OccFormer: Dual-path Transformer for Vision-based 3D Semantic Occupancy Prediction
Overview
Vision-based 3D semantic occupancy prediction aims to predict the semantic class and occupancy status of every voxel in a 3D volume surrounding the ego vehicle, using only camera images. Unlike object detection, which represents the scene as a sparse set of bounding boxes, occupancy prediction produces a dense volumetric representation that can capture arbitrary geometry -- critical for handling irregular obstacles like construction debris, fallen trees, or unusually shaped vehicles that bounding boxes cannot faithfully represent. The challenge is that naively applying 3D convolutions or full 3D attention to high-resolution voxel grids is computationally prohibitive.
OccFormer addresses this computational bottleneck through a dual-path transformer encoder that decomposes 3D processing into two complementary pathways: a local path that processes individual horizontal BEV slices (2D cross-sections at each height) to capture fine-grained local geometry, and a global path that operates on height-averaged BEV features to capture scene-level layout and long-range spatial context. This factorization avoids full 3D attention while still capturing both local detail and global structure. The paper also introduces a novel transformer-based occupancy decoder adapted from Mask2Former, with two key innovations: preserve-pooling (using max-pooling instead of interpolation for multi-scale features to avoid blurring sparse occupancy structures) and class-guided sampling (biasing attention point sampling toward underrepresented classes to handle severe class imbalance).
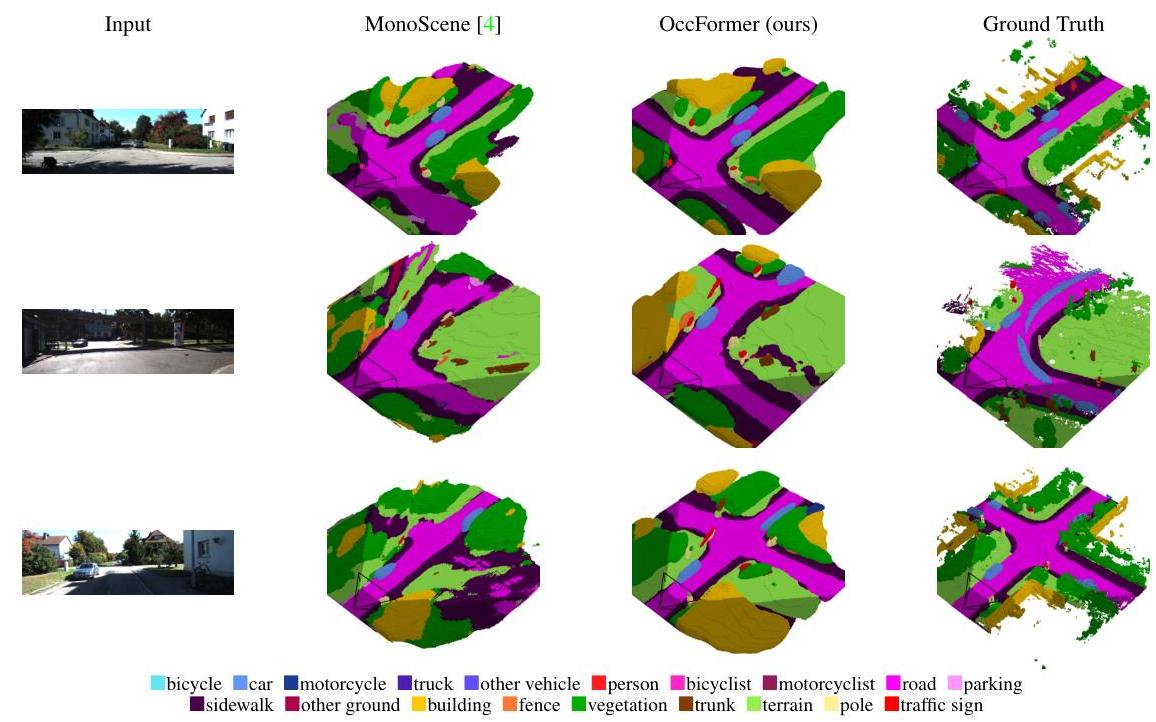
OccFormer achieved 12.32% mIoU on the SemanticKITTI benchmark (a 1.24% improvement over MonoScene, the prior camera-only SOTA) and 70.8% mIoU on nuScenes LiDAR segmentation, demonstrating that vision-only systems could approach LiDAR-based performance on dense 3D scene understanding. The dual-path design influenced subsequent occupancy prediction work and established that efficient decomposition of 3D processing -- rather than brute-force 3D convolution -- was the path to practical volumetric perception.
