YOLOv10: Real-Time End-to-End Object Detection
Overview
Real-time object detection is critical infrastructure for autonomous driving, robotics, and augmented reality, yet the dominant YOLO family has long relied on non-maximum suppression (NMS) for post-processing, which introduces latency, complicates deployment, and makes the pipeline non-differentiable. YOLOv10 eliminates NMS entirely by introducing consistent dual assignments -- a training strategy that combines one-to-many label assignment (for rich supervision) with one-to-one matching (for NMS-free inference). The matching metric is defined as m = s * p^alpha * IoU(b_hat, b)^beta, ensuring the one-to-one head converges toward predictions consistent with the one-to-many head.
Beyond the NMS-free design, YOLOv10 performs a holistic efficiency-accuracy optimization of the YOLO architecture. On the efficiency side, it introduces a lightweight classification head (decoupled from the regression head to reduce parameters), spatial-channel decoupled downsampling (separating spatial reduction from channel expansion), and rank-guided block design (allocating computational budget based on measured intrinsic rank of each stage). On the accuracy side, it adds large-kernel convolutions for expanded receptive fields and Partial Self-Attention (PSA) that applies self-attention to only a fraction of channels, capturing global context without the full quadratic cost.
YOLOv10 establishes a new Pareto frontier on COCO. Across six model scales (N/S/M/B/L/X), it achieves 0.3--1.4% AP improvement over YOLOv8 while reducing parameters by 28--57%, FLOPs by 23--38%, and latency by 37--70%. YOLOv10-S runs 1.8x faster than RT-DETR-R18 with similar accuracy. The paper was published at NeurIPS 2024 from Tsinghua University.
Key Contributions
- Consistent dual assignments for NMS-free training: one-to-many head provides dense supervision during training while one-to-one head enables direct end-to-end inference, with a consistency regularization loss aligning the two
- Lightweight classification head: decouples classification from regression, using depthwise separable convolutions to cut classification head overhead significantly
- Spatial-channel decoupled downsampling: separates spatial reduction (depthwise conv) from channel expansion (pointwise conv), avoiding the information loss of joint stride-2 convolutions
- Rank-guided block design: analyzes intrinsic rank of feature maps at each stage and replaces redundant blocks with compact inverted blocks (CIB) where rank is low, reducing computation without accuracy loss
- Partial Self-Attention (PSA): applies multi-head self-attention to only a subset of channels (e.g., 1/4), concatenating attended and unattended features, to add global context at minimal cost
Architecture
