Overview
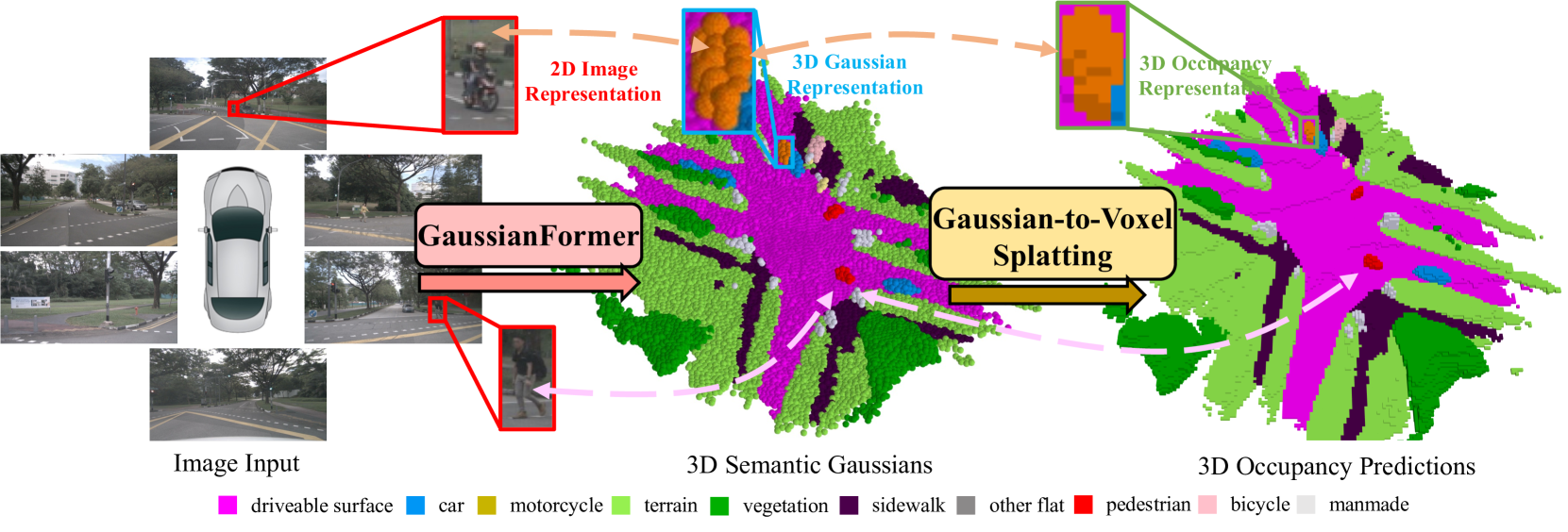
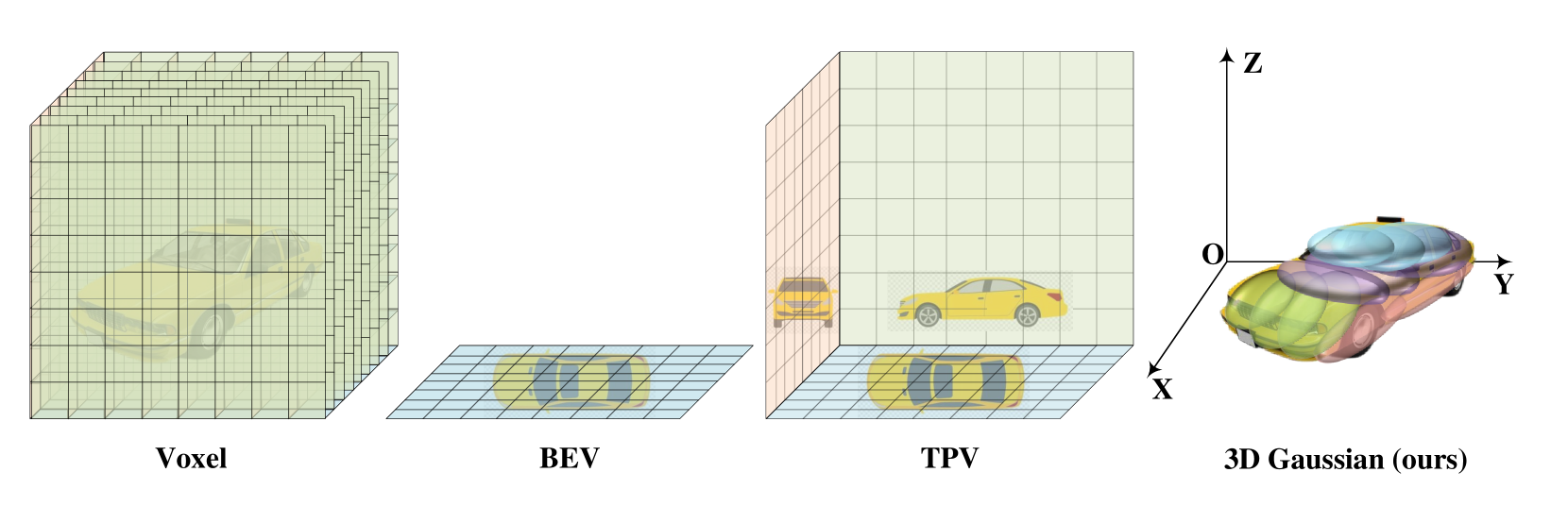
GaussianFormer introduces a fundamentally different scene representation for 3D semantic occupancy prediction: instead of dense voxel grids, scenes are modeled as sparse sets of 3D semantic Gaussians. Each Gaussian encodes position (mean), shape (covariance), and semantic features, enabling adaptive modeling where large Gaussians cover empty regions and small Gaussians capture fine object details. A transformer-based decoder iteratively refines Gaussian properties through self-encoding (local 3D sparse convolutions) and cross-attention to multi-view image features. The sparse Gaussians are then splatted into dense voxel occupancy predictions via efficient Gaussian-to-voxel aggregation. The key result: GaussianFormer uses only 17.8% - 24.8% of the memory required by existing methods, trading modest accuracy (~2% mIoU) for dramatic efficiency gains.
Key Contributions
- Sparse 3D semantic Gaussian representation: Replaces dense voxel grids with adaptive Gaussians that allocate representational capacity according to scene complexity
