Hierarchical Text-Conditional Image Generation with CLIP Latents (DALL-E 2)
Overview
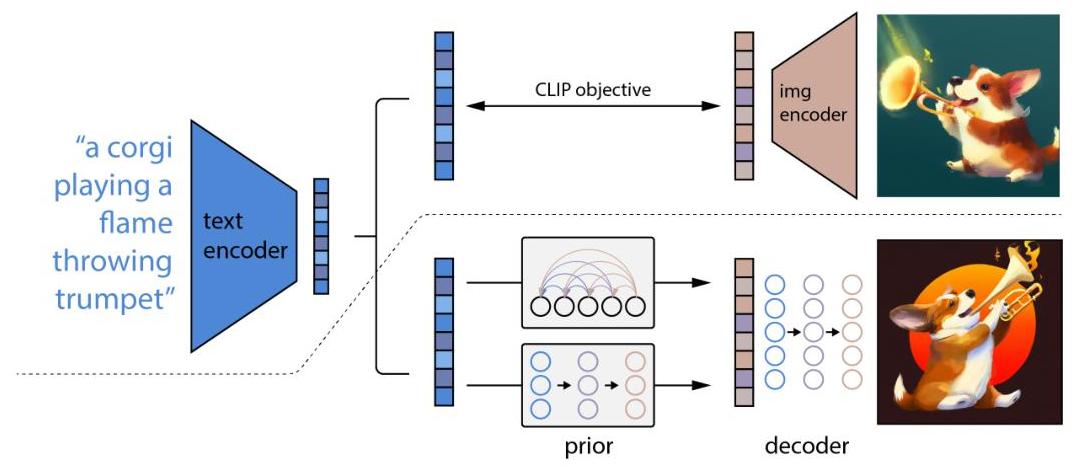
DALL-E 2 (internally called unCLIP) introduces a hierarchical approach to text-conditional image generation that leverages CLIP's joint text-image embedding space as an intermediate representation. Rather than generating images directly from text, the system first produces a CLIP image embedding from a text caption using a "prior" model, then generates an image conditioned on that embedding using a diffusion-based "decoder." This two-stage decomposition separates the problem of understanding semantics (handled by the prior, operating in CLIP space) from the problem of generating pixels (handled by the decoder), enabling stronger compositional understanding and higher-fidelity outputs.
The key insight is that CLIP embeddings capture the semantic essence of images -- what objects are present, their relationships, and stylistic attributes -- while discarding low-level pixel details. By inverting CLIP's mapping (hence "unCLIP"), the system can generate images that faithfully reflect text semantics while preserving the diversity of plausible visual interpretations. The prior model can be either autoregressive or diffusion-based; the authors find that the diffusion prior produces higher-quality outputs and is more computationally efficient.
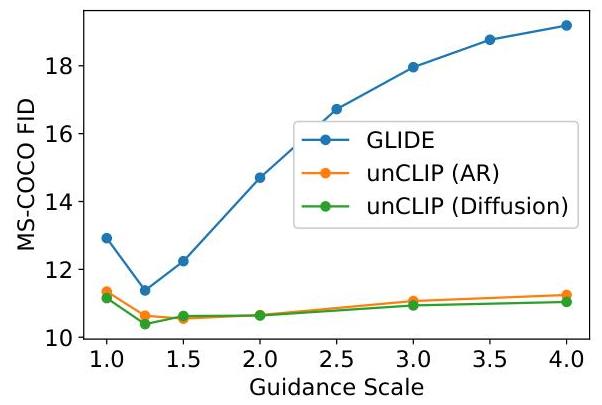
DALL-E 2 achieves state-of-the-art FID of 10.39 on MS-COCO zero-shot image generation while maintaining significantly greater sample diversity than GLIDE (its predecessor), especially at higher classifier-free guidance scales. The approach also enables novel image manipulation capabilities including variations of a given image (by re-decoding its CLIP embedding with different random seeds), interpolation between images in CLIP space, and text-guided image editing. The paper was highly influential in establishing the CLIP-latent paradigm for generative models and contributed to the broader wave of text-to-image systems that followed (Stable Diffusion, Imagen, etc.).