┌──────────────────────────────────────────────────────────┐
│ YOLOv10 Architecture │
│ │
│ Input Image │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────┐ │
│ │ CSPDarknet Backbone │ │
│ │ ┌───────────────────────────┐ │ │
│ │ │ Rank-guided block design: │ │ │
│ │ │ Low rank → CIB (compact) │ │ │
│ │ │ High rank → standard │ │ │
│ │ └───────────────────────────┘ │ │
│ │ + Large-kernel DWConv (7x7) │ (L/X models) │
│ │ + Decoupled downsampling: │ │
│ │ PWConv(1x1) → DWConv(s=2) │ │
│ └──────────────┬───────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────┐ │
│ │ PAN Neck + SPPF │ │
│ │ ┌───────────────────────────┐ │ │
│ │ │ Partial Self-Attention │ │ │
│ │ │ MHSA on 1/4 channels │ │ │
│ │ │ concat with unattended │ │ │
│ │ └───────────────────────────┘ │ │
│ └──────┬──────────────┬────────────┘ │
│ │ │ │
│ ┌────▼────┐ ┌────▼────┐ │
│ │One-to- │ │One-to- │ │
│ │ Many │ │ One │ │
│ │ Head │ │ Head │ ◄── Hungarian matching │
│ │(TAL) │ │(NMS-free│ │
│ └────┬────┘ └────┬────┘ │
│ │ │ │
│ Train only Inference │
│ (dense grad) (end-to-end) │
│ │
│ Consistency loss aligns one-to-one with one-to-many │
└──────────────────────────────────────────────────────────┘
Architecture / Method
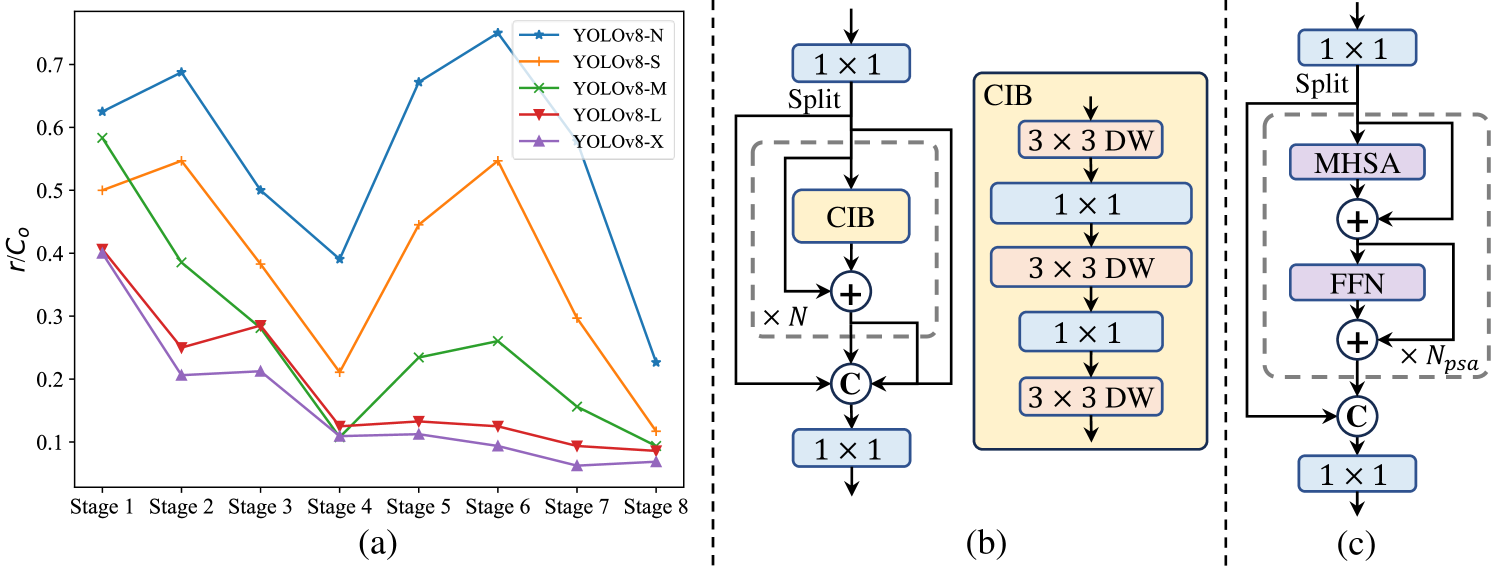
YOLOv10 builds on the standard YOLO architecture (CSPDarknet backbone + PAN neck + detection heads) with targeted modifications at each level:
Backbone and neck: The rank-guided block design replaces standard bottleneck blocks with Compact Inverted Blocks (CIB) in stages where the intrinsic rank of features is low (indicating redundancy). CIB uses an inverted bottleneck structure (expand channels -> depthwise 3x3 -> compress) that is more parameter-efficient. Larger models (L/X) additionally integrate large-kernel depthwise convolutions (7x7) to expand the effective receptive field without adding dense parameters.
Downsampling: Standard YOLO downsampling uses stride-2 convolutions that simultaneously halve spatial resolution and double channels. YOLOv10 decouples this into two steps: (1) a pointwise 1x1 conv for channel adjustment, (2) a depthwise conv with stride 2 for spatial reduction. This avoids the information bottleneck of joint spatial-channel transformation.
Detection heads: The classification head is made lightweight by using depthwise separable convolutions instead of standard 3x3 convolutions, since classification is less spatially sensitive than bounding box regression. The regression head retains standard convolutions for precise localization.
Partial Self-Attention: Applied after the SPPF module in the neck. PSA splits features along the channel dimension, applies MHSA to one partition (e.g., 1/4 of channels), and concatenates back with the unprocessed partition. This provides global dependency modeling at a fraction of the cost of full self-attention.
