Drive-OccWorld: Driving in the Occupancy World
Overview
Drive-OccWorld introduces a vision-centric 4D occupancy forecasting world model that directly integrates with end-to-end planning. The core premise is that current end-to-end driving models lack sufficient "world knowledge" for forecasting dynamic environments, leading to poor generalization and safety robustness. By building an explicit world model that predicts future 3D occupancy states, the system can "think ahead" multiple steps before committing to a trajectory.
The framework operates through an auto-regressive architecture with three main components: a history encoder that builds BEV representations from multi-view cameras, a memory queue with novel conditional normalization that maintains temporal context while addressing semantic discrimination and motion awareness, and a world decoder that predicts future BEV embeddings conditioned on ego actions. The predicted future states feed into an occupancy-based planner that evaluates candidate trajectories against agent safety, road safety, and learned cost functions.
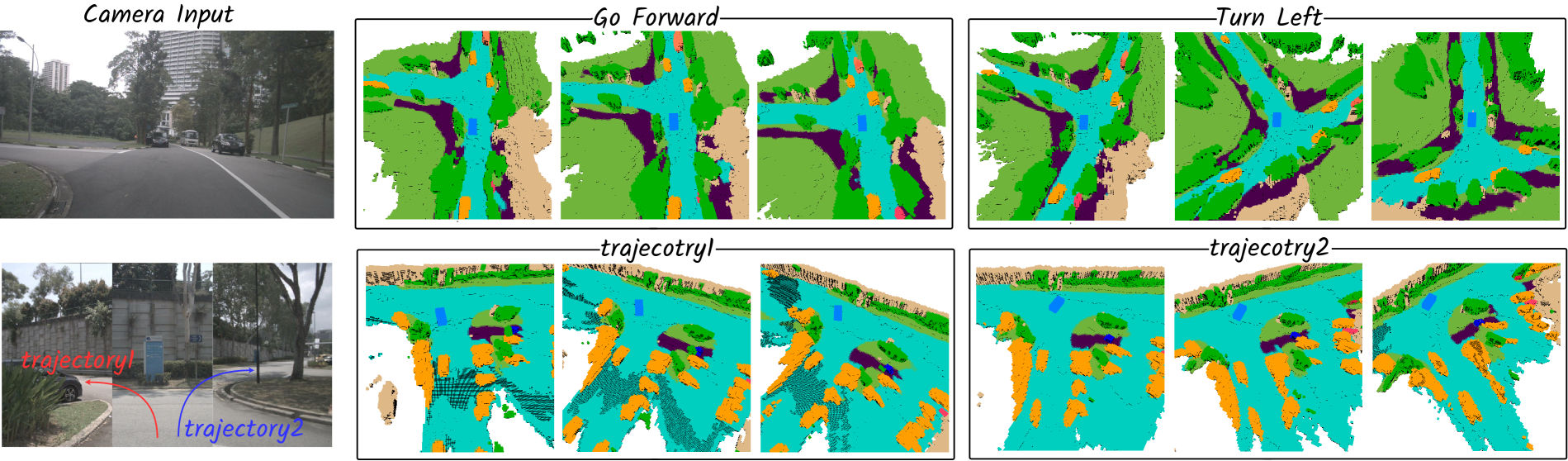
A key capability is action-controllable generation: the model can simulate different future scenarios based on various ego actions (velocity, steering angle, trajectory waypoints, high-level commands), functioning as a neural simulator. Drive-OccWorld achieves a 9.5 pp improvement in mIoU_f (future occupancy) and 6.5 pp improvement in VPQ_f over Cam4DOcc on nuScenes (36.3 vs 26.8 and 25.1 vs 18.6), a 33% reduction in L2 planning error at 1-second horizon compared to UniAD†, and is further validated on nuScenes-Occupancy and Lyft-Level5.
