GaussTR: Foundation Model-Aligned Gaussian Transformer for Self-Supervised 3D Spatial Understanding
Overview
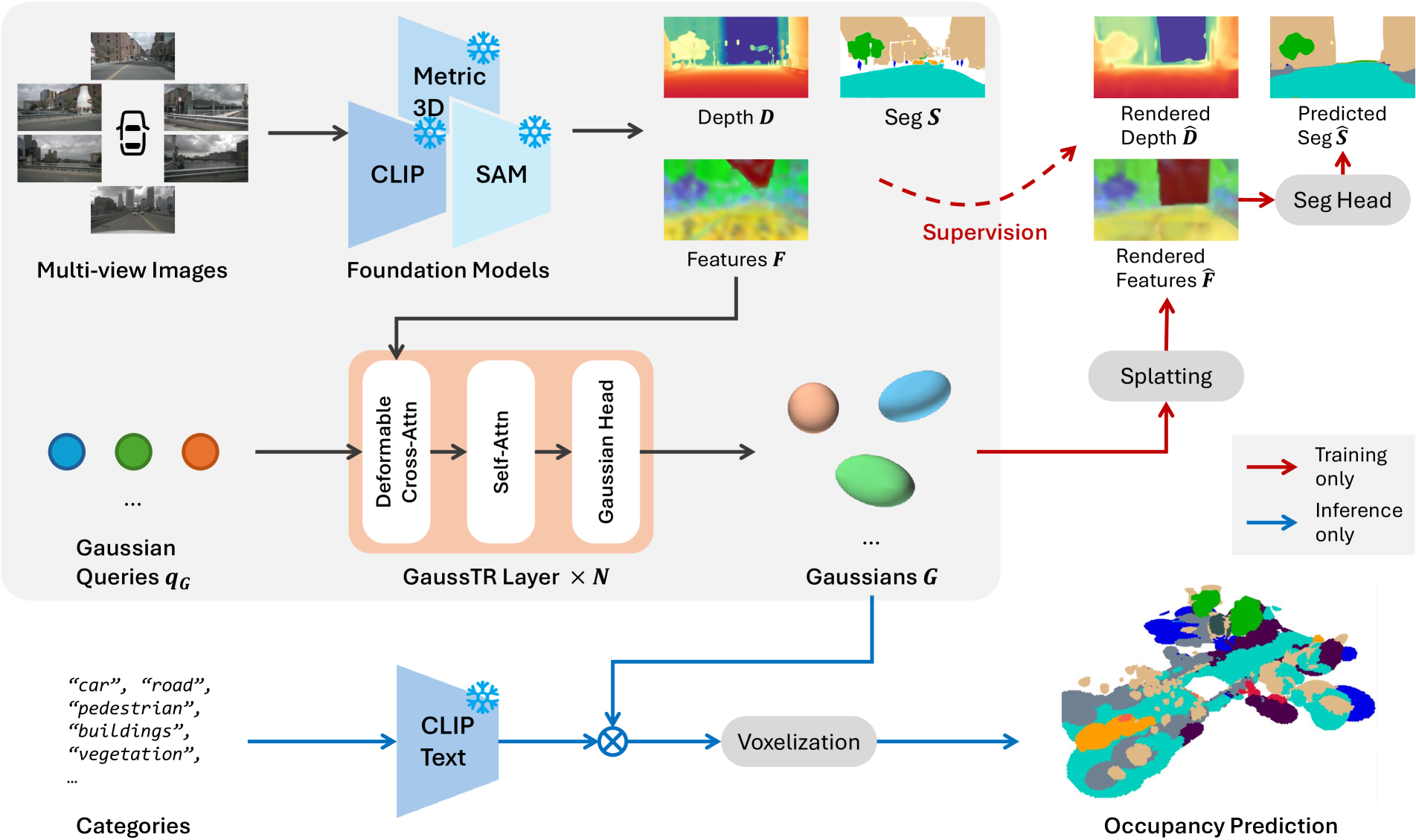
GaussTR is a Gaussian-based Transformer framework that achieves zero-shot semantic occupancy prediction without any 3D annotations. The key idea is to combine sparse 3D Gaussian representations with 2D Vision Foundation Model (VFM) alignment through differentiable splatting: predict a set of 3D Gaussians in a feed-forward pass, splat them back to 2D views, and train by aligning the rendered features with pre-trained foundation model outputs (CLIP, DINO, Metric3D).
