SparseOcc: Rethinking Sparse Latent Representation for Vision-Based Semantic Occupancy Prediction
Overview
Dense 3D occupancy prediction from multi-view cameras has become a key perception task for autonomous driving, but most methods process the full voxel volume -- including the vast majority of voxels that are empty. SparseOcc rethinks this by operating exclusively on non-empty (occupied) voxels in a sparse latent space, dramatically reducing computational cost while actually improving prediction quality. The core observation is that real-world driving scenes are inherently sparse: typically only ~20% of voxels in the perception volume are occupied after LSS lifting (approximately 80% are empty), yet dense methods expend equal computation on empty and occupied regions.
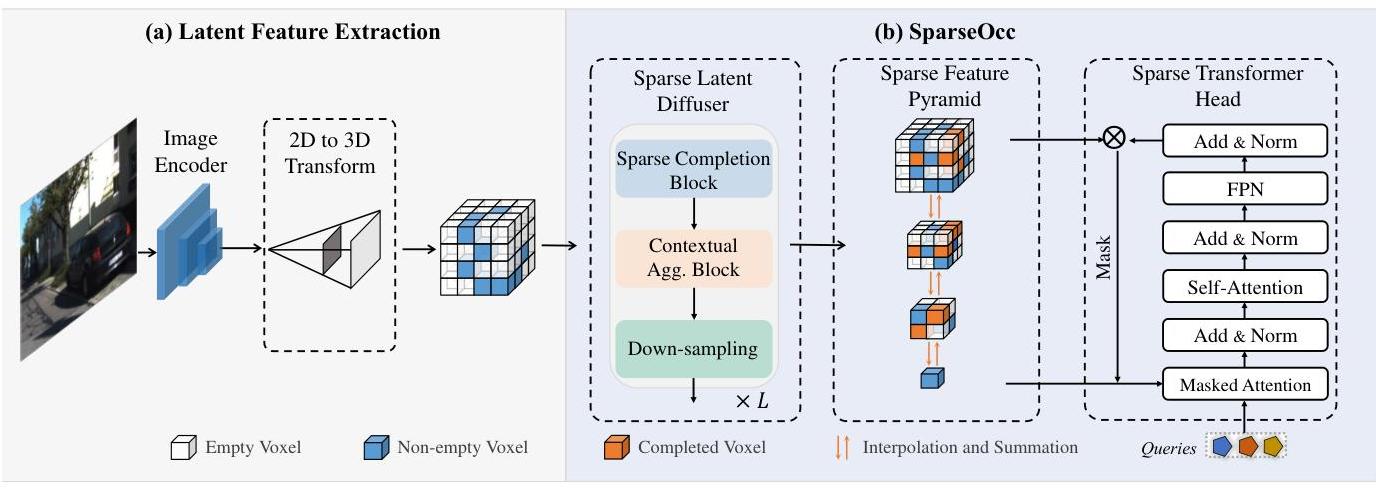
The method introduces three novel components that work together: (1) a Sparse Latent Diffuser that propagates features among sparse voxels using decomposed orthogonal sparse convolutions along the X, Y, and Z axes, avoiding full 3D convolutions; (2) a Sparse Feature Pyramid that constructs multi-scale representations from the sparse voxels, combining coarse global context with fine-grained local detail; and (3) a Sparse Transformer Head that performs contextual reasoning on sparse data through self-attention among non-empty voxels. The sparse voxels are stored in COO (coordinate) format throughout, enabling memory-efficient processing.
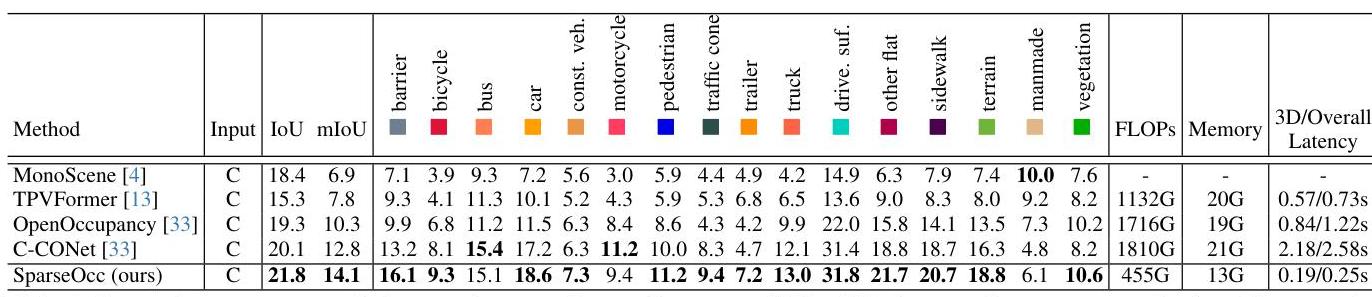
On the nuScenes-Occupancy benchmark, SparseOcc achieves a 74.9% reduction in FLOPs (from 1810G to 455G) and a 31.6–40.9% reduction in memory (13G vs. 19–21G) compared to dense baselines, while improving mIoU from 12.8% to 14.1% (IoU: 21.8%). The method is additionally evaluated on SemanticKITTI. This is a notable result: the sparse method is not just more efficient but also more accurate, likely because removing the distraction of empty-space processing allows the network to focus representational capacity on the occupied regions that actually matter for downstream planning. The approach demonstrates that sparse processing is not merely a computational shortcut but a fundamentally better inductive bias for occupancy prediction.