Key Contributions
- 4D occupancy world model for planning: First system to directly integrate vision-centric 4D occupancy forecasting with end-to-end planning through auto-regressive prediction
- Semantic-Conditional Normalization: Enhances semantic discriminability of BEV embeddings through adaptive affine transformations (gamma_s, beta_s) derived from voxel-wise semantic predictions encoded as one-hot embeddings
- Motion-Conditional Normalization: Accounts for ego-vehicle and agent movements through two sets of adaptive affine parameters -- one derived from ego-pose transformation matrices and one from a predicted voxel-wise 3D backward centripetal flow
- Action-controllable generation: Supports conditioning on velocity, steering angle, trajectory waypoints, and high-level commands via unified Fourier embeddings, enabling neural simulation
- Occupancy-based planning: Evaluates candidate trajectories using a three-component cost function (Agent-Safety, Road-Safety, Learned-Volume) that reasons about predicted future occupancy
Architecture / Method
┌──────────────────────────────────────────────────────────────┐
│ Drive-OccWorld │
│ │
│ Multi-view ┌───────────────────┐ │
│ Cameras ────►│ History Encoder │ │
│ │ (BEVFormer) │ │
│ └────────┬──────────┘ │
│ │ BEV embeddings │
│ ▼ │
│ ┌─────────────────────────────────────────────────┐ │
│ │ Memory Queue + Conditional Norm │ │
│ │ ┌─────────────────┐ ┌─────────────────────┐ │ │
│ │ │ Semantic-Cond. │ │ Motion-Cond. │ │ │
│ │ │ Normalization │ │ Normalization │ │ │
│ │ │ (voxel semantic │ │ (ego-pose xform │ │ │
│ │ │ discrimin.) │ │ + 3D flow) │ │ │
│ │ └─────────────────┘ └─────────────────────┘ │ │
│ └────────────────────┬────────────────────────────┘ │
│ │ │
│ Ego Actions ────┐ │ │
│ (vel, steer, │ ▼ │
│ waypoints) ┌──┴────────────────────────────┐ │
│ Fourier emb. │ World Decoder │ │
│ ────────────►│ (deform. self-attn + │ │
│ │ temporal cross-attn + │ Auto- │
│ │ conditional cross-attn) │ regressive │
│ └───────────┬───────────────────┘ loop │
│ │ Future BEV embeddings │
│ ▼ │
│ ┌───────────────────────┐ │
│ │ Occupancy Decoder │ │
│ │ ──► 3D semantic occ. │ │
│ │ ──► 3D flow │ │
│ └───────────┬───────────┘ │
│ ▼ │
│ ┌───────────────────────┐ │
