GaussianBeV: 3D Gaussian Representation meets Perception Models for BeV Segmentation
Overview
Bird's-eye view (BEV) semantic segmentation from multi-camera images is a core perception task in autonomous driving, but existing image-to-BEV transformation methods face a fundamental trade-off. Depth-based approaches (the LSS family) are sensitive to depth estimation accuracy and primarily place features on visible surfaces, producing incomplete 3D representations. Attention-based methods (the BEVFormer family) are computationally and memory intensive, often requiring lower-resolution BEV maps. GaussianBeV addresses both limitations by introducing the first optimization-free, scene-agnostic approach that directly predicts a set of 3D Gaussians from multi-view images and renders them into a BEV feature map via differentiable rasterization.
The core idea is to repurpose 3D Gaussian Splatting -- originally designed for novel view synthesis with per-scene optimization -- as a feed-forward perception primitive. An end-to-end neural network (the 3D Gaussian Generator) predicts Gaussian parameters (position, rotation, scale, opacity, semantic features) directly from image features, then a differentiable BEV Rasterizer adapted from Gaussian Splatting renders these into a top-down semantic feature map. Two key design choices enable this: predicting allocentric rotations (orientations relative to each Gaussian's own position rather than the camera) and 3D offsets that allow Gaussians to refine their positions off the optical ray, modeling occluded or thin structures that depth-based methods miss.
GaussianBeV achieves new state-of-the-art results on the nuScenes BEV segmentation benchmark, improving vehicle segmentation by +3.5 IoU (47.5 vs. 44.0 for PointBeV) and pedestrian segmentation by +2.7 IoU (21.2 vs. 18.5). It also improves lane boundary segmentation by +2.6 IoU over MatrixVT (47.4 vs. 44.8) while operating at real-time speeds of 24 FPS on an A100 GPU.
Key Contributions
- Optimization-free 3D Gaussian prediction: First method to predict 3D Gaussian parameters directly from multi-view images in a single forward pass, eliminating the per-scene optimization required by standard 3D Gaussian Splatting
- Allocentric rotation prediction: Predicts Gaussian orientations in an allocentric frame (relative to each Gaussian's position) rather than an egocentric or camera-relative frame, improving geometric accuracy
- 3D offset refinement: Allows predicted Gaussians to move off the optical ray via learned 3D offsets, enabling representation of occluded surfaces and thin structures that depth-based lifting cannot reach
- Differentiable BEV Rasterizer: Adapts the Gaussian Splatting rendering pipeline to produce top-down BEV feature maps instead of perspective images, creating a rasterizer that generates geometrically and semantically rich BEV features
- Early supervision: Applies auxiliary supervision on BEV features from an intermediate rasterization step (before full refinement), stabilizing training and improving convergence
Architecture / Method

┌───────────────────────────────────────────────────────────────────┐
│ GaussianBeV Pipeline │
│ │
│ ┌──────────┐ ┌────────────────┐ │
│ │ Multi-cam │───►│ Shared Image │──► Per-pixel features │
│ │ Images │ │ Backbone │ │
│ └──────────┘ └────────────────┘ │
│ │ │
│ ┌──────────────▼──────────────┐ │
│ │ 3D Gaussian Generator │ │
│ │ Per pixel, predict: │ │
│ │ ┌─────────────────────────┐ │ │
│ │ │ Depth ──► Base 3D pos │ │ │
│ │ │ + Learned 3D offset │ │ (off-ray refinement) │
│ │ │ Allocentric rotation │ │ (viewpoint-invariant) │
│ │ │ Scale, Opacity │ │ │
│ │ │ Semantic feature vector │ │ │
│ │ └─────────────────────────┘ │ │
│ └──────────────┬──────────────┘ │
│ │ │
│ Set of 3D Gaussians {(mu, Sigma, alpha, f)} │
│ │ │
│ ┌──────────────▼──────────────┐ │
│ │ Differentiable BEV │ │
│ │ Rasterizer (top-down view) │ │
│ │ Alpha-blending aggregation │──► Early Supervision │
│ └──────────────┬──────────────┘ │
│ │ │
│ ┌──────────────▼──────────────┐ │
│ │ BEV Decoder ──► Semantic │ │
│ │ Segmentation Map │ │
│ └─────────────────────────────┘ │
└───────────────────────────────────────────────────────────────────┘
The architecture consists of three main stages: image feature extraction, 3D Gaussian generation, and BEV rasterization.