Key Contributions
- Dual-path transformer encoder: Decomposes 3D volume processing into local (per-slice 2D attention on horizontal BEV planes) and global (scene-level attention on height-averaged BEV) pathways, avoiding the cubic complexity of full 3D attention while retaining both fine-grained and long-range spatial reasoning
- Preserve-pooling for sparse 3D structures: Replaces standard bilinear interpolation in multi-scale feature fusion with max-pooling, preventing the blurring of thin and sparse occupancy structures (e.g., poles, pedestrians) that interpolation tends to destroy
- Class-guided sampling: Biases the sampling of attention points in the decoder toward underrepresented semantic classes, directly addressing the severe class imbalance in occupancy prediction where background/road dominate and safety-critical classes (pedestrians, cyclists) are rare
- Mask2Former adaptation for 3D occupancy: Adapts the Mask2Former masked-attention decoder architecture from 2D panoptic segmentation to 3D semantic occupancy, using learnable class queries to produce per-class occupancy masks
- State-of-the-art vision-based occupancy prediction: Achieved best camera-only results on SemanticKITTI (12.32% mIoU) and competitive results on nuScenes LiDAR segmentation (70.8% mIoU) at time of publication
Architecture / Method
┌────────────────────────────────────────────────────────────────┐
│ Multi-View Cameras ──► 2D Backbone (ResNet-50) │
│ ──► View Transformer (LSS lift-splat) ──► 3D Voxel Volume │
│ (X, Y, Z, C) │
└────────────────────────────┬───────────────────────────────────┘
│
┌──────────────▼──────────────┐
│ Dual-Path Transformer │
│ Encoder (×L) │
│ │
│ ┌────────────────────────┐ │
│ │ Local Path │ │
│ │ Slice along Z axis │ │
│ │ Z × 2D windowed attn │ │
│ │ on (X,Y) per slice │ │
│ └───────────┬────────────┘ │
│ │ + fuse │
│ ┌───────────▼────────────┐ │
│ │ Global Path │ │
│ │ Avg-pool along Z │ │
│ │ 2D attn on (X,Y) BEV │ │
│ │ Broadcast back to Z │ │
│ └───────────┬────────────┘ │
└──────────────┬──────────────┘
│
┌──────────────▼──────────────┐
│ Mask2Former Decoder │
│ Class queries + masked │
│ cross-attention │
│ ┌─────────────────────────┐ │
│ │ Preserve-pooling (max) │ │
│ │ Class-guided sampling │ │
│ └─────────────────────────┘ │
└──────────────┬──────────────┘
│
▼
┌──────────────────────────────┐
│ Semantic Occupancy Volume │
│ Per-voxel class predictions │
└──────────────────────────────┘
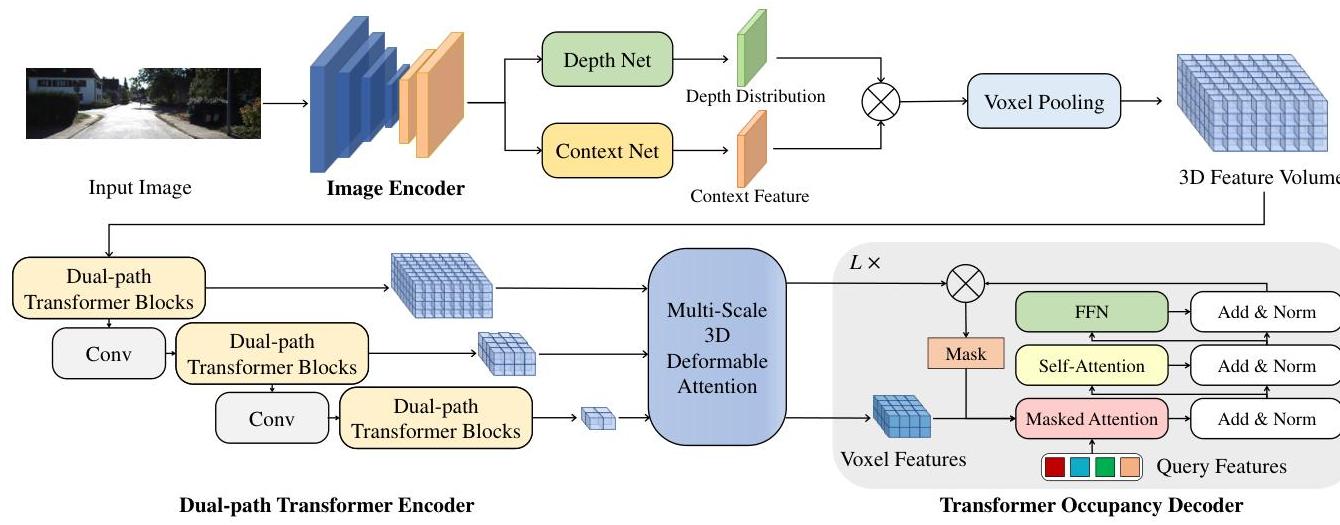
