SAM 2: Segment Anything in Images and Videos
Overview
SAM 2 extends the Segment Anything Model (SAM) from static image segmentation to unified promptable visual segmentation across both images and videos. Published by Meta FAIR in 2024, the paper addresses a fundamental limitation of the original SAM: while SAM demonstrated exceptional promptable segmentation on images, video introduces additional complexities including object motion, deformation, occlusion, and appearance variation across frames. SAM 2 handles all of these within a single architecture by treating images as single-frame videos.
The core technical insight is a streaming memory architecture that conditions current-frame predictions on a memory bank of past frames and prior interactions. The model uses a MAE-pre-trained Hiera (Hierarchical Vision Transformer) image encoder that is 6x faster than SAM's ViT encoder, a novel memory attention mechanism based on stacked transformer blocks with cross-attention to stored memories, and an enhanced mask decoder with an occlusion prediction head for handling objects that temporarily disappear. The architecture supports interactive refinement at any frame, enabling a natural human-in-the-loop workflow.
Beyond the model itself, SAM 2 introduces the SA-V (Segment Anything Video) dataset -- the largest video segmentation dataset to date -- built through an innovative three-phase data engine that progressively leverages SAM 2 itself to accelerate annotation by 8.4x. SA-V contains 50.9K videos with 642.6K masklets spanning 35.5M masks. On benchmarks, SAM 2 achieves state-of-the-art accuracy across 17 zero-shot video object segmentation datasets while requiring 3x fewer user interactions than prior approaches, and improves on SAM's image segmentation performance (61.9% vs 58.1% 1-click mIoU) at 6x the speed.
Key Contributions
- Promptable Visual Segmentation (PVS) task: Defines a unified task formulation where a model segments any object in images or videos given spatial prompts (points, boxes, masks) at any frame, generalizing SAM's promptable image segmentation to the temporal domain
- Streaming memory architecture: Memory attention module with a FIFO memory bank that stores encoded frame memories plus object pointers, enabling efficient processing of arbitrarily long videos while maintaining temporal consistency
- Occlusion prediction head: Explicit mechanism for predicting whether a tracked object is visible in each frame, enabling robust tracking through temporary disappearances and reappearances
- SA-V dataset and data engine: Three-phase iterative data engine (frame-by-frame SAM -> SAM 2 propagation -> SAM 2 interactive refinement) that reduces per-frame annotation time from 37.8s to 4.5s, producing the largest video segmentation dataset (50.9K videos, 642.6K masklets, 35.5M masks)
- Unified image-video model: A single architecture that treats images as single-frame videos, achieving improved image segmentation over SAM while adding full video capabilities
Architecture / Method
┌──────────────────┐
│ User Prompts │
