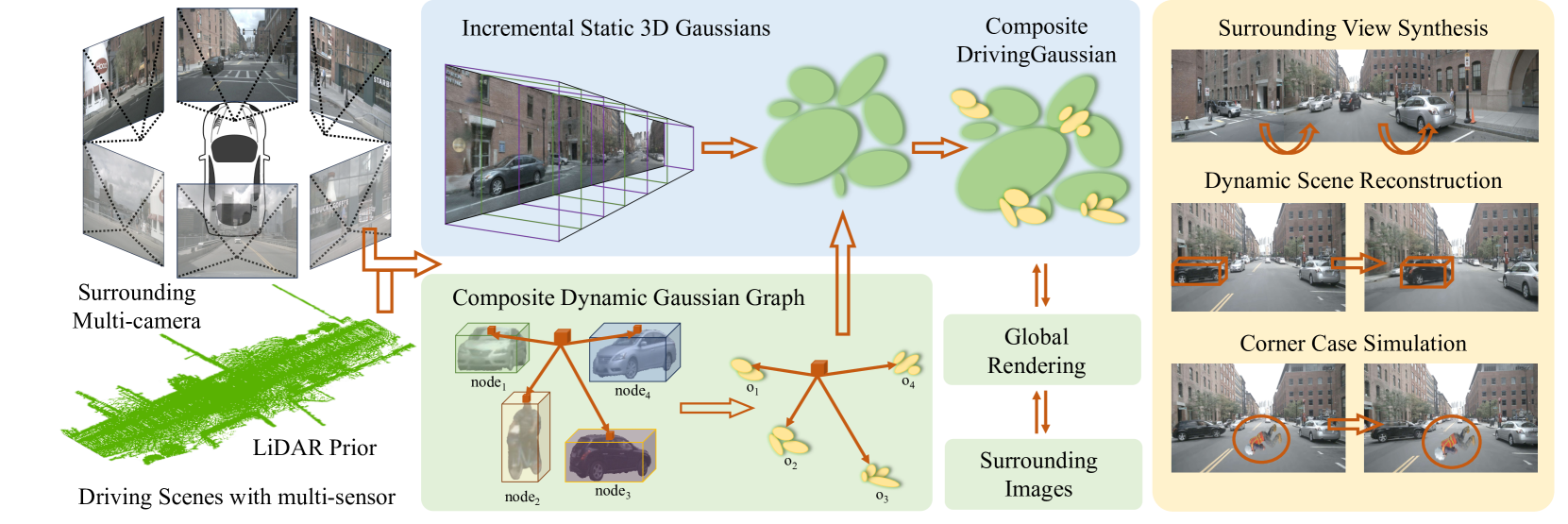
Overview
DrivingGaussian addresses photorealistic 3D scene reconstruction for dynamic autonomous driving environments using Gaussian splatting. The core challenge is that driving scenes contain both large-scale static backgrounds (buildings, roads, trees) and dynamic foreground objects (vehicles, pedestrians) that move independently. DrivingGaussian decomposes scenes into these two components and reconstructs each separately: Incremental Static 3D Gaussians (IS3G) handle backgrounds through depth-bin-based sequential processing, while a Composite Dynamic Gaussian Graph (CDGG) models each moving object as a graph node with its own Gaussians and transformation parameters. LiDAR point clouds provide strong geometric priors for initialization. With 398+ citations, this is one of the most influential works in applying Gaussian splatting to autonomous driving simulation.
Key Contributions
- Incremental Static 3D Gaussians (IS3G): Sequential depth-bin processing of large-scale backgrounds prevents scale confusion and artifacts in distant regions by building the scene incrementally from near to far
- Composite Dynamic Gaussian Graph (CDGG): Graph-based representation where each node models an individual moving object with its own Gaussians, transformation matrix, center coordinate, and orientation -- enabling independent motion modeling
- LiDAR-prior integration: Multi-frame LiDAR sweeps provide geometric priors for Gaussian initialization, refined through dense bundle adjustment
- Unified loss function: Combines Tile Structural Similarity (TSSIM), robust outlier loss, and LiDAR-based geometric supervision for high-quality reconstruction
Architecture / Method
┌──────────────────────────────────────────────────────────────┐
│ DrivingGaussian: Composite Scene Reconstruction │
│ │
│ Input: Multi-Camera Images + LiDAR Point Clouds │
│ │
│ ┌────────────────────────────────────────────────┐ │
│ │ 1. Incremental Static 3D Gaussians (IS3G) │ │
│ │ │ │
│ │ Scene volume divided into N depth bins: │ │