Image Backbone: Multi-view camera images are processed through a shared image encoder (e.g., ResNet or EfficientNet) to extract per-camera feature maps. These features provide the visual context from which Gaussian parameters are predicted.
3D Gaussian Generator: For each pixel in the image feature maps, the generator predicts a set of 3D Gaussian parameters: - 3D position: A base position is computed by unprojecting the pixel along its optical ray at a predicted depth. A learned 3D offset is then added, allowing the Gaussian to move off-ray to better represent the scene geometry. - Allocentric rotation: Rather than predicting rotations in the camera frame (which vary with viewpoint), rotations are predicted in an allocentric frame centered on each Gaussian. This decouples orientation prediction from camera pose. - Scale, opacity, and semantic features: Standard Gaussian properties controlling spatial extent, blending weight, and the semantic feature vector carried by each Gaussian.
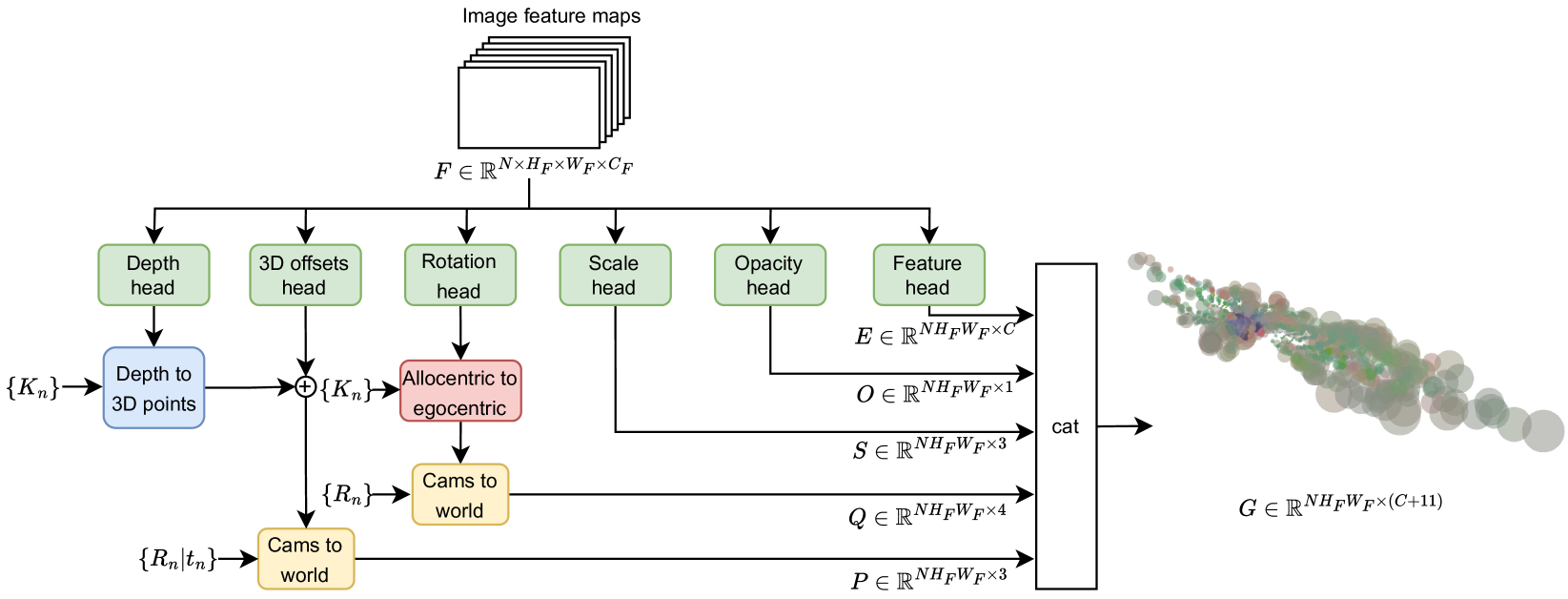
BEV Rasterizer: The predicted 3D Gaussians are rendered from a top-down viewpoint using a differentiable rasterization process adapted from 3D Gaussian Splatting. Each Gaussian is projected onto the BEV plane, and alpha-blending aggregates overlapping Gaussians to produce a dense BEV feature map. This feature map is intrinsically rich in both geometric and semantic information because the Gaussians encode 3D structure. A BEV decoder then processes this feature map to produce per-class semantic segmentation predictions.