│ (points/boxes/ │
│ masks) @ any │
│ frame │
└────────┬─────────┘
│
┌────────────────────────────┼────────────────────────────┐
│ SAM 2 Streaming Architecture │
│ │ │
│ ┌─────────────┐ │ ┌──────────────┐ │
│ │ Video Frame │ │ │ Memory Bank │ │
│ │ (current) │ │ │ ┌──────────┐ │ │
│ └──────┬──────┘ │ │ │Recent │ │ │
│ │ │ │ │Frames │ │ │
│ ▼ │ │ │(FIFO) │ │ │
│ ┌──────────────┐ │ │ ├──────────┤ │ │
│ │ Hiera Image │ │ │ │Prompted │ │ │
│ │ Encoder │ │ │ │Frames │ │ │
│ │ (6x faster │ │ │ ├──────────┤ │ │
│ │ than ViT-H) │ │ │ │Object │ │ │
│ └──────┬──────┘ │ │ │Pointers │ │ │
│ │ │ │ └─────┬────┘ │ │
│ ▼ ▼ └───────┼──────┘ │
│ ┌────────────────────────────────────────────┘ │
│ │ Memory Attention │
│ │ (cross-attn to memory bank) │
│ └──────────────┬──────────────────────────────┐ │
│ │ │ │
│ ▼ │ │
│ ┌──────────────────────┐ ┌─────────────┐ │ │
│ │ Prompt Encoder │───►│ Mask Decoder │ │ │
│ └──────────────────────┘ │ + Occlusion │ │ │
│ │ Head │ │ │
│ └──────┬───────┘ │ │
│ │ │ │
│ ┌──────────┴────┐ │ │
│ ▼ ▼ │ │
│ ┌───────────┐ ┌──────────┐ │ │
│ │ Predicted │ │ Memory │──┘ │
│ │ Masks │ │ Encoder │ │
│ └───────────┘ │ (feedback│ │
│ │ to bank)│ │
│ └──────────┘ │
└──────────────────────────────────────────────────────────┘
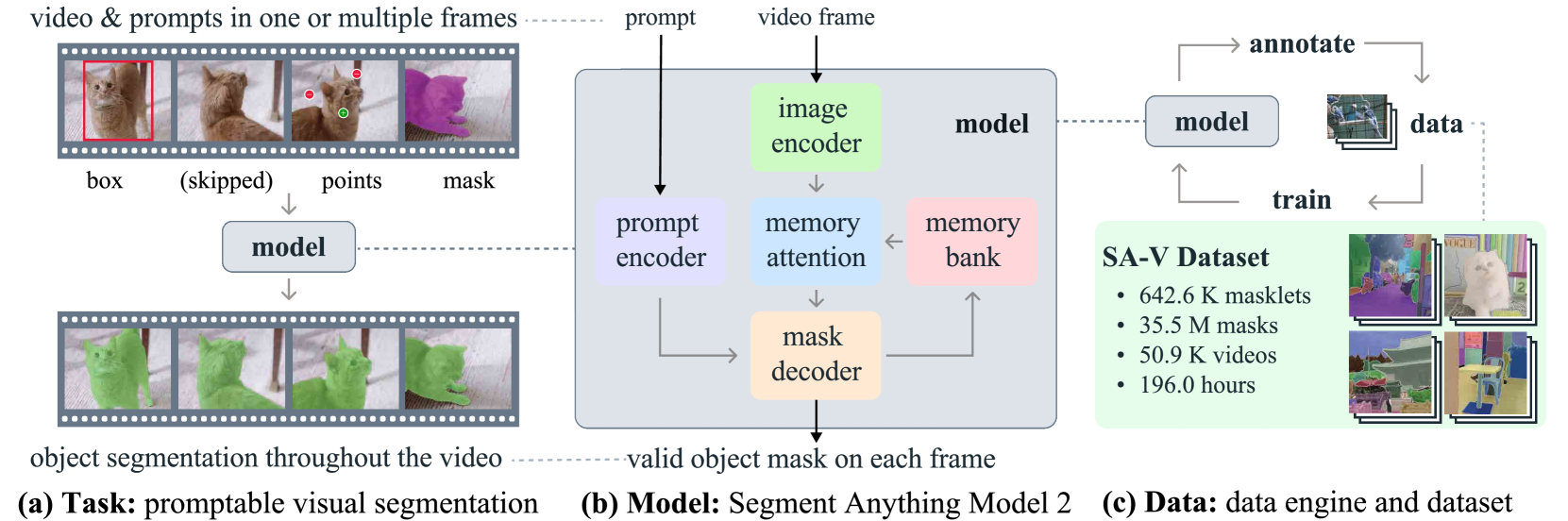
SAM 2's architecture extends the original SAM design with temporal processing components while maintaining real-time efficiency:
Image Encoder (Hiera). A MAE-pre-trained Hierarchical Vision Transformer processes each video frame independently to produce unconditioned feature embeddings. The hierarchical design provides multiscale features for detailed mask decoding. Hiera achieves a 6x speedup over SAM's ViT-H encoder while maintaining competitive representation quality. Model variants range from Hiera-T (tiny) to Hiera-L (large).
Memory Attention. The core innovation for video processing. This module consists of stacked transformer blocks that condition the current frame's image features on temporal context via cross-attention to a memory bank. The memory bank contains: (1) recent frame memories stored in a FIFO queue with temporal positional encodings for short-term motion modeling, (2) prompted frame memories that persist regardless of recency, and (3) object pointers -- high-level semantic embeddings that capture identity information about tracked objects across longer temporal spans.
Prompt Encoder and Mask Decoder. Adapted from SAM with key enhancements: skip connections from the hierarchical image encoder integrate high-resolution details, and the new occlusion prediction head outputs a per-frame visibility score for each tracked object. When the occlusion head predicts an object is not visible, the model avoids corrupting the memory bank with unreliable predictions.
Memory Encoder. After mask prediction, the memory encoder fuses the predicted mask with unconditioned image features to generate a compact memory representation that is added to the memory bank for future frames. This creates a feedback loop where each prediction informs subsequent ones.