- Transformer-based Gaussian refinement: Iterative decoder with 3D sparse convolution self-encoding and deformable cross-attention to multi-view image features across 6 refinement blocks
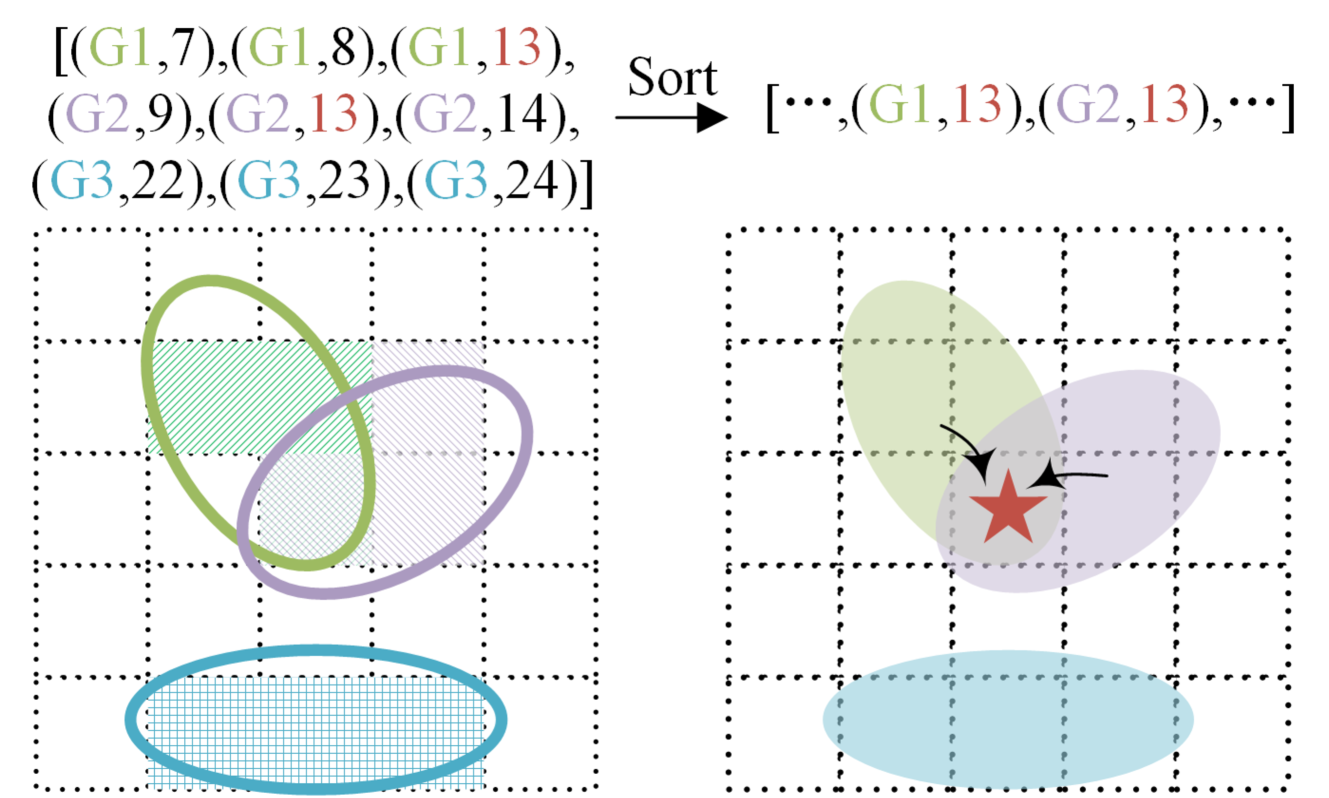
- Gaussian-to-voxel splatting: Efficient conversion from sparse Gaussians to dense occupancy by aggregating weighted semantic contributions from nearby Gaussians
- Memory efficiency: 5-6x memory reduction vs. dense voxel methods with competitive accuracy
Architecture / Method
┌──────────────────────────────────────────────────────────────────┐
│ GaussianFormer Pipeline │
│ │
│ ┌──────────┐ ┌────────────────┐ │
│ │ Surround │───►│ ResNet-50 + │──► Multi-scale 2D features │
│ │ Cameras │ │ FPN │ │
│ └──────────┘ └───────┬────────┘ │
│ │ │
│ ┌────────────────────┐ │ │
│ │ Learnable Gaussian │ │ │
│ │ Queries (20K) │ │ │
│ │ (mean, cov, sem) │ │ │
│ └─────────┬──────────┘ │ │
│ │ │ │
│ ▼ ▼ │
│ ┌─────────────────────────────────────────┐ │
│ │ Iterative Decoder (x6 blocks) │ │
│ │ ┌────────────────────────────────────┐ │ │