│ │ ┌──────┐ ┌──────┐ ┌──────┐ ┌──────┐ │ │
│ │ │Near │─►│Mid-1 │─►│Mid-2 │─►│ Far │ │ │
│ │ │Bin 1 │ │Bin 2 │ │Bin 3 │ │Bin N │ │ │
│ │ └──────┘ └──────┘ └──────┘ └──────┘ │ │
│ │ (position priors propagated near ──► far) │ │
│ │ LiDAR provides initial Gaussian centers │ │
│ └─────────────────────┬──────────────────────────┘ │
│ │ │
│ ┌─────────────────────┼──────────────────────────┐ │
│ │ 2. Composite Dynamic Gaussian Graph (CDGG) │ │
│ │ │ │
│ │ ┌───────┐ ┌───────┐ ┌───────┐ │ │
│ │ │Car A │ │Car B │ │Ped C │ ... │ │
│ │ │Gauss │ │Gauss │ │Gauss │ │ │
│ │ │+T(t) │ │+T(t) │ │+T(t) │ │ │
│ │ └───┬───┘ └───┬───┘ └───┬───┘ │ │
│ │ └──────────┼──────────┘ │ │
│ │ Graph edges (temporal + spatial) │ │
│ └─────────────────────┬──────────────────────────┘ │
│ │ │
│ ┌─────────────────────▼──────────────────────────┐ │
│ │ 3. Composite Rendering │ │
│ │ Static Gaussians + Dynamic Gaussians │ │
│ │ ──► Differentiable 3DGS Splatting │ │
│ │ ──► Multi-camera view synthesis │ │
│ │ Loss: Tile-SSIM (TSSIM) + Outlier + LiDAR geometric │ │
│ └────────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────┘
The framework operates in three stages:
1. Static Background (IS3G): - Scene volume uniformly divided into N depth-based bins (near to far) - Each bin processed incrementally, with position priors propagated from preceding bins - Prevents scale confusion where distant objects receive inappropriate Gaussian sizes - LiDAR sweeps provide initial 3D point positions for Gaussian centers
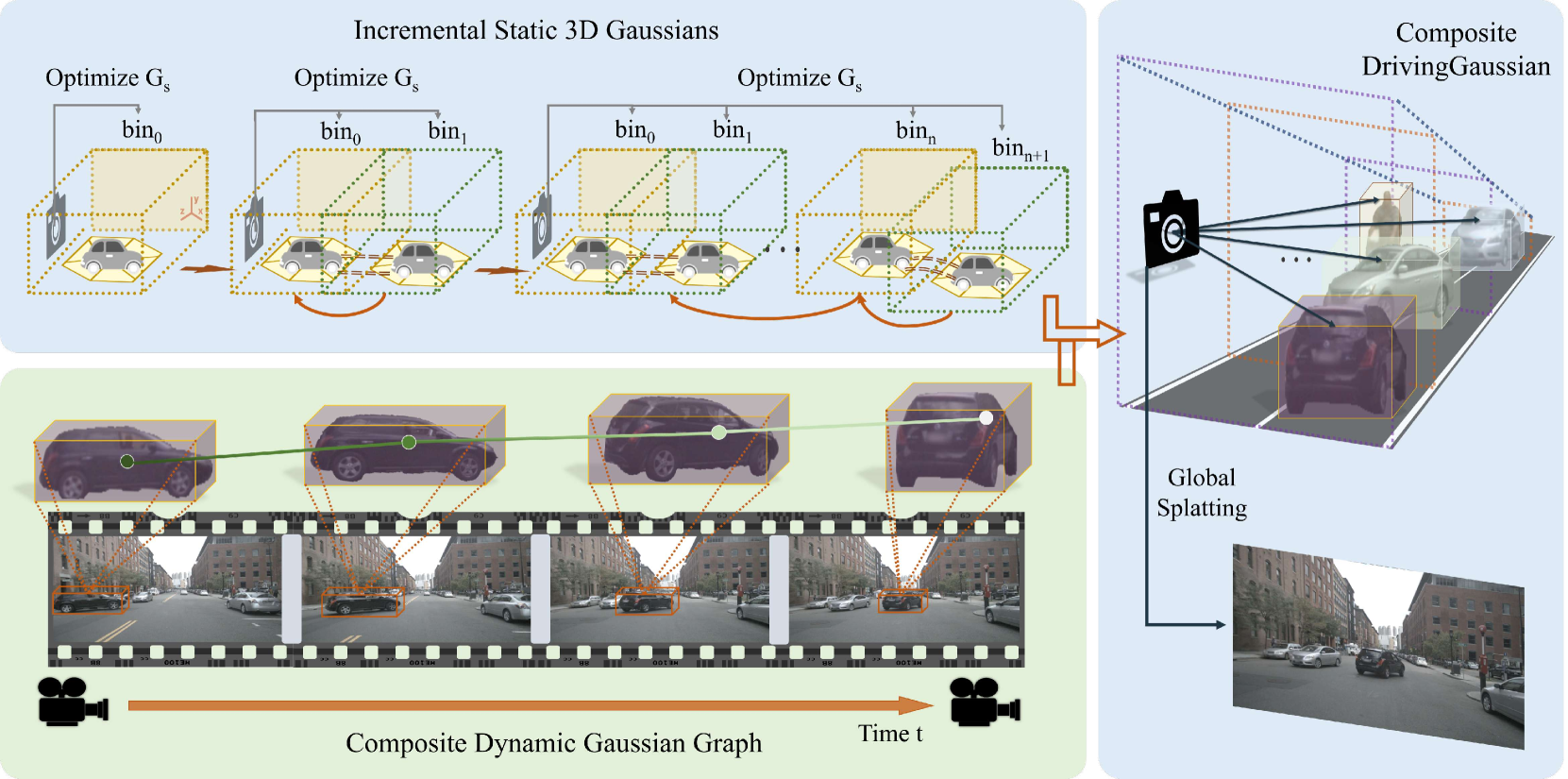
2. Dynamic Objects (CDGG): - Each tracked object represented as a graph node containing: Gaussians, per-timestep transformation matrix, center coordinate, and orientation - Objects can be independently animated, repositioned, or removed for scene editing - Temporal consistency maintained through graph structure
3. Composite Rendering: - Static and dynamic Gaussians composited into unified scene - Differentiable 3D Gaussian splatting renders multi-camera views - Supervised by surrounding camera images from the driving dataset

