Exploring Simple Siamese Representation Learning
Overview
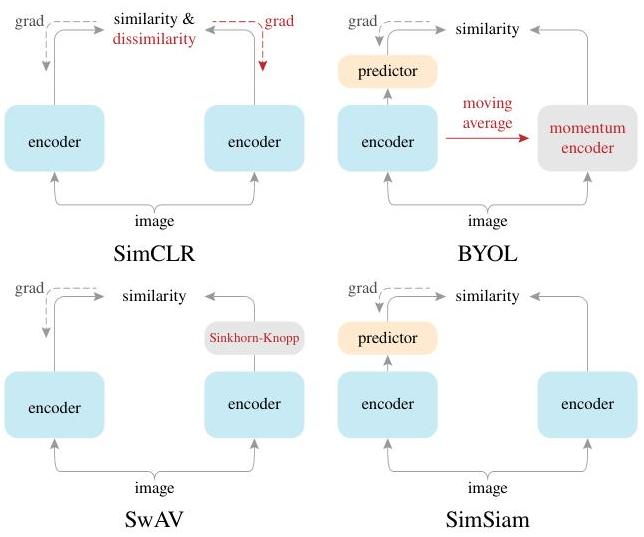
SimSiam (Simple Siamese) demonstrates that self-supervised visual representation learning can be dramatically simplified while maintaining competitive performance. Prior methods for learning visual representations without labels relied on increasingly complex machinery: SimCLR required large batches and negative pairs, MoCo used a momentum encoder and memory bank, BYOL used a momentum encoder to avoid collapse, and SwAV employed online clustering. SimSiam strips away all of these components, showing that none of them are strictly necessary. The method uses only a standard Siamese network with a prediction MLP on one branch and a stop-gradient operation on the other -- no negative pairs, no large batches, no momentum encoders.
The core insight is that the stop-gradient operation alone is sufficient to prevent representational collapse (where all inputs map to the same output). Without stop-gradient, the network collapses to trivial constant solutions and achieves only ~0.1% accuracy (random chance). With it, the method achieves 68.1% ImageNet top-1 accuracy at 100 epochs and 70.0% at 200 epochs under linear evaluation, competitive with far more complex methods. The authors provide a theoretical interpretation connecting SimSiam to an Expectation-Maximization (EM) algorithm, where the stop-gradient implicitly creates alternating optimization between a fixed target set and a prediction step.
SimSiam's significance extends beyond its empirical results. By isolating the minimal mechanism needed for self-supervised learning, it clarifies which components of prior methods were essential (augmentation diversity, the predictor, stop-gradient) and which were incidental (negative samples, momentum encoders, large batches). This conceptual clarity influenced subsequent work on self-supervised learning and made the technique accessible to researchers with limited computational resources, since SimSiam works well even with batch sizes as small as 64.
Key Contributions
- Minimal self-supervised framework: Achieves competitive performance using only a Siamese network with shared weights, a prediction MLP, and stop-gradient -- no negative pairs, momentum encoders, large batches, or online clustering required
- Stop-gradient as the critical mechanism: Empirically demonstrates that removing stop-gradient causes immediate collapse (0.1% accuracy), establishing it as the single essential component for preventing trivial solutions in non-contrastive self-supervised learning
- Batch size robustness: Unlike SimCLR which degrades significantly at small batch sizes, SimSiam maintains strong performance across batch sizes from 64 to 4,096, enabling self-supervised learning on modest hardware
- EM algorithm interpretation: Provides a theoretical framework connecting SimSiam to alternating optimization, explaining why the method does not collapse despite having no explicit mechanism to enforce diverse representations
- Systematic ablation of prior methods: Disentangles the contributions of negative pairs (SimCLR), momentum encoders (MoCo/BYOL), and clustering (SwAV), showing none are necessary for the core learning signal
Architecture / Method
┌─────────────────────────────────────────────────────────────────┐
│ SimSiam Architecture │
│ │
│ ┌───────────┐ │
│ │ Image │ │
│ └─────┬─────┘ │
│ ┌──────────┴──────────┐ │
│ │ Random Augment │ │
│ ▼ ▼ │
│ ┌─────────┐ ┌─────────┐ │
│ │ x1 │ │ x2 │ │
│ └────┬────┘ └────┬────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌────────────────────┐ ┌────────────────────┐ │
│ │ Encoder f │ │ Encoder f │ (shared │
│ │ (ResNet-50 │ │ (ResNet-50 │ weights) │
│ │ + 3-layer proj) │ │ + 3-layer proj) │ │
│ └─────────┬──────────┘ └─────────┬──────────┘ │
│ │ z1 │ z2 │
│ ▼ │ │
│ ┌────────────────────┐ │ │
│ │ Prediction MLP h │ │ │
│ │ (2048─►512─►2048) │ │ │
│ └─────────┬──────────┘ │ │
│ │ p1 │ │
│ │ │ │
│ ▼ ▼ │
│ ┌─────────────────────────────────────┐ │
│ │ L = -cosine_sim(p1, stopgrad(z2)) │ │
│ │ (symmetrized: + D(p2, sg(z1))) │ │
│ └─────────────────────────────────────┘ │
│ │
│ Key: stop-gradient on z2 prevents collapse. │
│ Without it ──► 0.1% accuracy (random chance). │
└─────────────────────────────────────────────────────────────────┘
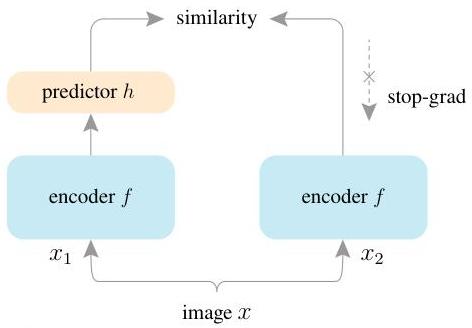
SimSiam processes two randomly augmented views (x1, x2) of the same image through a shared encoder network f (a backbone such as ResNet-50 followed by a projection MLP). The encoder produces representations z1 = f(x1) and z2 = f(x2). A prediction MLP h is applied to one branch: p1 = h(z1). The loss is a negative cosine similarity between the prediction from one view and the (stop-gradiented) representation of the other view:
Loss function: D(p1, z2) = -p1 / ||p1|| . z2 / ||z2||
The total loss is symmetrized: L = (1/2) * D(p1, stopgrad(z2)) + (1/2) * D(p2, stopgrad(z1))
The stop-gradient (stopgrad) operation on z2 means that the gradient does not flow back through the encoder for the target branch -- z2 is treated as a fixed target. This asymmetry between the two branches is the key mechanism preventing collapse. Without it, the loss has a trivial minimum where all outputs are identical constants.