│ │ Occupancy Planner │ │
│ │ Cost = Agent-Safety │ │
│ │ + Road-Safety │ │
│ │ + Learned-Volume │ │
│ └───────────┬───────────┘ │
│ ▼ │
│ Best Trajectory │
└──────────────────────────────────────────────────────────────┘
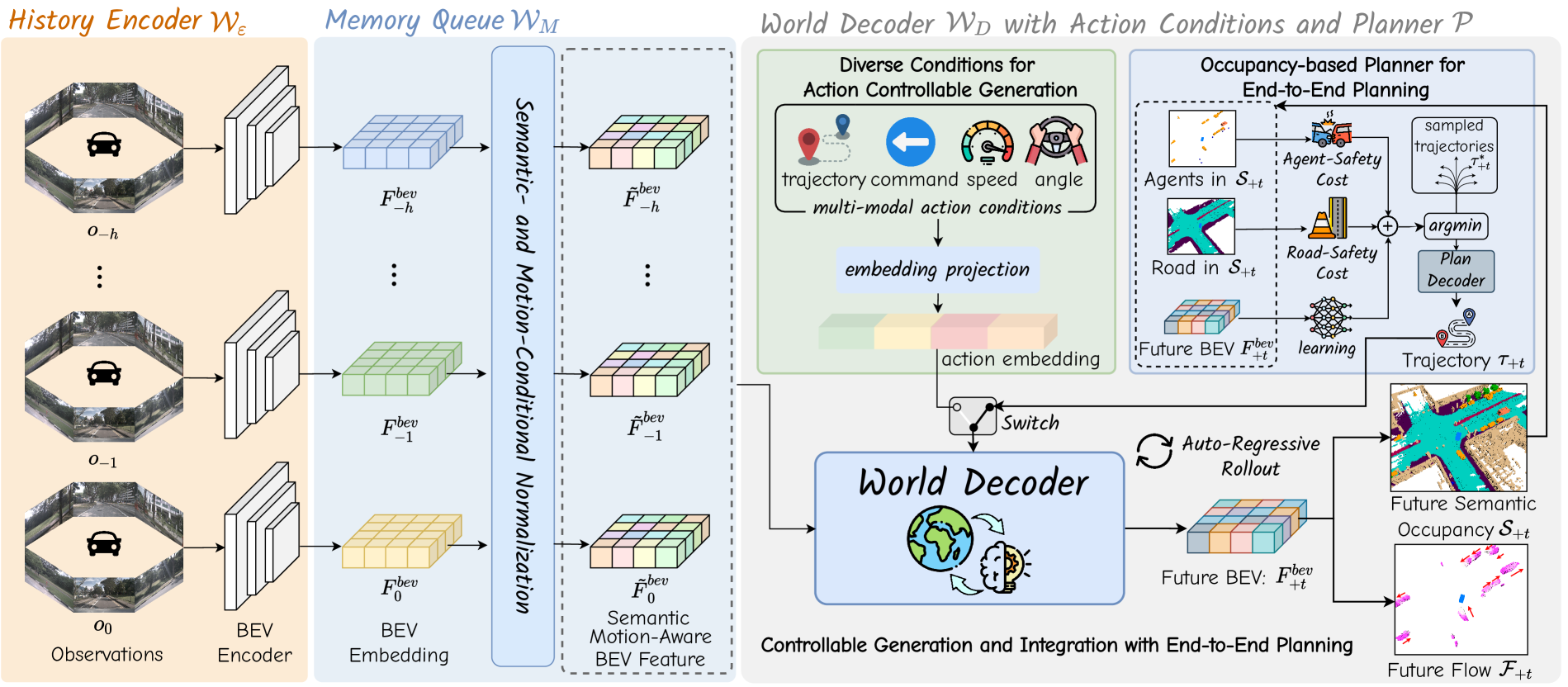
The architecture consists of three main stages operating in an auto-regressive loop:
History Encoder: Processes multi-view camera images using a BEVFormer-based architecture to extract multi-view geometry features and transform them into Bird's-Eye-View embeddings that capture spatial relationships across the scene.
Memory Queue with Conditional Normalization: Accumulates historical BEV features with two normalization mechanisms: - Semantic-Conditional Normalization: Applies layer normalization followed by adaptive affine transformations whose parameters are produced by a small convolution over voxel-wise semantic predictions (encoded as one-hot embeddings), enhancing the semantic discriminability of the BEV features - Motion-Conditional Normalization: Generates two sets of affine parameters -- one from an MLP encoding of ego-pose transformation matrices, and one from a predicted voxel-wise 3D backward centripetal flow -- to make the representation motion-aware for both ego and other agents
World Decoder: An auto-regressive transformer using deformable self-attention, temporal cross-attention, and conditional cross-attention to predict future BEV embeddings. Action conditioning is achieved through Fourier embeddings of ego actions (velocity, steering, trajectory waypoints, or high-level commands).
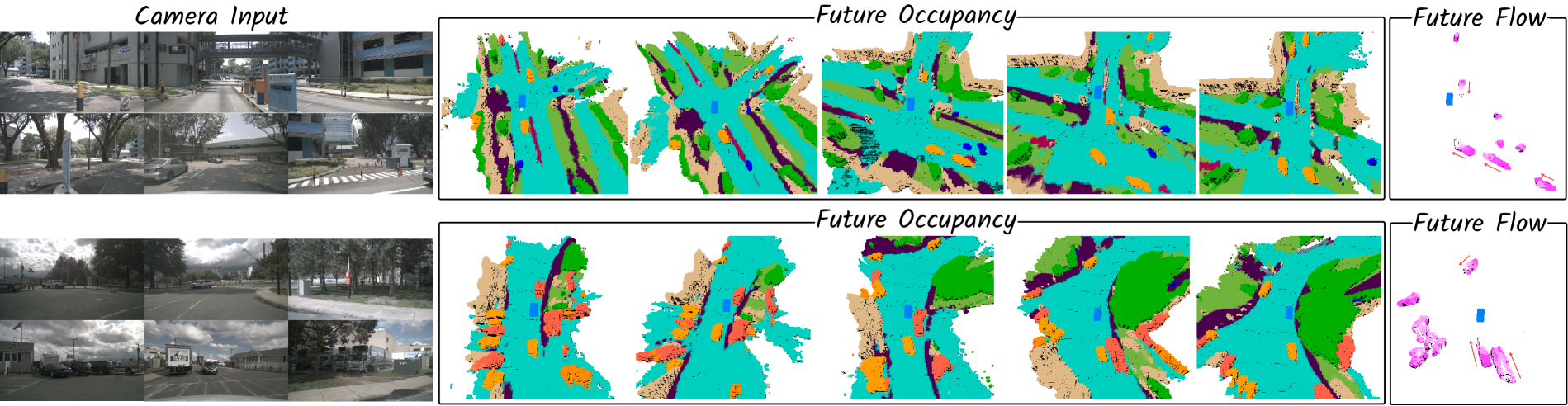
Occupancy-Based Planner: The predicted future BEV embeddings are decoded into semantic occupancy volumes and 3D flow. Candidate trajectories are evaluated using: - Agent-Safety Cost: Penalizes trajectories that intersect with predicted occupied voxels - Road-Safety Cost: Penalizes trajectories that leave drivable surface - Learned-Volume Cost: A learned cost function that captures complex safety patterns beyond explicit rules
Results
Occupancy Forecasting (nuScenes, vs Cam4DOcc)
| Method | mIoU_c | mIoU_f (2s) | mIoU~_f (weighted) | VPQ_f |
|---|---|---|---|---|
| PowerBEV-3D | 23.1 | 21.3 | 21.9 | 20.0 |
