An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Citation
Dosovitskiy et al., ICLR, 2021.
Canonical link
Overview
The Vision Transformer (ViT) demonstrates that a pure Transformer applied to sequences of image patches -- with no convolutions -- matches or exceeds state-of-the-art CNNs on image classification when pre-trained on large-scale data. This was the definitive demonstration that the Transformer architecture generalizes beyond language to vision.
ViT showed that the inductive biases hard-coded into CNNs (local connectivity, translation equivariance) are not necessary when sufficient data is available. By splitting images into 16x16 patches, linearly embedding them, and feeding the resulting sequence into a standard Transformer encoder, the paper achieved state-of-the-art ImageNet accuracy while using substantially less compute than the best CNNs. The critical finding was scale-dependent performance: ViT underperforms ResNets on small datasets but dominates at scale, revealing a data-compute tradeoff between inductive bias and flexibility.
This result triggered a paradigm shift. Within two years, vision transformers replaced CNNs as the dominant architecture in computer vision, and the patch-as-token idea enabled unified architectures across vision, language, and multimodal tasks (CLIP, DALL-E, PaLM-E). ViT is now the standard vision encoder in virtually all modern multimodal systems.
Key Contributions
- Patches as tokens: Divide a 224x224 image into 196 non-overlapping 16x16 patches, flatten each to a 768-dim vector, and linearly project -- creating a sequence that a standard Transformer encoder processes without modification
- Learnable [CLS] token and position embeddings: A prepended classification token aggregates global information; learnable 1D position embeddings encode spatial layout (shown to learn 2D structure automatically)
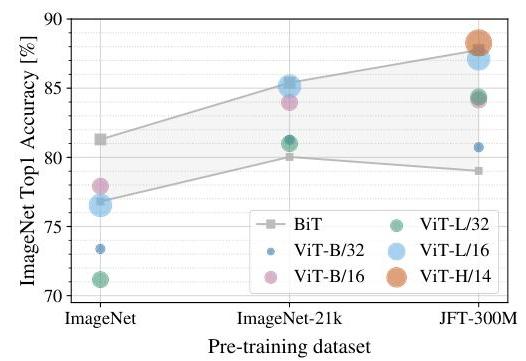
- Scale-dependent performance: ViT underperforms ResNets when trained only on ImageNet-1k (~1.3M images) but dominates when pre-trained on ImageNet-21k (14M) or JFT-300M (300M), revealing that Transformers need more data to compensate for weaker inductive bias
- Compute-efficient scaling: ViT-L/16 pre-trained on JFT-300M achieves 87.76% ImageNet top-1 accuracy using approximately 15x less compute than BiT-L (0.68k vs 9.9k TPUv3-core-days) at similar accuracy
- Attention distance analysis: Some attention heads attend broadly across the image even in early layers, while others maintain local attention patterns; attention distance generally increases with network depth, suggesting the model learns a mix of local and global representations despite having no built-in locality bias