│ │ │ 1. Self-encoding: 3D sparse conv │ │ │
│ │ │ (local Gaussian interactions) │ │ │
│ │ ├────────────────────────────────────┤ │ │
│ │ │ 2. Image cross-attention: │ │ │
│ │ │ 3D ref pts ──► deformable attn │ │ │
│ │ │ on multi-view feature maps │ │ │
│ │ ├────────────────────────────────────┤ │ │
│ │ │ 3. MLP refinement: │ │ │
│ │ │ Update mean, cov, semantics │ │ │
│ │ └────────────────────────────────────┘ │ │
│ └─────────────────────┬───────────────────┘ │
│ │ │
│ Refined 3D Gaussians │
│ │ │
│ ┌─────────────────────▼───────────────────┐ │
│ │ Gaussian-to-Voxel Splatting │ │
│ │ Each voxel aggregates weighted semantic │ │
│ │ contributions from nearby Gaussians │ │
│ │ (weight = Gaussian PDF at voxel center) │ │
│ └─────────────────────┬───────────────────┘ │
│ ▼ │
│ Dense Occupancy Grid │
└──────────────────────────────────────────────────────────────────┘
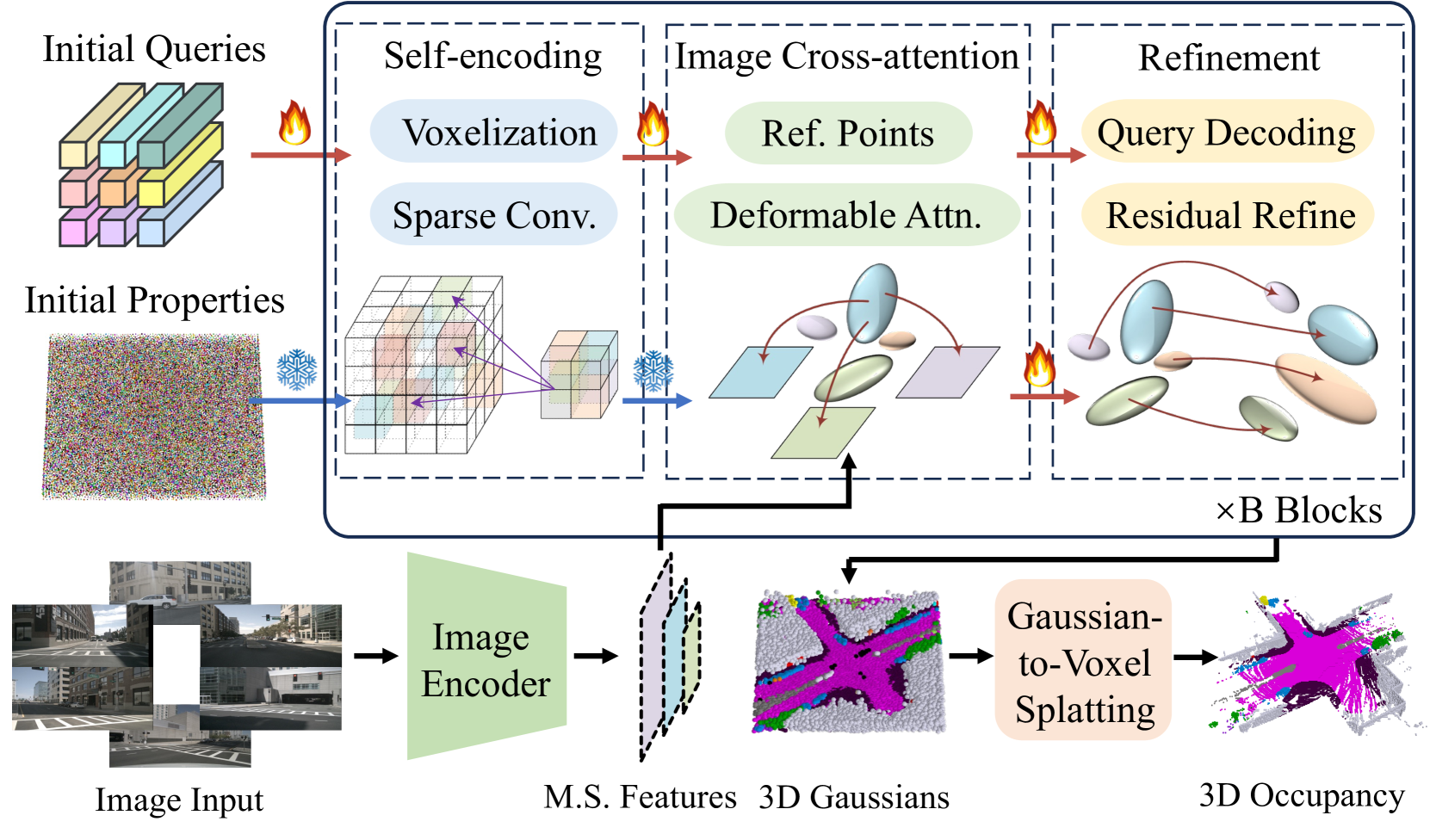
The pipeline:
- Image Encoder: ResNet-50 with FPN extracts multi-scale features from surround-view cameras
