BEVFormer v2: Adapting Modern Image Backbones to Bird's-Eye-View Recognition via Perspective Supervision
Overview
BEVFormer v2 addresses a critical bottleneck in camera-based 3D perception for autonomous driving: the inability to leverage powerful modern 2D image backbones (e.g., InternImage, ConvNeXt) for bird's-eye-view (BEV) detection. Prior BEV detectors relied on specialized backbones pre-trained on depth-estimation datasets (such as DD3D-pretrained VoVNet), because standard ImageNet-pretrained backbones performed poorly -- an ImageNet-pretrained ConvNeXt-XL, despite its advanced architecture and large parameter count, performed only on par with a much smaller depth-pretrained VoVNet. The core problem is a significant domain gap: the final 3D detection loss is applied far from the image backbone, passing through multiple transformer layers, resulting in sparse gradient signals that inadequately guide the backbone toward learning 3D-aware features.
The key insight of BEVFormer v2 is perspective supervision: adding an auxiliary 3D detection head that operates directly in perspective view on the image backbone's output, providing dense, per-pixel gradients that force the backbone to learn 3D-relevant features. This simple but effective strategy bridges the domain gap between 2D pre-training and 3D BEV tasks without requiring specialized depth pre-training. The perspective proposals are further recycled as high-quality object queries for the BEV detection stage, creating a two-stage pipeline that improves both training efficiency and detection accuracy.
With perspective supervision, BEVFormer v2 achieved new state-of-the-art results on the nuScenes benchmark: 63.4% NDS and 55.6% mAP using an InternImage-XL backbone, surpassing previous methods by 2.4% NDS and 3.1% mAP. The approach consistently boosted performance across diverse backbone architectures (ResNet, DLA, VoVNet, InternImage), demonstrating that it democratizes backbone choice for BEV perception research.
Key Contributions
- Perspective supervision framework: An auxiliary 3D detection head in perspective view provides dense gradient signals to the image backbone, eliminating the need for depth-specific pre-training
- Two-stage BEV detection pipeline: High-quality perspective proposals are projected into BEV space and combined with learned queries to form hybrid object queries, improving detection recall and precision