| Cam4DOcc | 31.3 | 26.8 | 28.0 | 18.6 |
| Drive-OccWorld A | 39.7 | 36.3 | 37.3 | 23.7 |
| Drive-OccWorld P | 39.8 | 36.3 | 37.4 | 25.1 |
Drive-OccWorld P achieves +9.5 pp in mIoU_f and +6.5 pp in VPQ_f over Cam4DOcc.
Planning Performance (nuScenes)
| Method | L2@1s ↓ | L2@2s ↓ | L2@3s ↓ | L2 Avg ↓ | Col@1s ↓ | Col@2s ↓ | Col@3s ↓ |
|---|---|---|---|---|---|---|---|
| UniAD† | 0.48 | 0.96 | 1.65 | 1.03 | 0.05 | 0.17 | 0.71 |
| VAD-Base† | 0.54 | 1.15 | 1.98 | 1.22 | 0.10 | 0.24 | 0.96 |
| OccNet† | 1.29 | 2.13 | 2.99 | 2.14 | 0.21 | 0.59 | 1.37 |
| Drive-OccWorld P† | 0.32 | 0.75 | 1.49 | 0.85 | 0.05 | 0.17 | 0.64 |
Drive-OccWorld P† achieves relative improvements of 33%, 22%, and 9.7% on L2@1s, L2@2s, and L2@3s compared to UniAD†. Ablation studies validate the normalization components and cost function terms, and the action-controllable generation demonstrates consistent and interpretable behavior across different ego actions.
Limitations & Open Questions
- Computational cost of 4D occupancy: Predicting full 3D occupancy volumes at multiple future timesteps is computationally expensive; real-time deployment may require aggressive optimization or sparse representations
- Autoregressive error accumulation: Multi-step predictions may degrade over longer horizons as errors compound through the auto-regressive loop
- Limited to camera-only input: The BEVFormer-based encoder processes only camera images; fusion with LiDAR could improve depth accuracy for occupancy prediction
Connections
- Extends the world model paradigm explored in Wote End To End Driving With Online Trajectory Evaluation Via Bev World Model (WoTE) with explicit 4D occupancy forecasting
- BEV encoder builds on Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers (BEVFormer) spatial cross-attention
- Planning approach complements trajectory-based methods like Planning Oriented Autonomous Driving (UniAD) and Vad Vectorized Scene Representation For Efficient Autonomous Driving (VAD) with occupancy-based reasoning
- Occupancy prediction connects to the broader scene representation discussion in Perception -- occupancy handles irregular objects that detection-based systems miss
- Evaluated on Nuscenes A Multimodal Dataset For Autonomous Driving (nuScenes)