Key Contributions
- Sparse latent representation for occupancy: First method to process only non-empty voxels throughout the entire occupancy prediction pipeline, using COO-format sparse tensors for memory efficiency
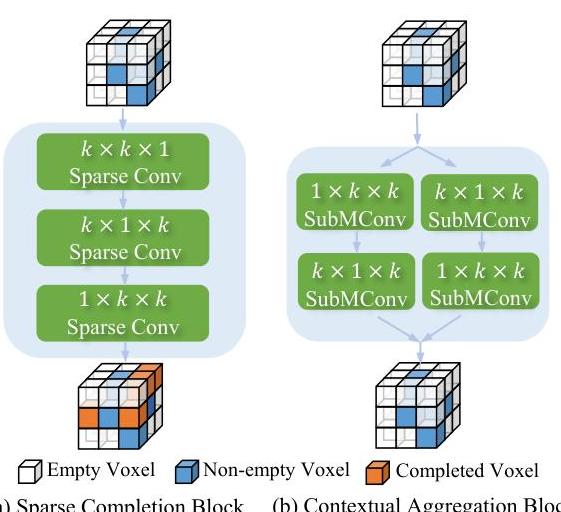
- Sparse Latent Diffuser: Two-part module: a Sparse Completion Block that propagates features to adjacent empty regions via sequential orthogonal convolutions (k×k×1, k×1×k, 1×k×k), and a Contextual Aggregation Block using decomposed sparse convolutions that reduce parameter count from O(k³) to O(3k²) or O(4k²)
- Multi-scale Sparse Feature Pyramid: Constructs coarse-to-fine sparse feature hierarchies, combining global scene context (from coarser levels) with local geometric detail (from finer levels)
- Sparse Transformer Head: Self-attention restricted to non-empty voxels for contextual reasoning, avoiding the quadratic cost of attending over the full volume
- Simultaneous efficiency and accuracy gains: 74.9% FLOP reduction with improved mIoU (12.8% to 14.1%), showing that sparsity is a better inductive bias, not just a compression trick
Architecture / Method
Multi-Camera Images
│
▼
┌──────────────────┐
│ 2D Backbone │ (ResNet-50)
│ + View Transform │
└────────┬─────────┘
│ initial 3D volume
▼
┌──────────────────────────────────────────────┐
│ Mask Predictor: identify occupied voxels │
│ Retain ~20% ──► COO sparse tensor │
└────────┬─────────────────────────────────────┘
│ sparse voxels (coords, features)
▼
┌──────────────────────────────────────────────┐
│ Sparse Latent Diffuser │
│ ┌──────────┐ ┌──────────┐ ┌──────────┐ │
│ │ X-axis │ │ Y-axis │ │ Z-axis │ │
│ │ Sparse │ │ Sparse │ │ Sparse │ │
│ │ Conv │ │ Conv │ │ Conv │ │
│ └────┬─────┘ └────┬─────┘ └────┬─────┘ │
│ └──────────┬──┘────────────┘ │
│ ▼ combine │
└──────────────────┼───────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ Sparse Feature Pyramid │
│ Coarse (global context) ◄──► Fine (detail) │
│ Top-down + lateral connections (all sparse) │
└──────────────────┬───────────────────────────┘
│
▼
┌──────────────────────────────────────────────┐
│ Sparse Transformer Head │
│ Self-attention among non-empty voxels only │
│ ──► Semantic occupancy predictions │
└──────────────────────────────────────────────┘
The SparseOcc pipeline processes multi-view camera images through three stages:
1. Initial Sparse Representation: Multi-view images are processed through a standard 2D backbone (e.g., ResNet-50) and view transformer to produce an initial 3D feature volume. A mask prediction module identifies which voxels are likely occupied, and only these voxels are retained in COO format -- a sparse tensor storing (coordinates, features) pairs for non-empty locations only. This initial sparsification step is critical: it discards the ~80% of voxels that are empty before any expensive 3D processing begins.
2. Sparse Latent Diffuser: The sparse voxel features are refined through two sub-blocks. The Sparse Completion Block propagates features into adjacent empty voxels via sequential orthogonal convolutions (k×k×1, then k×1×k, then 1×k×k), extending the sparse representation to neighboring space. The Contextual Aggregation Block then applies decomposed sparse convolutions across all non-empty voxels, reducing the parameter count from O(k³) to O(3k²) or O(4k²) compared to full 3D convolutions. Together, these blocks enable efficient feature propagation while avoiding the cost of densifying the representation.
