Identity Mappings in Deep Residual Networks
Overview
This paper, a follow-up to the original ResNet work, provides both theoretical analysis and empirical evidence that the arrangement of operations within residual blocks critically affects trainability at extreme depths. The key finding is that placing batch normalization and ReLU before the convolution (pre-activation ordering: BN-ReLU-Conv) instead of after (post-activation: Conv-BN-ReLU) creates a clean identity path through skip connections, enabling training of networks with over 1000 layers without degradation.
The theoretical analysis reveals why identity shortcuts are optimal: for a network of depth L, the gradient decomposes as dL/dx_l = dL/dx_L * (1 + sum of residual gradient terms). The constant 1 from the identity path provides an unattenuated gradient signal regardless of depth, preventing vanishing gradients even in extremely deep networks. Any non-linearity on the skip connection path (gating, convolution, scaling) disrupts this property and causes gradient degradation at extreme depths.
The paper enabled training a 1001-layer ResNet on CIFAR-10 that outperformed the 110-layer baseline, definitively proving that properly designed residual networks benefit from extreme depth. The pre-activation design became the foundation for DenseNet, ResNeXt, and other subsequent architectures. The gradient flow analysis also provides theoretical grounding for why residual connections work in transformers, where the same identity shortcut principle (the "residual stream") enables training of very deep attention-based networks.
Key Contributions
- Pre-activation residual blocks: BN-ReLU-Conv ordering moves all non-linearities to the residual branch, leaving the skip connection as a pure identity mapping x_{l+1} = x_l + F(x_l)
- Gradient flow analysis: Mathematical proof that the identity path provides a constant gradient term of 1 that prevents vanishing gradients regardless of network depth
- Systematic ablation of skip connection variants: Comprehensive experiments testing multiplicative gating, convolution on skip path, dropout on skip path, and other modifications, showing that any deviation from pure identity hurts performance
- 1001-layer training: Demonstrates that a 1001-layer pre-activation ResNet achieves 4.62% error on CIFAR-10, outperforming the 110-layer post-activation baseline
Architecture / Method
ORIGINAL (post-activation) PRE-ACTIVATION (proposed)
x_l x_l
│ │
├─────────────┐ ├─────────────┐
│ │ │ │
▼ │ ▼ │
┌─────────┐ │ ┌─────────┐ │
│ Conv │ │ │ BN │ │
└────┬────┘ │ └────┬────┘ │
▼ │ ▼ │
┌─────────┐ │ ┌─────────┐ │
│ BN │ │ │ ReLU │ │
└────┬────┘ │ └────┬────┘ │
▼ │ ▼ │
┌─────────┐ │ ┌─────────┐ │
│ ReLU │ │ │ Conv │ │
└────┬────┘ │ └────┬────┘ │
▼ │ ▼ │
┌─────────┐ │ ┌─────────┐ │
│ Conv │ │ │ BN │ │
└────┬────┘ │ └────┬────┘ │
▼ │ ▼ │
┌─────────┐ │ ┌─────────┐ │
│ BN │ │ │ ReLU │ │
└────┬────┘ │ └────┬────┘ │
│ │ ▼ │
▼ │ ┌─────────┐ │
(+) ◄───────────┘ │ Conv │ │
│ └────┬────┘ │
▼ │ │
┌─────────┐ ▼ │
│ ReLU │ (+) ◄───────────┘
└────┬────┘ │
│ │ ◄── clean identity path
▼ ▼
x_{l+1} x_{l+1}
Gradient: dL/dx_l = dL/dx_L · (1 + Σ residual terms)
▲
constant 1 prevents
vanishing gradients
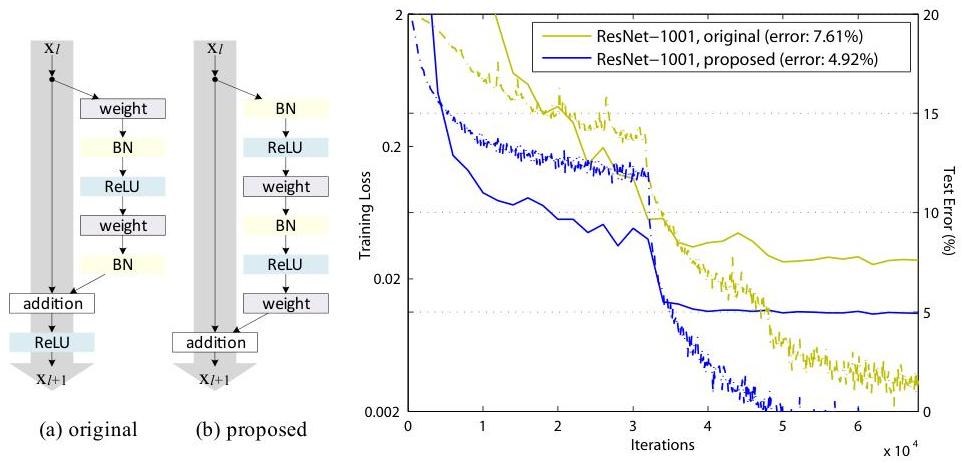
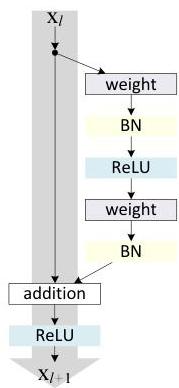