OccFormer operates in three stages: (1) a 2D image backbone extracts multi-view image features, (2) a view transformer lifts these features into a 3D voxel volume, and (3) the dual-path transformer encoder + Mask2Former decoder produce the final semantic occupancy predictions.
Image backbone and view transformer: Multi-view camera images are processed through a 2D backbone (EfficientNetB7 on SemanticKITTI, ResNet-101 on nuScenes, following the compared methods) to extract image features. A view transformer (following the LSS lift-splat paradigm from Lift Splat Shoot Encoding Images From Arbitrary Camera Rigs By Implicitly Unprojecting To 3D) predicts per-pixel depth distributions and lifts 2D features into a 3D voxel grid of shape (X, Y, Z, C).
Dual-path transformer encoder: The 3D voxel volume is processed through L encoder layers, each containing:
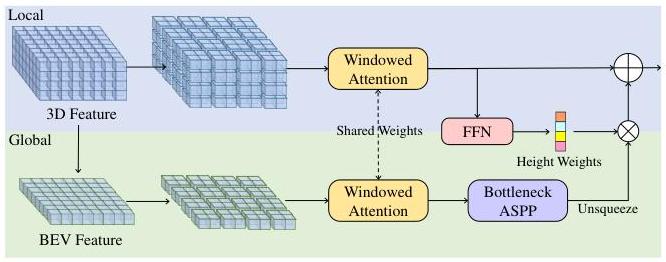
- Local path: The 3D volume is sliced along the height (Z) axis into Z independent 2D BEV planes of shape (X, Y, C). Each slice is processed with standard 2D windowed attention (following Swin Transformer), capturing fine-grained local spatial patterns within each horizontal cross-section. This avoids 3D attention entirely -- each slice is a standard 2D attention problem.
- Global path: The 3D volume is averaged along the height axis to produce a single BEV feature map (X, Y, C). This compressed representation is processed with 2D attention to capture long-range scene-level layout (road topology, building arrangements). The global features are then broadcast back to all height slices and fused with local features via addition or concatenation.
This decomposition reduces the complexity from O(X*Y*Z)^2 (full 3D attention) to O(Z * (X*Y)^2 + (X*Y)^2), a dramatic reduction for typical grid sizes.
Mask2Former occupancy decoder: The decoder uses learnable semantic class queries (one per class) that attend to multi-scale 3D features from the encoder through masked cross-attention. Key modifications for 3D occupancy: - Preserve-pooling: When constructing the multi-scale feature pyramid, max-pooling replaces bilinear interpolation for downsampling. Since occupancy features are inherently sparse and binary-like (occupied vs. free), interpolation averages away thin structures. Max-pooling preserves the presence of occupied voxels even at coarse scales. - Class-guided sampling: During masked cross-attention, the set of sampled 3D reference points is biased toward voxels belonging to rare classes. Standard uniform sampling would overwhelmingly sample free-space and road voxels, giving the decoder little signal for small objects. Class-guided sampling ensures each class query attends to a sufficient number of relevant voxels.