Results
| Dataset | PSNR | SSIM | LPIPS |
|---|---|---|---|
| nuScenes | 28.74 | 0.865 | 0.237 |
| KITTI-360 | 25.62 | 0.868 | -- |
DrivingGaussian significantly outperforms NeRF-based methods and baseline 3D Gaussian splatting on both datasets. Rendering speed is approximately 0.96 seconds per frame (not yet real-time but much faster than NeRF alternatives).

Qualitative results show photorealistic multi-camera consistent rendering, accurate dynamic object reconstruction without ghosting or blurring, and superior geometric detail preservation compared to baselines.
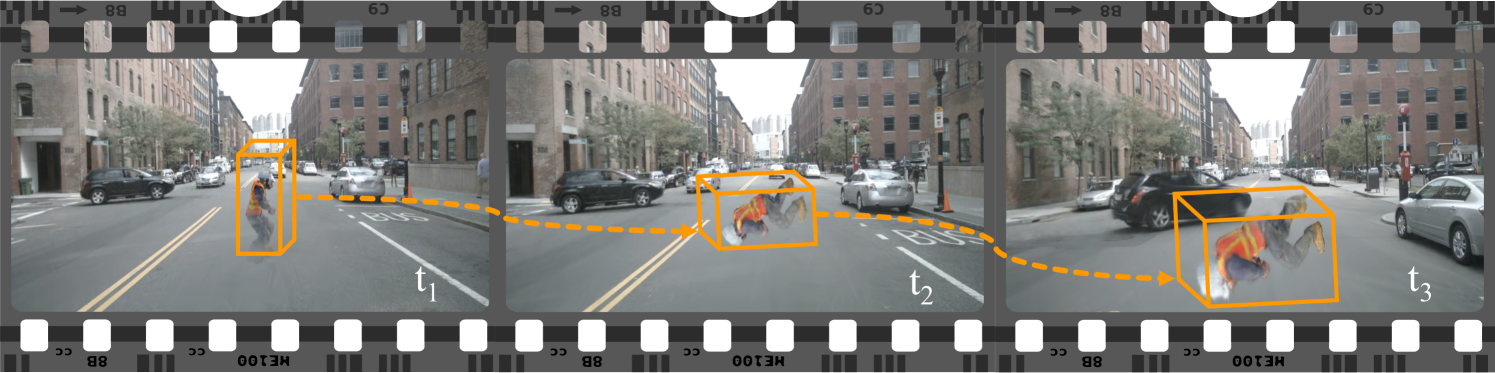
The scene editing capability (reposition/remove dynamic objects) enables corner case simulation -- generating rare scenarios for training and evaluation by manipulating object trajectories.
Limitations
- Rendering speed (~0.96s/frame) not yet suitable for real-time simulation
- Requires tracked object annotations for dynamic object modeling; fully automatic scene decomposition not addressed
- LiDAR dependency limits applicability to camera-only settings
- Scene editing is constrained to object-level manipulation; generating entirely new objects or behaviors requires additional methods
Connections
- Part of the Gaussian representation trend in driving alongside Gaussianformer Scene As Gaussians For Vision Based 3D Semantic Occupancy Prediction (occupancy) and Gaussianlss Toward Real World Bev Perception With Depth Uncertainty Via Gaussian Splatting (BEV perception)
- Complements Cosmos World Foundation Model Platform For Physical Ai which generates synthetic training data through learned world models rather than reconstructive approaches
- Scene editing capability addresses the simulation gap discussed in Autonomous Driving for rare scenario coverage
- Related to Carla An Open Urban Driving Simulator as an alternative approach to driving simulation -- data-driven reconstruction vs. handcrafted environments
- Perception -- 3D scene reconstruction and representation