- Backbone-agnostic improvement: Perspective supervision consistently improves NDS by ~3% and mAP by ~2% across ResNet, DLA, VoVNet, and InternImage backbones
- Enhanced temporal encoding: Ego-motion-aligned warping of historical BEV features with residual blocks for temporal fusion
- State-of-the-art nuScenes performance: 63.4% NDS / 55.6% mAP, surpassing all prior camera-only methods at time of publication
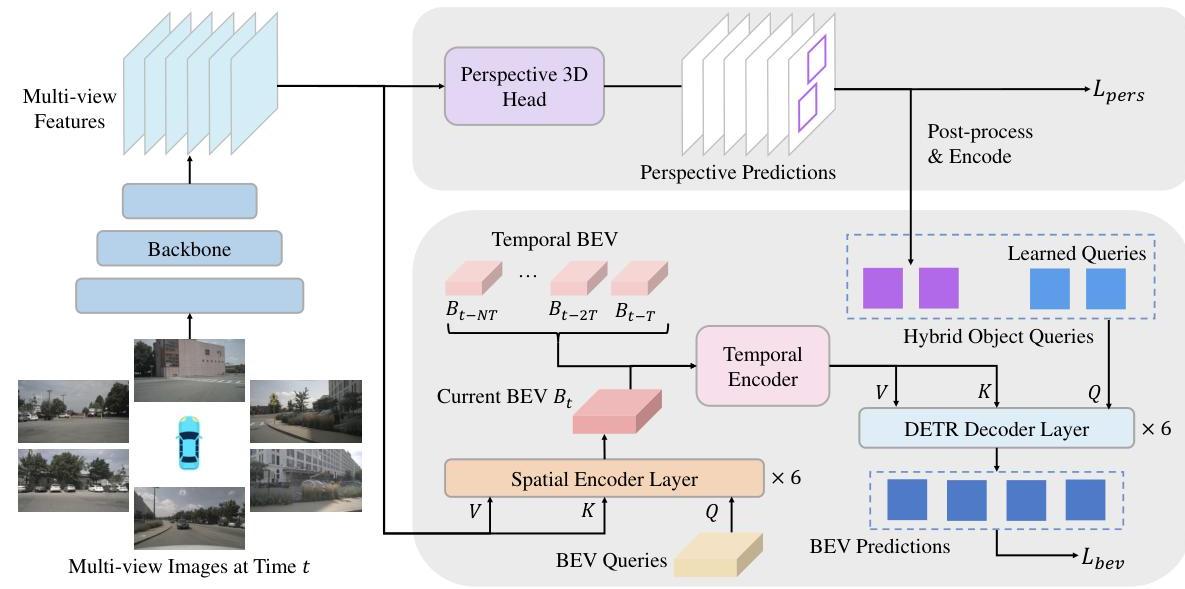
Architecture / Method
┌────────────────────────────────────────────────────────────────┐
│ BEVFormer v2 Architecture │
├────────────────────────────────────────────────────────────────┤
│ │
│ Multi-Camera Images │
│ │ │
│ ▼ │
│ ┌──────────────────┐ │
│ │ Image Backbone │ (InternImage / ResNet / ConvNeXt) │
│ │ + Multi-Scale FPN│ │
│ └────────┬──────────┘ │
│ │ │
│ ┌─────┴──────────────────────┐ │
│ │ │ │
│ ▼ ▼ │
│ ┌───────────────────┐ ┌──────────────────────┐ │
│ │ Perspective Head │ │ BEVFormer Encoder │ │
│ │ (DD3D/FCOS3D-style│ │ (Spatial + Temporal │ │
│ │ dense per-pixel │ │ Cross-Attention) │ │
│ │ 3D detection) │ └──────────┬───────────┘ │
│ └────────┬──────────┘ │ │
│ │ │ │
│ L_pers │ NMS + Top-K │ │
│ (dense │ │ │ │
│ gradients│ ▼ ▼ │
│ to │ 3D proposals ──► BEV Projection │
│ backbone)│ │ │ │
│ │ └───────┬───────┘ │
│ │ ▼ │
│ │ ┌───────────────────────┐ │
│ │ │ Hybrid Object Queries │ │
│ │ │ (proposals + learned) │ │
│ │ └───────────┬───────────┘ │
│ │ ▼ │
│ │ ┌───────────────────────┐ │
│ │ │ BEV Transformer │ │
│ │ │ Decoder │ │
│ │ └───────────┬───────────┘ │
│ │ │ │
│ │ ▼ │
│ │ L_bev (3D detection) │
│ │ │
│ L_total = λ_bev·L_bev + λ_pers·L_pers │
└────────────────────────────────────────────────────────────────┘
BEVFormer v2 builds on the original BEVFormer architecture with two critical additions: a perspective supervision branch and a two-stage detection pipeline.
Perspective Supervision Branch
The perspective supervision head is a dense, anchor-free 3D detection head (following DD3D/FCOS3D design) that operates directly on the multi-scale image features from the backbone. It makes per-pixel predictions for classification, 3D bounding box regression, and centerness. The perspective supervision loss is:
L_pers = L_cls + L_reg + L_centerness
This loss is applied directly to backbone features, providing strong gradients that teach the backbone to extract 3D-relevant information from 2D images. Crucially, this head uses dense prediction (every spatial location produces predictions), which generates far richer supervision than sparse query-based approaches like DETR3D.
