Overview
Lift, Splat, Shoot (LSS) introduced a differentiable pipeline for transforming multi-camera images into a unified bird's-eye view (BEV) representation without requiring LiDAR. The core insight is a three-step process: "lift" each pixel into a frustum of 3D points by predicting a categorical depth distribution, "splat" these 3D features into a voxel grid on the BEV plane using sum-pooling, and then "shoot" -- plan motion trajectories directly from the BEV features. This approach works with arbitrary camera configurations because the geometry is handled through known camera intrinsics and extrinsics rather than learned implicitly.
Before LSS, camera-based 3D perception often relied on explicit depth estimation or projection-based detection designs. LSS showed that a learned depth distribution per pixel, combined with an outer product with image features, creates a rich 3D representation that can be efficiently accumulated on a BEV grid. This became a highly influential template for later camera-to-BEV perception work such as BEVDet, BEVDepth, and BEVFusion.
The paper also demonstrated that the resulting BEV features are directly useful for downstream planning, not just perception. By predicting a cost map in BEV space and performing template-based trajectory selection, LSS showed the potential for end-to-end camera-to-planning pipelines that bypass explicit 3D bounding box detection entirely.
Key Contributions
- Lift operation: Predicts a categorical distribution over D discrete depth bins for each pixel and takes the outer product with the image feature vector, creating a point cloud of context-weighted features in 3D frustum space
- Splat operation: Efficiently accumulates 3D frustum features onto a 2D BEV grid using pillar-based sum pooling, leveraging cumulative sum tricks for GPU-efficient voxelization
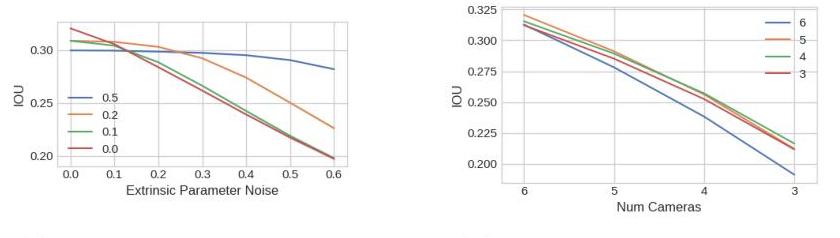
- Geometry-aware camera fusion: The architecture uses known intrinsics and extrinsics so image features can be lifted into a common 3D frame, and the paper shows robustness to calibration shifts, missing cameras, and transfer to a different camera rig
- End-to-end planning from cameras: Demonstrates trajectory planning directly from BEV features via a learned cost volume, bypassing the need for explicit 3D object detection
- Interpretable depth predictions: The predicted depth distributions can be visualized and validated against LiDAR ground truth, providing transparency into what the model learns
Architecture / Method
┌─────────────────────────────────────────────────────────┐
│ Lift, Splat, Shoot Pipeline │
│ │
│ N cameras with known [K, R|t] │
│ ┌────────┐ ┌────────┐ ┌────────┐ │
│ │ Cam 1 │ │ Cam 2 │ ... │ Cam N │ │
│ └───┬────┘ └───┬────┘ └───┬────┘ │
│ └──────────┼──────────────┘ │
│ ▼ │
│ ┌──────────────────────────────┐ │
│ │ Shared Backbone (EffNet-B0) │ per image, 1/8 res │
│ └──────────┬───────────────────┘ │
│ │ │
│ ┌──────┴──────┐ │
│ ▼ ▼ │
│ ┌────────┐ ┌──────────┐ │
│ │Context │ │ Depth │ │
│ │Features│ │Distrib. │ (softmax over D bins, │
│ │ c (C) │ │ α (D) │ e.g. 4m-45m @ 1m) │
│ └───┬────┘ └────┬─────┘ │
│ └──────┬──────┘ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ LIFT: Outer Product │ α ⊗ c ──► D x C frustum │
│ │ per pixel ──► 3D pts │ features in 3D via [K,R|t] │
│ └──────────┬───────────┘ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ SPLAT: Voxel Grid │ accumulate all cameras' │
│ │ Sum-pool over Z │ frustums ──► BEV (XxYxC) │
│ │ (cumsum trick, GPU) │ │
│ └──────────┬───────────┘ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ BEV Encoder (RN-18) │ │