Key Contributions
- Two-stage hierarchical generation via CLIP latents: Introduces the prior-decoder decomposition where a prior maps text to CLIP image embeddings and a decoder generates images from those embeddings, separating semantic understanding from pixel generation
- Diffusion prior over CLIP space: Demonstrates that a diffusion model trained to produce CLIP image embeddings from text embeddings outperforms an autoregressive prior in both quality (FID) and computational efficiency
- Superior diversity-fidelity trade-off: Achieves Pareto-optimal performance compared to GLIDE -- comparable or better photorealism with substantially more diverse outputs, particularly at higher guidance scales where GLIDE collapses in diversity
- Novel image manipulation capabilities: Enables bipartite image-text representations that support image variations, CLIP-space interpolation, and language-guided image editing as natural byproducts of the architecture
- Analysis of CLIP's representation gaps: Identifies systematic failure modes (attribute binding, spatial relationships, text rendering) rooted in CLIP's contrastive training objective, providing diagnostic insight for future work
Architecture / Method
┌──────────────────────────────────────────────────────────────────┐
│ DALL-E 2 (unCLIP) PIPELINE │
│ │
│ "a painting of │
│ a fox in a field" │
│ │ │
│ ▼ │
│ ┌────────────────┐ │
│ │ CLIP Text │──── z_t (text embedding) │
│ │ Encoder (frozen)│ │
│ └────────────────┘ │
│ │ │
│ │ z_t + caption tokens │
│ ▼ │
│ ┌────────────────┐ P(z_i | y) │
│ │ Diffusion Prior │──── z_i (predicted CLIP image embedding) │
│ │ (Transformer) │ x-prediction parameterization │
│ └────────────────┘ + classifier-free guidance │
│ │ │
│ │ z_i + caption │
│ ▼ │
│ ┌────────────────┐ P(x | z_i, y) │
│ │ Decoder │──── 64x64 image │
│ │ (Modified GLIDE)│ z_i injected via: │
│ │ │ - added to timestep embed │
│ │ │ - 4 extra context tokens │
│ └────────────────┘ │
│ │ │
│ ▼ │
│ ┌────────────────┐ ┌────────────────┐ │
│ │ Upsample 1 │────►│ Upsample 2 │──── 1024x1024 │
│ │ 64 ─► 256 │ │ 256 ─► 1024 │ final image │
│ └────────────────┘ └────────────────┘ │
└──────────────────────────────────────────────────────────────────┘
Overall Pipeline
The system consists of three components trained independently:
-
CLIP (frozen): A pre-trained CLIP model (ViT-H/16 image encoder, transformer text encoder) provides the shared embedding space. Given a text caption $y$, the text encoder produces $z_t$; given an image $x$, the image encoder produces $z_i$. The CLIP model is frozen during all subsequent training.
-
Prior: Maps from a text caption (specifically, from the CLIP text embedding $z_t$ plus the raw caption tokens) to a CLIP image embedding $z_i$. Two variants are explored: - Autoregressive prior: Converts the CLIP image embedding to a sequence of discrete tokens via PCA and quantization, then models these autoregressively conditioned on the caption and CLIP text embedding. - Diffusion prior: A Gaussian diffusion model that directly predicts the (continuous) CLIP image embedding. Uses a decoder-only transformer architecture operating on a sequence of: the encoded text, the CLIP text embedding, a timestep embedding, the noised CLIP image embedding, and a final embedding whose output is used as the prediction. Classifier-free guidance is applied by randomly dropping the text conditioning during training.
-
Decoder: A modified GLIDE diffusion model that generates 64x64 images conditioned on the CLIP image embedding $z_i$ (projected and added to the existing timestep embedding, and also projected to four extra context tokens concatenated to the GLIDE text tokens). Two upsampling diffusion models then bring the resolution to 256x256 and 1024x1024.
Key Design Choices
- The diffusion prior uses an $x$-prediction parameterization (predicting the clean embedding rather than noise), which the authors find works better than $\epsilon$-prediction in the CLIP latent space
- Classifier-free guidance is applied at both the prior and decoder stages, with separate guidance scales -- the prior guidance scale trades off diversity for fidelity in CLIP space, while the decoder guidance scale controls photorealism
- The decoder conditions on CLIP embeddings via two pathways: additive projection to the timestep embedding and concatenation as extra context tokens to the text encoder output
Generation Factorization
The generative process factorizes as:
$$P(x|y) = P(x|z_i, y) \cdot P(z_i|y)$$
where $P(z_i|y)$ is the prior and $P(x|z_i, y)$ is the decoder. The caption $y$ is passed to the decoder as well, but the authors find the CLIP embedding carries most of the semantic information.