- Gaussian Initialization: Learnable 3D Gaussian parameters (mean, covariance, semantic logits) initialized in the scene volume
- Iterative Refinement (6 decoder blocks): - Self-encoding: 3D sparse convolutions capture local Gaussian-to-Gaussian interactions - Image cross-attention: 3D reference points projected onto multi-view feature maps via deformable attention - Refinement: MLP updates mean, covariance, and semantic logits
- Gaussian-to-Voxel Splatting: Each voxel aggregates weighted semantic contributions from Gaussians whose influence reaches it, with weights determined by Gaussian probability density at the voxel center
Results
| Method | mIoU | Memory (vs. GaussianFormer) |
|---|---|---|
| SurroundOcc | 20.30% | not in paper efficiency table |
| OccFormer | 19.03% | not in paper efficiency table |
| GaussianFormer | 19.10% | 1.00x (baseline) |
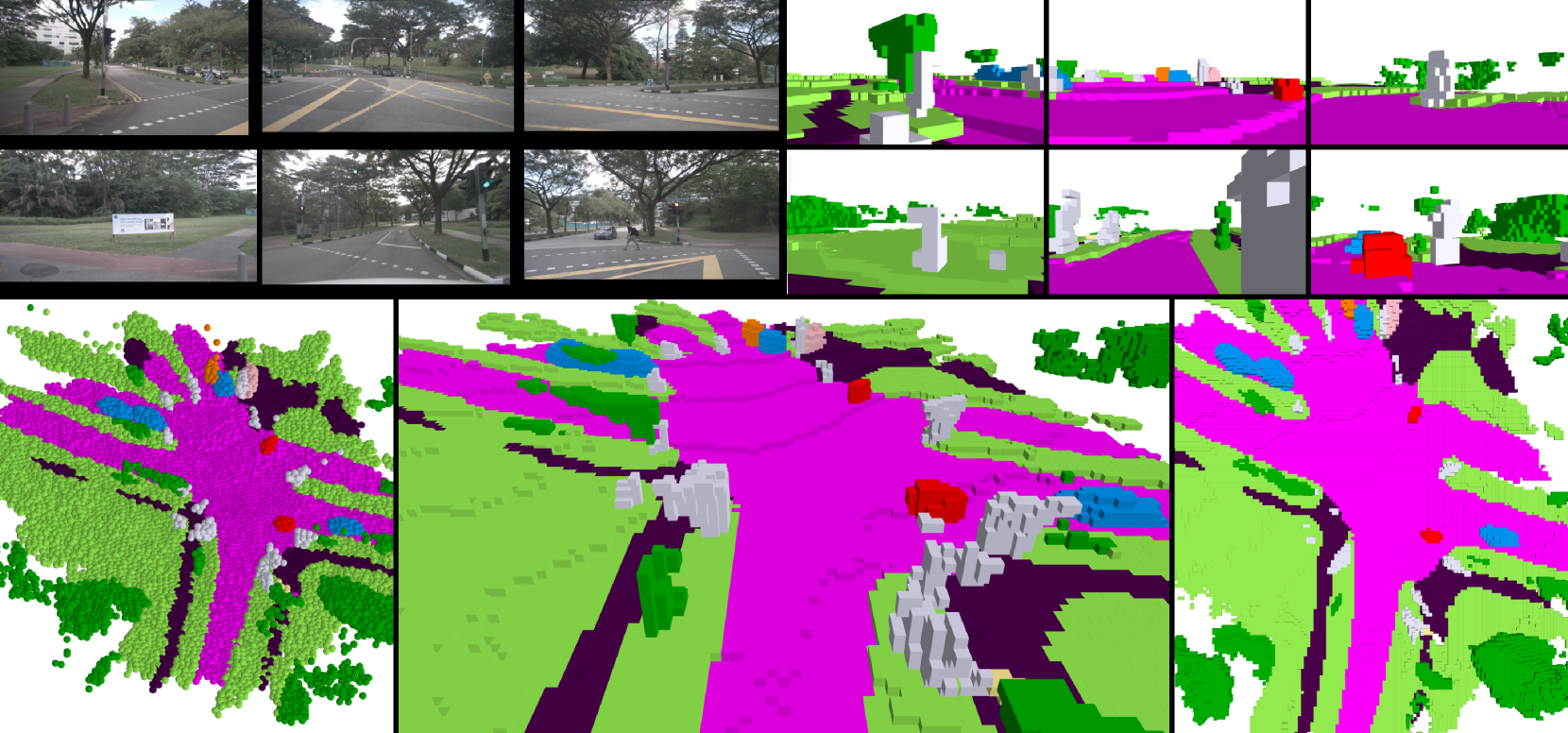
GaussianFormer also achieves 18.1% mAP on 3D detection as a byproduct. The Gaussian representation naturally provides object-level grouping without explicit detection heads.
Limitations
- ~2% mIoU gap vs. dense methods (SurroundOcc, OccFormer) -- the efficiency comes at an accuracy cost
- Gaussian initialization is learned but static; adaptive initialization based on scene complexity could improve results
- Evaluated primarily on nuScenes and KITTI-360; generalization to other domains not demonstrated
- The splatting operation assumes Gaussians have limited spatial extent; very large objects may require many Gaussians
Connections
- Extends the Gaussian representation paradigm used in Gaussianlss Toward Real World Bev Perception With Depth Uncertainty Via Gaussian Splatting for BEV perception to full 3D occupancy
- Related to Gaussianworld Gaussian World Model For Streaming 3D Occupancy Prediction which uses 3D Gaussians for temporal occupancy world modeling
- Complements dense occupancy methods in Drive Occworld Driving In The Occupancy World by offering an efficient alternative representation
- Part of the broader Gaussian representation trend alongside Driving Gaussian Composite Gaussian Splatting For Surrounding Dynamic Driving Scenes
- Perception -- efficient 3D scene representation for driving