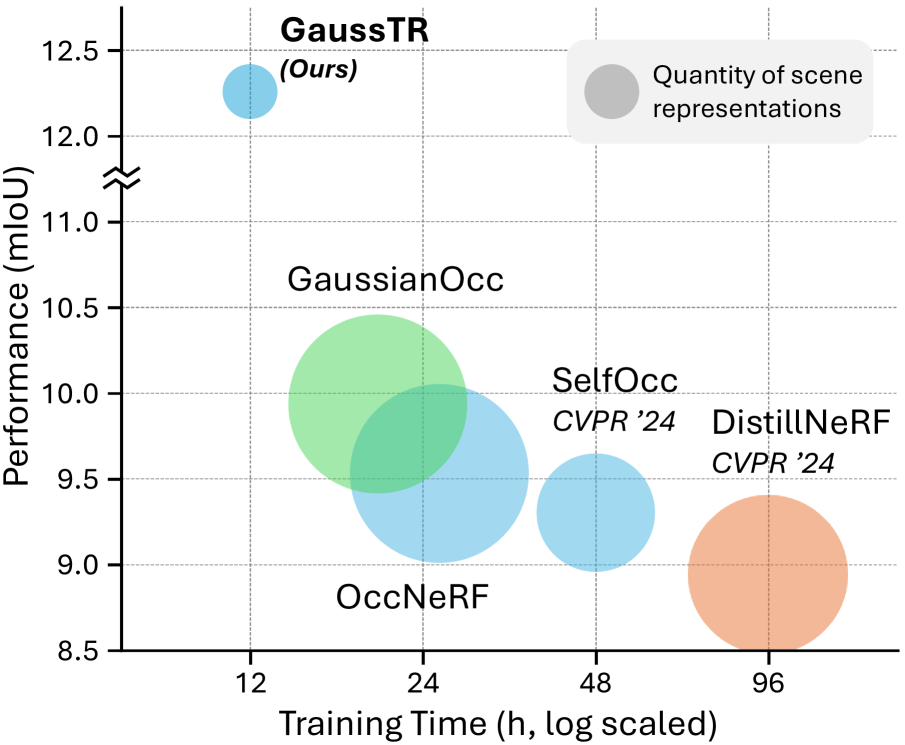
This self-supervised approach eliminates the expensive 3D annotation requirement that limits supervised occupancy methods. At inference, semantic labels are assigned via similarity between Gaussian features and text prototype embeddings from the foundation model, enabling open-vocabulary classification of novel categories. GaussTR achieves 12.27 mIoU zero-shot on Occ3D-nuScenes (23% improvement over prior self-supervised methods) while using only 3% of the scene representation parameters compared to voxel-based methods and reducing training time by 40%.
Key Contributions
- Self-supervised 3D learning via foundation model alignment: Bridges 2D VFM priors to 3D through differentiable Gaussian splatting, eliminating need for 3D annotations
- Open-vocabulary occupancy prediction: Zero-shot semantic classification via vision-language alignment -- can recognize categories never seen during training
- Extreme parameter efficiency: Uses only 3% of scene representation parameters compared to competing methods
- Training efficiency: 40% reduction in training time (~12 hours on 8 A800 GPUs for 1000 scenes)
- Sparse Gaussian representation: Replaces dense voxel grids with learnable 3D Gaussians, each parameterized by center, scaling, rotation, density, and feature vector
Architecture / Method
┌──────────────────────────────────────────────────────────────────┐
│ GaussTR Pipeline │
│ │
│ ┌──────────┐ ┌──────────────────────────────┐ │
│ │ Multi-cam │───►│ Pre-trained VFMs │ │
│ │ Images │ │ (CLIP, DINO, Metric3D V2) │ │
│ └──────────┘ └──────────┬───────────────────┘ │
│ │ │
│ Multi-scale 2D features + depth maps │
│ │ │
│ ┌────────────────┐ │ │
│ │ Learnable │ │ │
│ │ Gaussian Queries │ │ │
│ └────────┬───────┘ │ │
│ │ │ │
│ ▼ ▼ │
│ ┌─────────────────────────────────────────┐ │
│ │ Transformer Decoder │ │
│ │ ┌───────────────────────────────────┐ │ │
│ │ │ Deformable Cross-Attention │ │ │
│ │ │ (aggregate 2D features) │ │ │
│ │ ├───────────────────────────────────┤ │ │
│ │ │ Global Self-Attention │ │ │
│ │ │ (3D positional encodings) │ │ │
│ │ ├───────────────────────────────────┤ │ │
│ │ │ Gaussian Head (MLP): │ │ │
│ │ │ center, scale, rot, density, feat │ │ │
│ │ └───────────────────────────────────┘ │ │
│ └──────────────────┬──────────────────────┘ │
│ │ │
│ Predicted 3D Gaussians │
│ │ │
│ ┌────────────────┴─────────────────┐ │
│ ▼ (Training) ▼ (Inference) │
│ ┌───────────────────────┐ ┌──────────────────────────┐ │
│ │ Diff. Splatting ──► │ │ Text prototype embeddings│ │
│ │ 2D rendered features │ │ (from VFM) │ │
│ │ │ │ │ │ │ │
│ │ ▼ │ │ ▼ │ │
│ │ PCA + Cosine sim loss │ │ Cosine sim ──► semantic │ │
│ │ vs VFM features │ │ logits (zero-shot) │ │
│ │ + Depth loss (SILog) │ │ │ │ │
│ └───────────────────────┘ │ ▼ │ │
│ │ Voxelize ──► Occ Grid │ │
│ └──────────────────────────┘ │
└──────────────────────────────────────────────────────────────────┘
Input Processing: - Multi-view images processed through pre-trained VFMs (CLIP, DINO variants, Metric3D V2) - Extraction of multi-scale 2D features and dense depth maps