3. Sparse Feature Pyramid: To capture multi-scale context, the sparse voxels are organized into a feature pyramid with multiple resolution levels. At coarser levels, sparse voxels are grouped and pooled to provide global scene understanding (e.g., road layout, building outlines). At finer levels, the original sparse voxels retain detailed local geometry. Features from different scales are fused through top-down and lateral connections, all operating in sparse format.
4. Sparse Transformer Head: The final prediction head applies self-attention among the sparse voxels. Because attention is restricted to the ~20% of voxels that are non-empty, the quadratic cost of self-attention is dramatically reduced compared to attending over the full dense volume. This enables rich contextual reasoning -- e.g., recognizing that a set of sparse voxels forms a vehicle rather than isolated noise -- while remaining computationally feasible.
The sparse processing has two important qualitative effects visible in the results: (1) SparseOcc produces cleaner predictions for continuous structures like roads and buildings because it avoids the hallucination artifacts that dense methods produce in empty regions; and (2) the method scales more gracefully to larger perception ranges because computation grows with the number of occupied voxels rather than the volume of the perception region.
Results
Key results on nuScenes-Occupancy (SparseOcc is also evaluated on SemanticKITTI in the paper):
| Method | IoU | mIoU | FLOPs (relative) | Notes |
|---|---|---|---|---|
| SparseOcc | 21.8% | 14.1% | 25.1% (74.9% reduction) | Sparse processing throughout; 13G memory |
| Dense baseline | – | 12.8% | 100% | Full 3D volume processing; 19-21G memory |
| OccFormer | – | 12.32% | ~100% | Dual-path transformer baseline |
| FlashOcc | – | ~12-13% | ~25-33% | 2D-only with C2H reshape |
The most striking result is that SparseOcc improves accuracy while reducing compute -- a rare combination. Ablation studies validate each component:
- Sparse Completion Block (Diffuser): Removing the Sparse Completion Block reduces mIoU by ~1.1%, with the Contextual Aggregation Block also outperforming standard 3D convolutions
- Sparse Feature Pyramid: Single-scale sparse processing (no pyramid) drops mIoU by ~0.8%, confirming the importance of multi-scale context even in sparse settings
- Sparse Transformer Head: Replacing self-attention with CNN-based decoding on sparse voxels reduces mIoU by ~0.7%, demonstrating the value of inter-voxel contextual reasoning
The qualitative results show that SparseOcc produces notably fewer hallucinations in empty regions and better preserves continuous surface geometry compared to dense baselines.
Limitations & Open Questions
- Initial mask quality: The approach depends on an accurate initial sparsification step -- if occupied voxels are missed by the mask predictor, they cannot be recovered downstream. The quality of the mask predictor is a bottleneck.
- Irregular sparsity patterns: COO-format sparse tensors are less hardware-friendly than dense tensors on standard GPUs. While FLOPs are reduced, wall-clock speedup may be less dramatic due to irregular memory access patterns and lack of optimized sparse CUDA kernels for all operations.
- Temporal integration: The paper primarily addresses single-frame occupancy. Extending sparse representations to temporal fusion (aligning and merging sparse voxels across frames) is non-trivial because the set of occupied locations changes over time.
- Scalability to larger ranges: While sparse processing scales better than dense in principle, the initial view transformer still operates in dense mode. A fully sparse pipeline from images to output remains an open challenge.
- Benchmark limitations: The nuScenes-Occupancy benchmark has known limitations in ground truth quality, particularly for distant and thin structures. Performance differences in the 12-15% mIoU range should be interpreted cautiously.
Connections
Related papers in the wiki:
- Surroundocc Multi Camera 3D Occupancy Prediction For Autonomous Driving — foundational dense occupancy method; SparseOcc addresses its computational inefficiency by processing only non-empty voxels
- Occformer Dual Path Transformer For Vision Based 3D Semantic Occupancy Prediction — dual-path decomposition of 3D processing; SparseOcc takes a more radical approach by eliminating dense processing entirely
- Flashocc Fast And Memory Efficient Occupancy Prediction Via Channel To Height Plugin — another efficient occupancy method, but achieves efficiency through 2D-only processing + reshape rather than true sparse 3D processing
- Gaussianformer Scene As Gaussians For Vision Based 3D Semantic Occupancy Prediction — alternative sparse representation using 3D Gaussians instead of sparse voxels; both avoid dense grids but with different primitives
- Gaussianformer 2 Probabilistic Gaussian Superposition For Efficient 3D Occupancy Prediction — probabilistic extension of Gaussian occupancy; shares the motivation of efficient sparse scene representation
- Occmamba Semantic Occupancy Prediction With State Space Models — addresses the same efficiency problem via linear-complexity Mamba rather than sparsity
- Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers — query-based view transformer that could serve as SparseOcc's initial BEV feature source
- Lift Splat Shoot Encoding Images From Arbitrary Camera Rigs By Implicitly Unprojecting To 3D — lift-splat paradigm underlying the initial dense-to-sparse view transformation
- Sparsedrive End To End Autonomous Driving Via Sparse Scene Representation — sparse scene representation for full E2E driving, extending sparsity from perception to planning