Two-Stage Detection Pipeline
Rather than discarding the perspective predictions, BEVFormer v2 recycles them:
- Perspective proposals undergo NMS and top-k selection
- Their 3D centers are projected into BEV space to create per-image reference points
- These reference points are combined with BEVFormer's learned BEV queries to form hybrid object queries
- The BEV transformer decoder refines these hybrid queries using spatiotemporal cross-attention
Enhanced Temporal Encoding
Historical BEV features are warped to the current frame using ego-motion transformation matrices:
B_warped = Warp(B_{t-k}, T_{t-k -> t})
Warped features are concatenated with current BEV features along the channel dimension, then processed through residual blocks for dimension reduction. This improves temporal consistency over the original BEVFormer's recurrent temporal self-attention.
Total Training Objective
L_total = lambda_bev * L_bev + lambda_pers * L_pers
Both losses are jointly optimized, ensuring the backbone receives strong gradients from perspective supervision while the BEV head learns to produce the final 3D detections.
Results
BEVFormer v2 set new state-of-the-art results on nuScenes among camera-only methods:
| Method | Backbone | NDS | mAP |
|---|---|---|---|
| BEVFormer v2 | InternImage-XL | 63.4 | 55.6 |
| BEVFormer v2 | InternImage-B | 62.0 | 54.0 |
| BEVFormer (v1) | VoVNet-99 (DD3D) | 56.9 | 48.1 |
| PolarFormer | VoVNet-99 (DD3D) | 57.2 | 49.3 |
| PETR v2 | GLOM | 58.2 | 49.0 |
Ablation Results (nuScenes val, ResNet-101, no temporal, 48 epochs — paper Table 2)
| Configuration | NDS | mAP | Delta NDS | Delta mAP |
|---|---|---|---|---|
| BEV Only (baseline) | 42.6 | 35.5 | -- | -- |
| BEV & BEV (control) | 42.8 | 35.0 | +0.2 | -0.5 |
| Perspective & BEV | 45.1 | 37.4 | +2.5 | +1.9 |
The control experiment ("BEV & BEV") added a second BEV detection head instead of a perspective head, showing no improvement. This confirms the gains come specifically from perspective-view supervision, not from simply adding more supervision or parameters. Models with perspective supervision trained for 24 epochs surpassed BEV-only models trained for 48 epochs, demonstrating substantially faster convergence.
Detection Head Analysis
Dense prediction heads (DD3D-style) significantly outperformed sparse query-based approaches (DETR3D-style) for the perspective supervision branch. The density of per-pixel predictions provides much stronger backbone gradients than sparse query attention.
Limitations & Open Questions
- Inference overhead: The perspective head adds computation during both training and inference (though it could potentially be dropped at inference with some accuracy trade-off)
- Depth pre-training still helps: While perspective supervision narrows the gap, depth-pretrained backbones still provide some benefit, suggesting room for improvement
- Limited to detection: The paper focuses on 3D object detection; extending perspective supervision to BEV segmentation, occupancy prediction, or end-to-end planning is unexplored
- Single dataset evaluation: Results are only reported on nuScenes; generalization to other benchmarks (Waymo, Argoverse) is not studied
Connections
Related papers in the wiki: - Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers -- direct predecessor; BEVFormer v2 builds on and extends the BEVFormer architecture - Lift Splat Shoot Encoding Images From Arbitrary Camera Rigs By Implicitly Unprojecting To 3D -- alternative BEV generation paradigm (geometric lift-splat vs. query-based attention) - Nuscenes A Multimodal Dataset For Autonomous Driving -- primary evaluation benchmark - Planning Oriented Autonomous Driving -- UniAD builds on BEVFormer; v2's improvements to BEV features could benefit joint perception-planning systems - An Image Is Worth 16X16 Words Transformers For Image Recognition At Scale -- ViT backbone family that BEVFormer v2 enables for BEV perception - Deep Residual Learning For Image Recognition -- ResNet backbone evaluated in ablations - Perception -- BEV perception paradigm and the backbone adaptation problem - Autonomous Driving -- broader application context