The paper systematically analyzes the residual block design by decomposing it into two paths: the skip (shortcut) connection and the residual branch. The general form is x_{l+1} = h(x_l) + F(x_l, W_l), where h is the shortcut function and F is the residual function. The original ResNet uses h(x) = x (identity) for matching dimensions, with the block ordering Conv -> BN -> ReLU -> Conv -> BN, followed by addition and then ReLU.
The key modification is moving the BN and ReLU operations from after the addition to before the convolutions within the residual branch. The pre-activation block becomes: BN -> ReLU -> Conv -> BN -> ReLU -> Conv, with the output added to the identity shortcut without any post-addition non-linearity. This seemingly simple reordering has profound implications.
The paper tests five shortcut function variants: (a) identity h(x) = x, (b) constant scaling h(x) = lambdax, (c) exclusive gating h(x) = (1-g(x))x, (d) shortcut-only gating h(x) = g(x)x, (e) 1x1 convolution h(x) = W_sx. All non-identity variants degrade performance at extreme depths because they introduce multiplicative factors on the gradient path that compound across layers.
For the residual branch activation ordering, the paper tests: (a) original post-activation (Conv-BN-ReLU), (b) BN after addition, (c) ReLU before addition (pre-activation ReLU only), (d) full pre-activation (BN-ReLU-Conv), and (e) ReLU-only pre-activation. Full pre-activation achieves the best results because BN applied before convolution normalizes the input to each residual function, and the ReLU before convolution ensures the residual branch can learn both positive and negative corrections.
Results
| Model | Dataset | Error |
|---|---|---|
| Pre-activation ResNet-1001 | CIFAR-10 | 4.62% |
| Pre-activation ResNet-200 | ImageNet | 20.7% top-1 |
- A 1001-layer original ResNet (Conv-BN-ReLU ordering) shows degraded training loss compared to 110 layers, confirming that the post-activation design fails at extreme depth
- The pre-activation variant (BN-ReLU-Conv) with 1001 layers achieves 4.62% error on CIFAR-10, outperforming all shallower variants and demonstrating continued benefit from depth
- Identity shortcuts are strictly optimal: experiments with scaling, gating, and 1x1 convolution shortcuts all underperform clean identity mappings across multiple depth configurations
- Pre-activation networks show smaller generalization gaps than post-activation equivalents, suggesting that the BN-ReLU before convolution provides an implicit regularization effect
- On ImageNet, pre-activation ResNet-200 achieves competitive performance while being easier to optimize than the post-activation equivalent, which shows optimization difficulties at this depth
Limitations & Open Questions
- Benefits of pre-activation are most pronounced at extreme depths (>200 layers); for typical ResNet-50/101 configurations used in practice, the difference is marginal
- The analysis assumes residual functions have small magnitudes relative to identity, which may not hold in all training regimes or with aggressive learning rates
- Whether the same principles extend cleanly to non-convolutional architectures (e.g., transformers with residual connections and layer normalization) is not directly explored, though subsequent work confirmed the applicability