Architecture / Method
┌──────────────────────────────────────────────────────────────┐
│ Vision Transformer (ViT) │
├──────────────────────────────────────────────────────────────┤
│ │
│ Input Image (224 x 224) │
│ │ │
│ ▼ │
│ Split into 196 patches (16 x 16 each) │
│ [p_1] [p_2] [p_3] ... [p_196] │
│ │ │
│ ▼ Flatten + Linear Projection (to dim D) │
│ │
│ [CLS] [e_1] [e_2] [e_3] ... [e_196] │
│ + + + + + Learnable Position │
│ pos_0 pos_1 pos_2 pos_3 ... pos_196 Embeddings │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────┐ x L layers │
│ │ Transformer Encoder Block │ (L=12 Base, │
│ │ ┌────────────────────────────┐ │ 24 Large, │
│ │ │ Layer Norm │ │ 32 Huge) │
│ │ │ Multi-Head Self-Attention │ │ │
│ │ │ + Residual │ │ │
│ │ ├────────────────────────────┤ │ │
│ │ │ Layer Norm │ │ │
│ │ │ MLP (GELU) │ │ │
│ │ │ + Residual │ │ │
│ │ └────────────────────────────┘ │ │
│ └──────────────────────────────────┘ │
│ │ │
│ ▼ (CLS token output) │
│ ┌──────────────┐ │
│ │ Linear Head │ ──► Class Prediction │
│ └──────────────┘ │
└──────────────────────────────────────────────────────────────┘
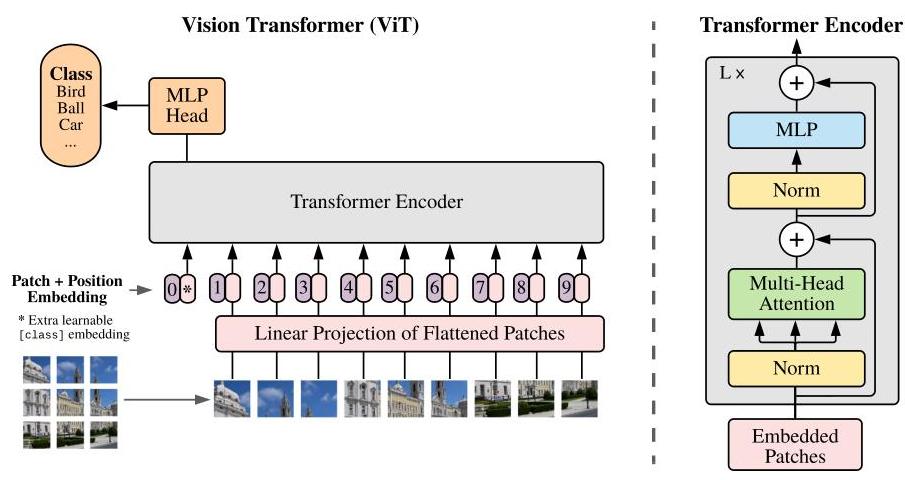
ViT uses a standard Transformer encoder (identical to the original Transformer's encoder from Vaswani et al.) with minimal modifications for vision. An input image of size H x W is divided into a grid of N = HW/P^2 non-overlapping patches of size P x P (typically P=16, giving N=196 patches for 224x224 images). Each patch is flattened into a vector and linearly projected to dimension D (768 for ViT-Base, 1024 for ViT-Large, 1280 for ViT-Huge).
A learnable [CLS] token is prepended to the patch sequence, and learnable 1D position embeddings are added to all tokens (including [CLS]). The resulting sequence of N+1 tokens is processed by L Transformer encoder layers, each consisting of multi-head self-attention (MSA), layer normalization (applied before attention and FFN, i.e., Pre-LN), and an MLP with GELU activation. The [CLS] token's output is passed through a classification head (a single linear layer during fine-tuning).
Three model sizes are studied: ViT-Base (12 layers, 12 heads, 86M params), ViT-Large (24 layers, 16 heads, 307M params), and ViT-Huge (32 layers, 16 heads, 632M params). Pre-training uses Adam with linear warmup and cosine decay on JFT-300M or ImageNet-21k. Fine-tuning on downstream tasks uses SGD with momentum at higher resolution (384x384 or 512x512), with position embeddings interpolated to handle the increased number of patches.
