoss(decode(B^i_{t+k}), B*_{t+k}). Complete training objective: L_total = L_BEV + L_sim_reward + L_im_reward + L_traj, circumventing single-future limitations of real-world data.
Results
| Benchmark | Metric | WoTE | Next Best | Improvement |
|---|---|---|---|---|
| NAVSIM | PDMS | 88.3 | 86.5 (Hydra-MDP) | +1.8 |
| Bench2Drive | Driving Score | 61.71 | 59.90 (TCP) | +1.81 |
| Bench2Drive | Success Rate | 31.36% | - | - |
| Latency (256 traj) | ms | 18.7 | - | - |
- NAVSIM SOTA: PDMS of 88.3, significantly outperforming Hydra-MDP (86.5) and DRAMA (85.5), with improvements spanning all evaluation metrics for comprehensive safety, rule compliance, and efficiency
- Ablation progression: Adding trajectory evaluation without future prediction improved PDMS from 81.0 to 83.2; incorporating BEV world model for future state prediction boosted performance to 85.6, demonstrating both components contribute significantly
- Reward composition: Combining imitation and simulation rewards is crucial -- imitation rewards excel in collision avoidance while simulation rewards better capture rule compliance and progress metrics
- Computational efficiency: Complete system achieves latency of only 18.7 milliseconds on NVIDIA L20 GPU when evaluating 256 trajectory candidates; BEV-space operations are orders of magnitude faster than diffusion-based image prediction
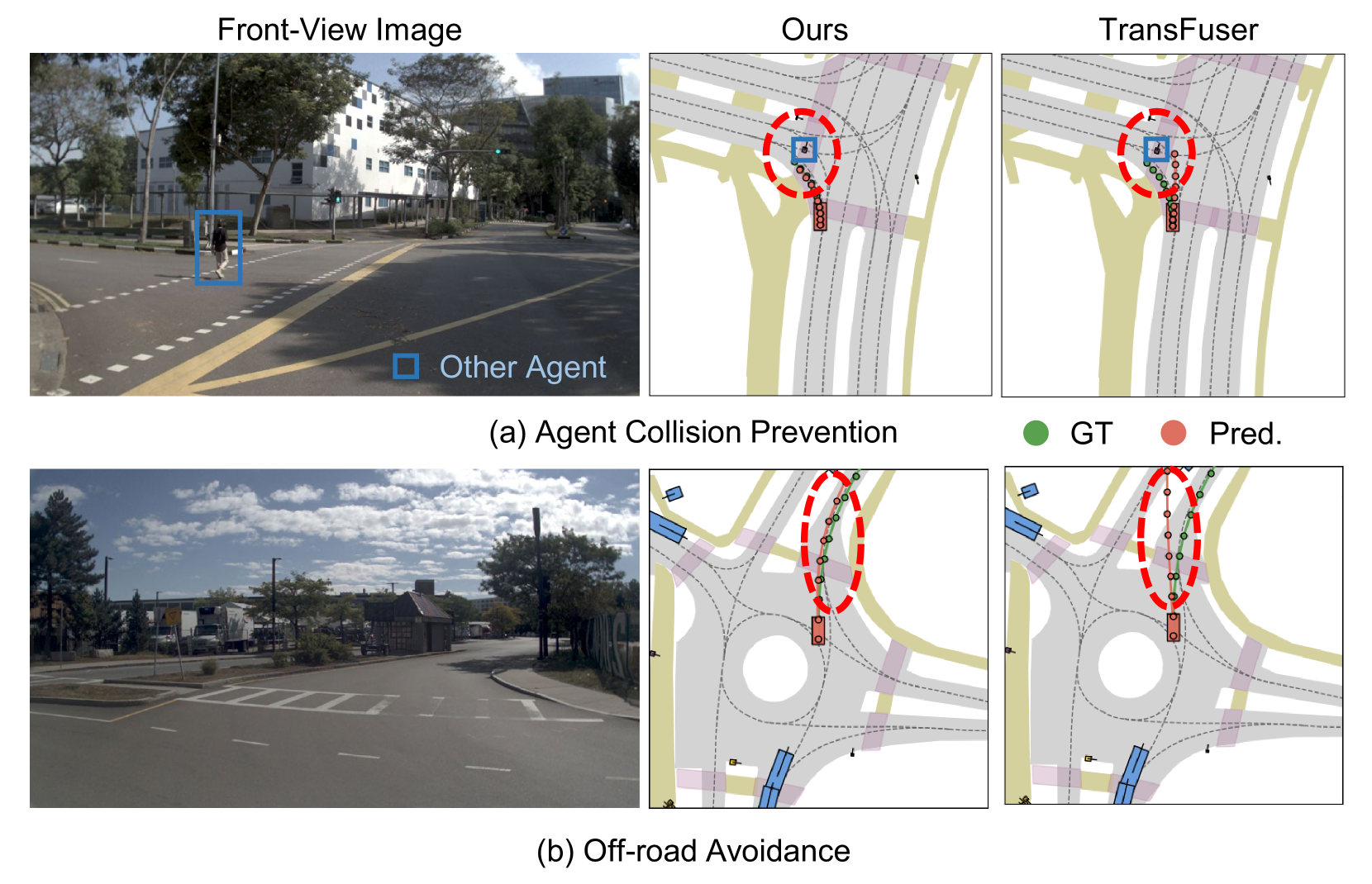
- Online evaluation improves trajectory safety: WoTE preserves multiple valid driving modes while filtering unsafe options and suppresses low-quality trajectories; the trajectory evaluation module assigns significantly lower rewards to unsafe or unreasonable trajectories, effectively eliminating them from selection
- BEV representation sufficiency validated: Compact top-down maps encode enough information for meaningful trajectory evaluation without full RGB rendering
- Scaling trajectory count improves performance with diminishing returns: PDMS improves from 84.5 (64 trajectories) to 85.4 (128) to 85.6 (256), with the default set at 256 for optimal balance
- Strong generalization: Handles unseen trajectory configurations and dynamic refinements, demonstrating robust applicability
Limitations & Open Questions
- No explicit language component -- this is a Vision + Action system that complements rather than competes with language-based VLAs. Integration with reasoning modules (like Senna's LVLM) is an open direction
- BEV world model fidelity depends on the quality of the BEV feature extraction and may not capture all relevant scene dynamics, particularly rare or complex agent behaviors
- Computational cost of simulating K trajectories, even in BEV space, scales linearly with K, requiring careful tuning of the compute-safety tradeoff for real-time deployment
- Evaluation is simulation-based (CARLA/NAVSIM) without real-world deployment validation, and the sim-to-real gap for BEV world models is unexplored
Connections
- Autonomous Driving
- Vision Language Action
- Planning
- Orion Holistic End To End Autonomous Driving By Vision Language Instructed Action Generation
- Simlingo Vision Only Closed Loop Autonomous Driving With Language Action Alignment
- Vad Vectorized Scene Representation For Efficient Autonomous Driving
- Transfuser Imitation With Transformer Based Sensor Fusion For Autonomous Driving