The model operates in a streaming fashion: for each new frame, the image encoder produces features, memory attention conditions them on stored context, the mask decoder produces segmentation masks, and the memory encoder stores the result. Users can intervene at any frame with corrective prompts, which are incorporated into the memory bank as high-priority prompted memories.
Model sizes and throughput:
| Variant | Encoder | FPS (A100) |
|---|---|---|
| SAM 2 (Hiera-T) | Hiera-Tiny | ~47 |
| SAM 2 (Hiera-S) | Hiera-Small | ~46 |
| SAM 2 (Hiera-B+) | Hiera-Base+ | 43.8 |
| SAM 2 (Hiera-L) | Hiera-Large | 30.2 |
Training. The model is trained on a mixture of image data (SA-1B from SAM) and video data (SA-V plus existing VOS datasets). The training procedure uses a simulated interactive setting where prompts are sampled to mimic human annotation workflows. Loss functions include focal loss and dice loss for mask prediction, MAE loss for IoU prediction, and cross-entropy loss for the occlusion head.
Results
SAM 2 demonstrates strong performance across three evaluation axes:
Interactive Video Segmentation
In simulated interactive evaluation across 9 densely annotated zero-shot video datasets, SAM 2 significantly outperforms strong baselines (SAM + XMem++ and SAM + Cutie), achieving better segmentation accuracy with over 3x fewer user interactions. This dramatic reduction in annotation effort validates the streaming memory design.
Semi-supervised Video Object Segmentation (VOS)
Using only first-frame prompting on conventional VOS benchmarks:
| Method | Type | SA-V test | DAVIS 2017 | MOSE |
|---|---|---|---|---|
| XMem++ | Specialized VOS | -- | ~86 | -- |
| Cutie | Specialized VOS | -- | ~87 | -- |
| SAM 2 (Hiera-B+) | Foundation model | SOTA | SOTA | SOTA |
| SAM 2 (Hiera-L) | Foundation model | SOTA | SOTA | SOTA |
SAM 2 achieved state-of-the-art accuracy across 17 diverse video datasets, outperforming specialized VOS methods even when using click or box inputs rather than ground-truth first-frame masks.
Image Segmentation
| Method | SA-23 1-click mIoU | Speed vs SAM |
|---|---|---|
| SAM (ViT-H) | 58.1% | 1x |
| SAM 2 (image-only training) | 58.9% | 6x |
| SAM 2 (image+video training) | 61.9% | 6x |
Training on mixed image and video data improves image segmentation by 3.8 points over SAM while running 6x faster, demonstrating that video understanding provides a complementary training signal even for static image tasks.
Data Engine Efficiency
| Phase | Method | Time per frame | Speedup |
|---|---|---|---|
| Phase 1 | SAM frame-by-frame | 37.8s | 1x |
| Phase 2 | SAM 2 propagation | 7.4s | 5.1x |
| Phase 3 | SAM 2 interactive | 4.5s | 8.4x |
Limitations & Open Questions
- Memory capacity: The FIFO memory bank has fixed capacity; very long videos or scenes with many objects may exceed its ability to maintain all relevant context
- Occlusion handling: While the occlusion head is a significant improvement, extended occlusions (object disappears for many frames) remain challenging since the memory bank may flush relevant information
- Domain specificity: The model is trained primarily on natural video; performance on specialized domains (medical imaging, satellite video, microscopy) is not extensively evaluated
- Computational cost of memory attention: Cross-attention to the memory bank scales with the number of stored memories, creating a latency-throughput tradeoff for long sequences
- Single-object tracking assumption: The model tracks objects independently; multi-object interactions (occlusion reasoning between tracked objects) are not explicitly modeled
Connections
Related papers in the wiki: - An Image Is Worth 16X16 Words Transformers For Image Recognition At Scale -- ViT established transformers for vision; SAM 2's Hiera encoder builds on the hierarchical vision transformer lineage - Attention Is All You Need -- Transformer architecture underlying the memory attention and mask decoder - Deep Residual Learning For Image Recognition -- ResNet skip connections are a precursor to the skip connections used in SAM 2's mask decoder - Denoising Diffusion Probabilistic Models -- SAM 2 and diffusion models represent complementary foundation model paradigms for visual understanding vs generation - Perception -- SAM 2's segmentation capabilities are directly relevant to perception in autonomous systems - Foundation Models -- SAM 2 exemplifies the foundation model approach: large-scale pretraining on diverse data with prompting-based task adaptation - Computer Vision -- Broader context for visual segmentation research