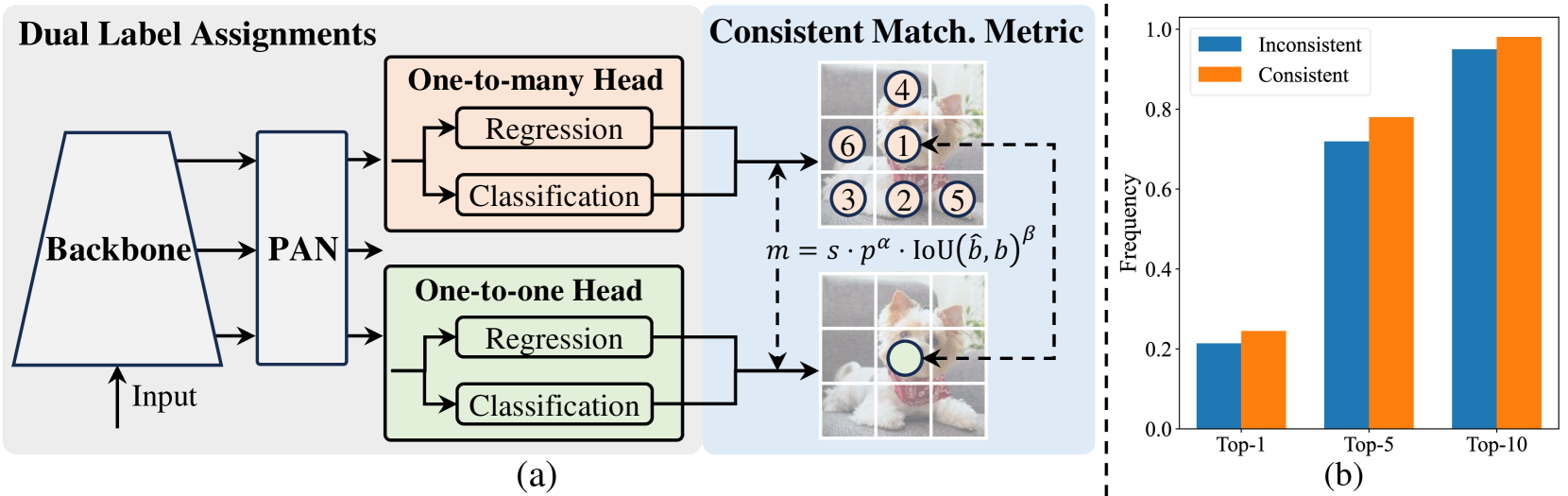
Dual label assignments: During training, two parallel heads operate on the same neck features. The one-to-many head uses standard YOLO assignment (TAL) assigning multiple anchors per ground truth for dense gradients. The one-to-one head uses Hungarian matching (like DETR) assigning exactly one prediction per ground truth. A consistency loss based on 1-Wasserstein distance encourages the one-to-one head to learn from the one-to-many head's richer supervision. At inference, only the one-to-one head is used, eliminating NMS entirely.
Results
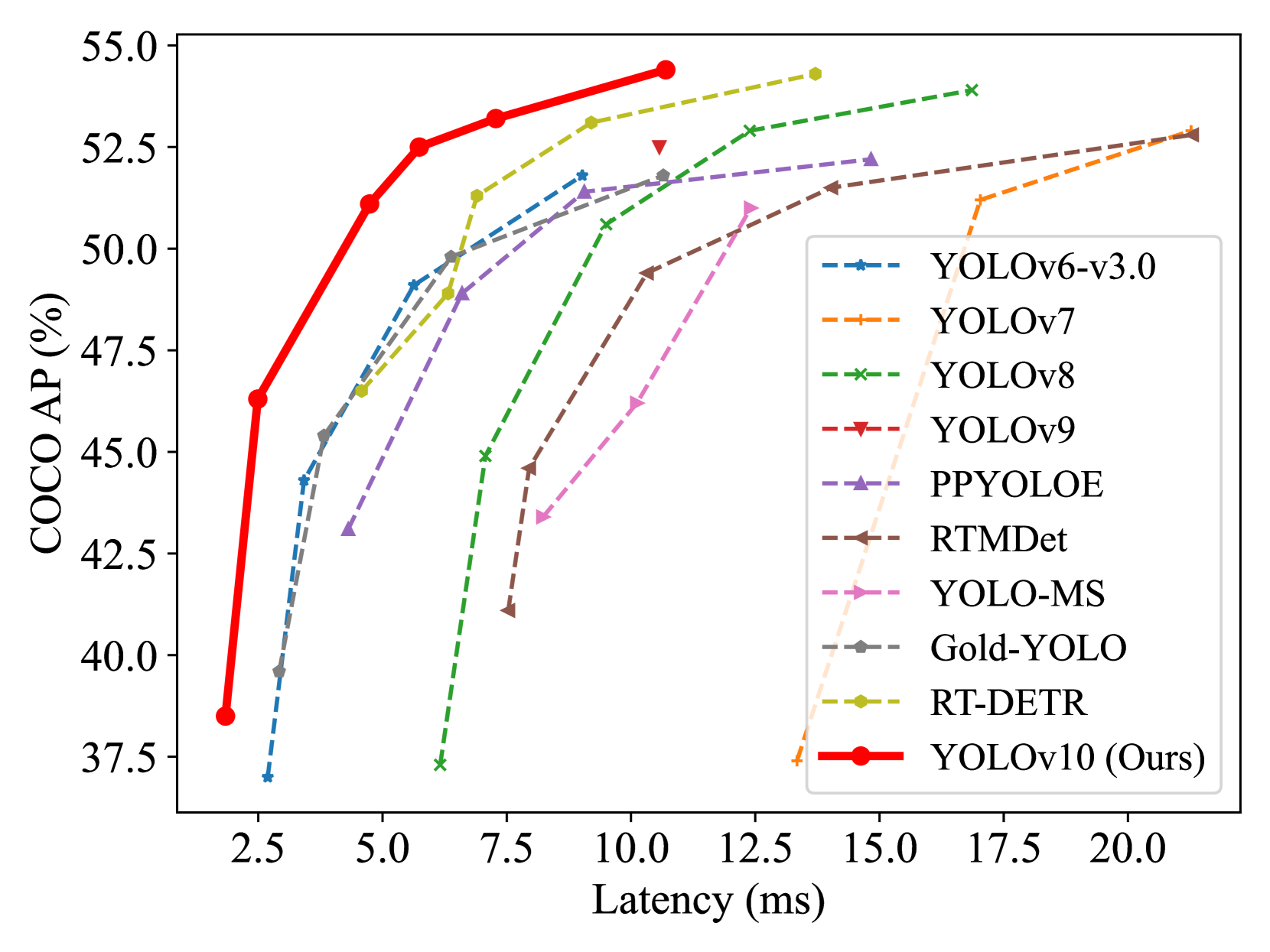
YOLOv10 achieves state-of-the-art latency-accuracy trade-offs across all model scales on COCO val2017:
| Model | AP (%) | Params (M) | FLOPs (G) | Latency (ms) |
|---|---|---|---|---|
| YOLOv10-N | 38.5 | 2.3 | 6.7 | 1.84 |
| YOLOv10-S | 46.3 | 7.2 | 21.6 | 2.49 |
| YOLOv10-M | 51.1 | 15.4 | 59.1 | 4.74 |
| YOLOv10-B | 52.5 | 19.1 | 92.0 | 5.74 |
| YOLOv10-L | 53.2 | 24.4 | 120.3 | 7.28 |
| YOLOv10-X | 54.4 | 29.5 | 160.4 | 10.70 |
| YOLOv8-S | 44.9 | 11.2 | 28.6 | 6.16 |
| YOLOv8-M | 50.6 | 25.9 | 78.9 | 9.50 |
| YOLOv9-C | 52.5 | 25.3 | 102.1 | 10.57 |
| RT-DETR-R18 | 46.5 | 20.0 | 60.0 | 4.58 |
Key comparisons: YOLOv10-S achieves 1.4% higher AP than YOLOv8-S with 36% fewer parameters and 65% lower latency. YOLOv10-B matches YOLOv9-C AP while using 25% fewer parameters and 46% less latency.
Ablation highlights: Removing NMS from YOLOv8 via naive one-to-one assignment costs ~1% AP; the consistent dual assignment strategy recovers this entirely. The rank-guided block design saves 8--14% FLOPs with <0.1% AP change. PSA adds ~0.3% AP at negligible latency cost.