Early Supervision: An auxiliary BEV segmentation loss is applied at an intermediate stage (after initial rasterization but before full decoder refinement). This provides direct gradients to the Gaussian Generator early in training, preventing the Gaussians from collapsing or diverging before the full pipeline converges.

Results
GaussianBeV achieves state-of-the-art performance on nuScenes BEV semantic segmentation across multiple categories:
| Method | Vehicle IoU | Pedestrian IoU | Lane Boundary IoU | FPS |
|---|---|---|---|---|
| LSS | 32.1 | 15.0 | -- | 71.5 |
| BEVPoolv2 | -- | -- | -- | -- |
| MatrixVT | -- | -- | 44.8 | -- |
| PointBeV | 44.0 | 18.5 | -- | -- |
| GaussianBeV | 47.5 | 21.2 | 47.4 | 24 |
Key findings: - Outperforms PointBeV (the prior SOTA depth-based method) by +3.5 IoU on vehicles and +2.7 IoU on pedestrians - Improves lane boundary segmentation by +2.6 IoU over MatrixVT - Operates at real-time speed (24 FPS on A100), making it practical for deployment - The 3D offset prediction is critical: without it, Gaussians are confined to optical rays and cannot model occluded or off-surface geometry - Allocentric rotation prediction outperforms egocentric alternatives, confirming that viewpoint-invariant orientation is important for multi-camera setups - Early supervision significantly improves convergence stability and final performance
Limitations & Open Questions
- Resolution-speed trade-off: At 24 FPS on an A100, GaussianBeV is real-time but slower than simpler LSS variants (71.5 FPS). The Gaussian rasterization overhead may be a concern for lower-end deployment hardware.
- Single-frame only: No temporal fusion across frames. Dynamic objects like pedestrians and cyclists would benefit from temporal Gaussian tracking or flow prediction, similar to what GaussianWorld does for occupancy.
- nuScenes only: All evaluation is on nuScenes; generalization to other datasets, camera configurations, and adverse weather conditions is untested.
- Gaussian count and density: The paper does not extensively explore how the number of predicted Gaussians per pixel or per image affects the accuracy-efficiency trade-off. Probabilistic formulations (as in GaussianFormer-2) could reduce redundancy.
- No 3D occupancy extension: GaussianBeV targets 2D BEV segmentation only. Extending the same Gaussian prediction framework to full 3D occupancy (as GaussianFormer does) is a natural next step.
Connections
Related papers in the wiki: - Lift Splat Shoot Encoding Images From Arbitrary Camera Rigs By Implicitly Unprojecting To 3D -- LSS introduced the depth-based lift-splat paradigm that GaussianBeV replaces with Gaussian prediction and rasterization - Gaussianlss Toward Real World Bev Perception With Depth Uncertainty Via Gaussian Splatting -- GaussianLSS also applies Gaussian Splatting to BEV perception but within the LSS framework (extending depth distributions with uncertainty); GaussianBeV takes a more radical approach by replacing the lift-splat pipeline entirely - Gaussianformer 2 Probabilistic Gaussian Superposition For Efficient 3D Occupancy Prediction -- Uses probabilistic Gaussian representations for 3D occupancy; shares the Gaussian scene primitive but targets voxel-level prediction rather than BEV segmentation - Gaussianworld Gaussian World Model For Streaming 3D Occupancy Prediction -- Extends Gaussians to temporal world modeling; GaussianBeV's single-frame Gaussians could serve as initialization for streaming prediction - Gausstr Foundation Model Aligned Gaussian Transformer For Self Supervised 3D -- Self-supervised Gaussian occupancy via foundation model alignment; contrasts with GaussianBeV's supervised approach - Nuscenes A Multimodal Dataset For Autonomous Driving -- Primary evaluation benchmark - Perception -- GaussianBeV advances the BEV perception paradigm with Gaussian representations