Results
Zero-shot MS-COCO 256x256
| Method | FID ↓ | IS ↑ |
|---|---|---|
| DALL-E (2021) | 27.5 | — |
| GLIDE | 12.24 | — |
| Make-A-Scene | 11.84 | — |
| DALL-E 2 (unCLIP) | 10.39 | — |
Key Findings
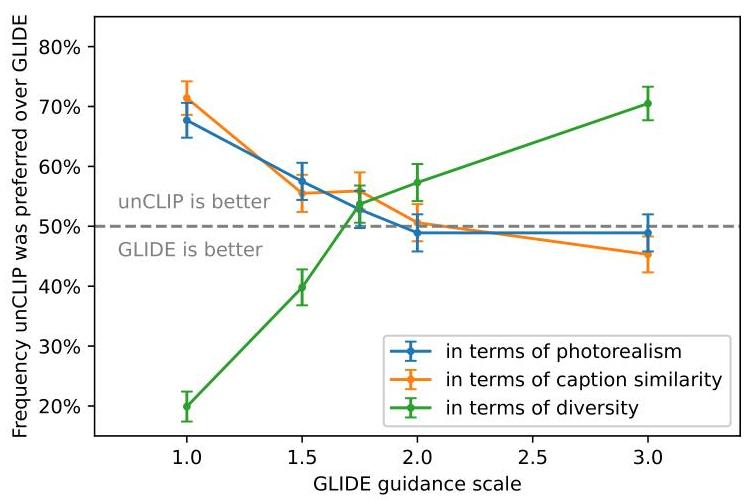
- Diversity advantage: Human evaluators prefer unCLIP over GLIDE for diversity (photo and caption similarity) while GLIDE is preferred slightly for photorealism. At higher guidance scales, GLIDE's diversity drops sharply while unCLIP maintains it.
- Prior comparison: The diffusion prior achieves better FID than the autoregressive prior on MS-COCO while being substantially more compute-efficient (the AR prior requires hundreds of tokens per sample).
- Ablation -- conditioning signals: Conditioning the decoder on both the CLIP embedding and the text caption outperforms either alone; dropping the text caption has minimal impact (most information is in the CLIP embedding), but dropping the CLIP embedding significantly degrades quality.
Limitations & Open Questions
- Attribute binding: DALL-E 2 struggles to bind attributes to the correct objects (e.g., "a red cube on a blue cube" may swap colors). This is traced to CLIP's bag-of-concepts representation, which lacks explicit compositional structure.
- Spatial relationships: The system has difficulty with precise spatial arrangements, again reflecting CLIP's limitations in encoding positional information.
- Text rendering: Producing legible text in images is a known weakness, likely because CLIP's BPE text encoding and contrastive training do not incentivize pixel-level text fidelity.
- Reconstruction fidelity: Since CLIP embeddings discard fine-grained details, exact image reconstruction is not possible -- the system always introduces variations in low-level details when re-decoding.
- Two-stage complexity: The hierarchical approach requires training multiple models (CLIP, prior, decoder, upsamplers), each with its own hyperparameters and failure modes, increasing system complexity relative to single-stage approaches like Imagen.
Connections
Related papers in the wiki: - Learning Transferable Visual Models From Natural Language Supervision — CLIP provides the foundational embedding space that DALL-E 2 inverts; the entire approach depends on CLIP's semantic quality - Denoising Diffusion Probabilistic Models — The diffusion framework used by both the prior and decoder components builds directly on DDPM - Attention Is All You Need — The transformer architecture underlies CLIP's encoders and the diffusion prior's backbone - An Image Is Worth 16X16 Words Transformers For Image Recognition At Scale — ViT-H/16 serves as DALL-E 2's image encoder within CLIP - Language Models Are Few Shot Learners — GPT-3 established the large-scale generative paradigm that DALL-E 2 extends to the image domain - Foundation Models — DALL-E 2 exemplifies the foundation model approach: large-scale pretraining (CLIP) plus task-specific adaptation (prior + decoder)