Limitations & Open Questions
- Small model gap: The paper acknowledges a persistent performance gap between one-to-one and one-to-many assignments in smaller models (N/S), suggesting the consistency regularization is less effective when model capacity is limited
- COCO-centric evaluation: All results are on COCO; generalization to other domains (medical imaging, satellite imagery, long-tail distributions) is not explored
- Feature discriminability: The authors identify improving feature discriminability as a key direction -- PSA helps but full self-attention may be needed for complex scenes
- Theoretical analysis: The 1-Wasserstein distance analysis provides intuition for why dual assignments work but does not yield tight convergence guarantees
Connections
Related papers in the wiki: - Deep Residual Learning For Image Recognition -- ResNet backbone architecture widely used in detection; YOLOv10 builds on similar stage-based design principles - Attention Is All You Need -- Transformer self-attention mechanism that PSA partially adopts for global context - Imagenet Classification With Deep Convolutional Neural Networks -- AlexNet pioneered CNN-based visual recognition that YOLO detectors evolved from - An Image Is Worth 16X16 Words Transformers For Image Recognition At Scale -- ViT demonstrated pure transformer vision; RT-DETR (key baseline) uses ViT-derived backbones - Perception -- Object detection is a core perception task in autonomous driving stacks - Autonomous Driving -- Real-time detection is a prerequisite for driving perception pipelines