│ └──────────┬───────────┘ │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ SHOOT: BEV Cost Map │ template trajectory library │
│ │ ──► select min-cost │ ──► best trajectory │
│ └──────────────────────┘ │
└─────────────────────────────────────────────────────────┘
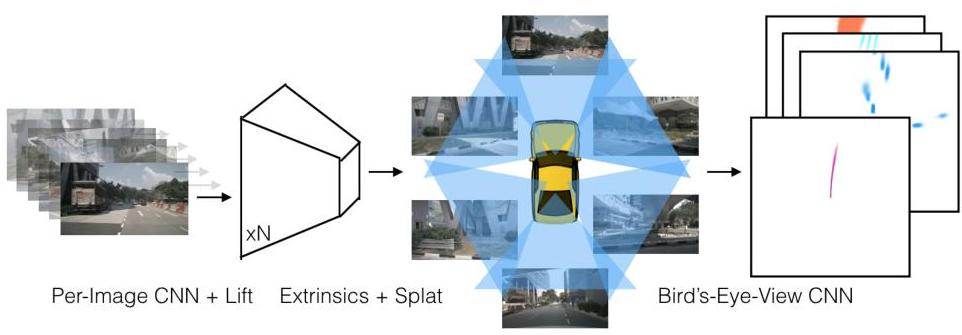
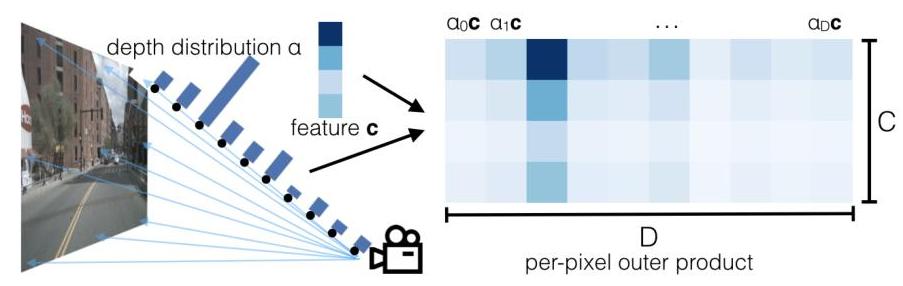
The architecture takes N camera images as input, each with known intrinsic matrix K and extrinsic pose [R|t]. For each image, a shared backbone (EfficientNet-B0) extracts features at 1/8 resolution. Two prediction heads produce (1) a context feature vector c for each pixel and (2) a softmax depth distribution alpha over discrete depth bins.
For each pixel, the outer product of alpha (D x 1) and c (1 x C) yields a D x C frustum feature tensor. Each depth bin maps to a known 3D point via the camera intrinsics and extrinsics. The "splat" step places all frustum features from all cameras into a 3D voxel grid (X x Y x Z) and collapses the Z dimension via sum pooling to produce a BEV feature map of size X x Y x C.
A BEV encoder (ResNet-18) processes the BEV features. For the planning ("shoot") task, the model predicts a per-pixel cost on the BEV grid and selects the lowest-cost trajectory from a template library of kinematically feasible paths.
Training uses binary cross-entropy for BEV semantic segmentation (vehicle, road, lane) and a planning loss based on expert trajectory imitation. The entire pipeline is differentiable and trained end-to-end.
Results

- On the nuScenes dataset, LSS achieves competitive performance on vehicle and map segmentation tasks from camera-only input, outperforming baselines and establishing the baseline for the BEV perception paradigm. Achieves competitive performance compared to LiDAR methods at close distances
- The model shows robustness to camera dropout and calibration errors, and the paper includes transfer experiments from nuScenes training to Lyft evaluation that support the geometry-aware design
- Depth distribution predictions correlate well with LiDAR-derived ground truth depths, showing the network learns meaningful geometry
- The planning module demonstrates feasible trajectory prediction from BEV features, though quantitative planning metrics were not the paper's primary focus
- The paper emphasizes efficient BEV pooling via the cumulative-sum trick, but it does not establish LSS as a production-ready real-time planning stack
Limitations & Open Questions
- The discrete depth binning introduces quantization error, particularly at long range where bins are sparse; later work (BEVDepth) showed that explicit depth supervision from LiDAR dramatically improves the depth predictions
- The sum-pooling splat operation loses information about vertical structure (height), which matters for objects like trucks vs. cars; 3D voxel representations or height-aware pooling could address this
- The paper does not address temporal fusion across frames, which is critical for velocity estimation and handling occlusions; subsequent work (BEVFormer, SOLOFusion) added temporal modeling on top of the LSS framework
Connections
- Perception -- LSS is a foundational camera-based perception method
- Planning -- demonstrates end-to-end camera-to-planning via BEV
- Autonomous Driving -- core method in modern AV perception stacks
- Planning Oriented Autonomous Driving -- UniAD builds on BEV representations pioneered by LSS
- Nuscenes A Multimodal Dataset For Autonomous Driving -- primary evaluation benchmark