Results
| Model | ImageNet Top-1 | Pre-training Data | Compute (TPUv3-core-days) |
|---|---|---|---|
| ViT-H/14 | 88.55% | JFT-300M | 2.5k |
| ViT-L/16 | 87.76% | JFT-300M | 0.68k |
| BiT-L (ResNet) | 87.54% | JFT-300M | 9.9k |
| EfficientNet-L2 | 88.4% | JFT-300M | - |
- ViT matches SOTA at scale: ViT-H/14 achieves 88.55% top-1 on ImageNet and 77.63% on VTAB when pre-trained on JFT-300M, surpassing EfficientNet-L2 (88.4%) while using fewer TPU-days
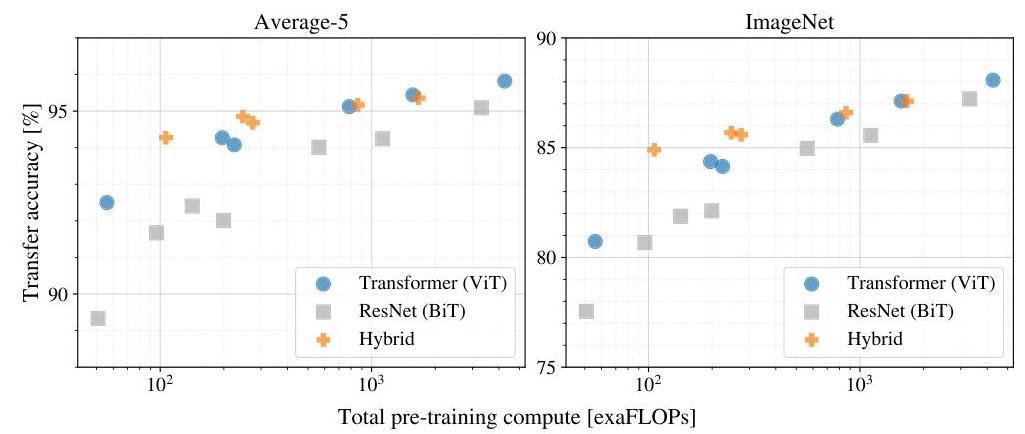
- Computational efficiency: ViT-L/16 achieved superior results using 0.68k TPUv3-core-days vs. BiT-L's 9.9k for comparable accuracy -- approximately 15x more compute-efficient
- Pre-training dataset size is critical: On ImageNet-1k alone, ViT-B achieves only ~77% (vs. ResNet-50 at ~79%); on JFT-300M, ViT-L reaches 87.8%, demonstrating a crossover where Transformers overtake CNNs as data scales. Performance "rapidly improves" with larger datasets, eventually surpassing all competitors at JFT-300M scale
- Position embeddings learn 2D structure: Cosine similarity between learned position embeddings reveals a clear 2D grid pattern, showing the model discovers spatial relationships from data alone despite using 1D position embeddings
- Interpretability: Initial linear embedding filters resemble plausible basis functions for patches; some attention heads attend broadly across the image even in early layers while others maintain local attention, with attention distance generally increasing through network depth
- No saturation at scale: Performance continues to improve as model size and data increase, with no sign of diminishing returns on JFT-300M, suggesting further gains from larger models
- Transfer to multiple benchmarks: Strong results on CIFAR-10/100, Oxford Flowers, Oxford-IIIT Pets, and VTAB, establishing ViT as a general-purpose vision backbone
- Central thesis: The work demonstrates that "large scale training trumps inductive bias" -- generic architectures can learn representations directly from data, potentially surpassing specialized architectures with better computational efficiency
Limitations & Open Questions
- Requires very large pre-training datasets (14M+ images) to outperform CNNs; on small or medium datasets, ViT is inferior without additional regularization (addressed by DeiT, which introduces distillation and augmentation)
- Fixed patch size creates a resolution-computation tradeoff: smaller patches yield more tokens and quadratically more attention cost; efficient attention variants (Swin Transformer) address this
- The paper evaluates only classification; extending ViT to dense prediction tasks (detection, segmentation) required architectural modifications (ViTDet, Segmenter, Swin)
Connections
- Machine Learning — foundational ML concepts
- Attention Is All You Need — the Transformer architecture that ViT adapts for vision
- Deep Residual Learning For Image Recognition — ResNet, the CNN baseline ViT compares against and eventually surpasses at scale
- Imagenet Classification With Deep Convolutional Neural Networks — AlexNet, the CNN paradigm that ViT ultimately displaces
- Learning Transferable Visual Models From Natural Language Supervision — CLIP, which uses ViT as its vision encoder for vision-language alignment
- Bert Pre Training Of Deep Bidirectional Transformers For Language Understanding — BERT, whose [CLS] token and pre-training paradigm ViT directly adapts