The decoder outputs per-class binary occupancy masks, which are combined to produce the final semantic occupancy volume.
Results
SemanticKITTI Semantic Scene Completion
| Method | Input | mIoU (%) | IoU (%) |
|---|---|---|---|
| OccFormer | Camera | 12.32 | 34.53 |
| MonoScene | Camera | 11.08 | 34.16 |
| TPVFormer | Camera | 11.26 | 34.25 |
| LMSCNet | LiDAR | 17.01 | 56.72 |
| JS3CNet | LiDAR | 23.80 | 56.60 |
- OccFormer improved camera-only mIoU by 1.24% over MonoScene and 1.06% over TPVFormer on SemanticKITTI, a meaningful gain given the difficulty of the benchmark
- Significant improvements on thin/rare classes: bicycle (+3.2%), motorcycle (+2.1%), and traffic sign categories where preserve-pooling and class-guided sampling have the most impact
- Still a substantial gap to LiDAR methods (17-24% mIoU), reflecting the fundamental depth ambiguity of monocular input
nuScenes LiDAR Segmentation
| Method | Input | mIoU (%) |
|---|---|---|
| OccFormer | Camera | 70.8 |
| Cylinder3D++ | LiDAR | 76.1 |
| PolarNet | LiDAR | 71.0 |
- OccFormer reached 70.8% mIoU on nuScenes LiDAR segmentation using only cameras, approaching LiDAR-based PolarNet (71.0%) -- a significant milestone for camera-only volumetric perception
Ablation Highlights
- Removing the global path (local-only) drops mIoU by ~0.53 pp (13.46 → 12.93), confirming that scene-level context is important beyond local geometry
- Replacing preserve-pooling with trilinear interpolation drops mIoU by ~0.52 pp (12.13 → 11.61 with uniform sampling), with the largest degradation on thin/sparse structures
- Switching from class-guided to uniform sampling drops mIoU by ~1.33 pp (13.46 → 12.13 with max-pool), with rare classes affected most; the paper describes this as the most impactful single modification
Limitations & Open Questions
- The gap to LiDAR methods remains large (~5-11% mIoU on SemanticKITTI), suggesting that depth ambiguity is a fundamental bottleneck for camera-only occupancy prediction that architectural innovations alone cannot close
- Computational cost is still substantial despite the dual-path decomposition -- the full voxel grid processing limits real-time applicability compared to sparse representations like GaussianFormer
- The method was evaluated only on static single-frame occupancy; temporal fusion across frames could improve predictions for occluded regions and moving objects
- Class-guided sampling requires ground-truth class distributions during training, limiting its applicability to self-supervised or pseudo-label settings
- The Mask2Former decoder adds significant complexity; simpler per-voxel classifiers may suffice for some deployment scenarios
Connections
Related papers in the wiki: - Lift Splat Shoot Encoding Images From Arbitrary Camera Rigs By Implicitly Unprojecting To 3D -- OccFormer uses the LSS lift-splat paradigm for its view transformer to construct the initial 3D voxel volume - Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers -- BEVFormer's query-based BEV approach is a complementary paradigm; OccFormer extends BEV-style reasoning to full 3D occupancy - Planning Oriented Autonomous Driving -- UniAD consumes occupancy-style features; OccFormer provides a stronger occupancy backbone - Gaussianformer Scene As Gaussians For Vision Based 3D Semantic Occupancy Prediction -- GaussianFormer proposes sparse Gaussians as a more memory-efficient alternative to OccFormer's dense voxel processing - Gaussianformer 2 Probabilistic Gaussian Superposition For Efficient 3D Occupancy Prediction -- builds on the efficient occupancy representation direction, achieving 5-6x memory reduction vs. OccFormer-class methods - Drive Occworld Driving In The Occupancy World -- extends occupancy prediction to 4D forecasting for planning, building on representations like OccFormer - Gaussianworld Gaussian World Model For Streaming 3D Occupancy Prediction -- streaming occupancy as temporal extension of per-frame methods like OccFormer - Perception -- broader context on the occupancy prediction paradigm within autonomous driving perception