Gaussian Prediction (Transformer Decoder): - Learnable Gaussian queries decoded via deformable cross-attention for 2D feature aggregation - Global self-attention with 3D positional encodings for inter-Gaussian reasoning - MLP-based Gaussian head predicts: 3D center, scaling, rotation, density, feature vector
Self-Supervised Training: 1. Differentiable splatting renders predicted Gaussians back to 2D views 2. PCA reduces feature dimensionality for tractable comparison 3. Three loss components: feature alignment (cosine similarity with VFM features), depth supervision (SILog + L1 with Metric3D), optional segmentation loss
Open-Vocabulary Inference: - Generate text prototype embeddings from foundation model for target categories - Compute semantic logits via cosine similarity between Gaussian features and text prototypes - Voxelize Gaussians for final occupancy grid output
Results
| Metric | Value |
|---|---|
| Zero-shot mIoU (Occ3D-nuScenes) | 12.27 |
| Improvement over prior self-supervised | +2.33 mIoU (23%) |
| Training time reduction | 40% |
| Parameter efficiency vs voxel methods | 3% |
| Training duration | ~12 hours (8x A800 GPUs) |
| Spatial coverage | 80m x 80m x 6.4m at 0.4m resolution |
Foundation model ablation: - Talk2DINO: 12.27 mIoU (best) - FeatUp: 11.70 mIoU
Category strengths: Vehicles, trucks, and man-made structures perform well; small objects and flat surfaces (sidewalks) are challenging due to occlusion and limited geometric signal.
Limitations
- Zero-shot mIoU of 12.27 remains far below supervised methods (GaussianFormer-2 achieves 20.82); the self-supervised advantage is annotation-free training, not raw performance
- Dependent on quality of 2D foundation models; performance varies significantly with VFM choice (Talk2DINO vs FeatUp)
- Small objects and flat surfaces remain challenging -- the Gaussian representation struggles with thin/flat geometry
- No temporal modeling; single-frame prediction without history aggregation
- Open-vocabulary capability limited by the foundation model's vocabulary and feature quality
Connections
- Gaussianformer 2 Probabilistic Gaussian Superposition For Efficient 3D Occupancy Prediction -- Supervised Gaussian occupancy; GaussTR is the self-supervised counterpart
- Gaussianworld Gaussian World Model For Streaming 3D Occupancy Prediction -- Both use 3D Gaussians for scene representation; GaussianWorld adds temporal prediction
- Gaussianlss Toward Real World Bev Perception With Depth Uncertainty Via Gaussian Splatting -- Gaussian Splatting for BEV; GaussTR extends to full 3D with foundation model alignment
- Learning Transferable Visual Models From Natural Language Supervision -- CLIP provides the vision-language alignment backbone used in GaussTR
- S4 Driver Scalable Self Supervised Driving Mllm With Spatio Temporal Visual Representation -- Both pursue self-supervised/annotation-free approaches to driving perception
- Perception -- Advances self-supervised 3D occupancy prediction
- Autonomous Driving -- Annotation-free perception for scalable driving systems