Encoder architecture: The backbone is a standard ResNet-50. The projection MLP has 3 layers: fc(2048, 2048) -> BN -> ReLU -> fc(2048, 2048) -> BN -> ReLU -> fc(2048, 2048) -> BN (no ReLU on the last layer). The prediction MLP h has 2 layers: fc(2048, 512) -> BN -> ReLU -> fc(512, 2048), with a bottleneck structure reducing dimensionality to 512 before projecting back to 2048.
Data augmentation: SimSiam uses the same augmentation pipeline as BYOL: random resized crop (224x224), random horizontal flip, color jittering (brightness, contrast, saturation, hue), random grayscale conversion, and Gaussian blur. The diversity of augmentations is important -- overly weak augmentations degrade performance.
EM interpretation: The authors hypothesize that SimSiam implicitly solves an EM-like problem. The stop-gradient creates a situation analogous to the E-step (computing target assignments with fixed model parameters) alternating with the M-step (updating model parameters with fixed targets). This alternating optimization naturally avoids collapse because the targets are not trivially minimizable -- they depend on the data distribution.

Results
SimSiam achieves competitive performance across ImageNet linear evaluation, semi-supervised learning, and transfer learning benchmarks:
| Method | Negative Pairs | Momentum Encoder | Large Batch | ImageNet Top-1 (100ep) | ImageNet Top-1 (200ep) |
|---|---|---|---|---|---|
| SimSiam | No | No | No | 68.1 | 70.0 |
| SimCLR | Yes | No | Yes (4096) | 66.5 | 68.3 |
| MoCo v2 | Yes | Yes | No | 67.4 | 69.9 |
| BYOL | No | Yes | Yes (4096) | 66.5 | 70.6 |
| SwAV | No | No | Yes (4096) | 66.5 | 69.1 |
Transfer learning (VOC07 detection): SimSiam achieves 57.0 AP50, outperforming the supervised ImageNet baseline (53.5) and competitive with MoCo v2 (57.4) and BYOL (57.1).
Semi-supervised (1% ImageNet labels): SimSiam achieves 91.8% top-5 accuracy using a ResNet-50 encoder, surpassing SimCLR's 91.1%.
Key ablation findings: - Removing the prediction MLP causes collapse (stop-gradient alone is not sufficient) - Removing stop-gradient causes collapse (the prediction MLP alone is not sufficient) - Both components are necessary and neither alone is sufficient - Batch normalization in the MLP layers is important but not strictly required (removing it reduces accuracy by ~2%) - Performance is stable across batch sizes 64-4096, in contrast to SimCLR which requires large batches
Limitations & Open Questions
- Scaling behavior: The paper evaluates primarily on ResNet-50; behavior at larger backbone scales (ViT, larger ResNets) and with longer training schedules was less explored at publication time
- Theoretical understanding remains incomplete: The EM interpretation is a hypothesis supported by empirical evidence but not a formal proof; the precise mechanism preventing collapse is not fully understood mathematically
- Augmentation dependence: Like all self-supervised methods, SimSiam's performance is sensitive to the choice and strength of data augmentations -- the method itself does not address how to select augmentations for new domains
- Downstream task generalization: While transfer results are strong, the method was primarily evaluated on image classification and detection; its effectiveness for dense prediction tasks (segmentation, depth) and non-vision domains is less thoroughly studied
- Relationship to feature decorrelation: Later work (Barlow Twins, VICReg) showed that explicit decorrelation losses also prevent collapse without negative pairs or stop-gradient, raising the question of whether stop-gradient implicitly encourages decorrelation
Connections
Related papers in the wiki: - Learning Transferable Visual Models From Natural Language Supervision -- CLIP uses contrastive learning between vision and language; SimSiam shows contrastive negatives are unnecessary for vision-only self-supervision - An Image Is Worth 16X16 Words Transformers For Image Recognition At Scale -- ViT provides the backbone architecture that later self-supervised methods (DINO, MAE) applied SimSiam-like ideas to - Deep Residual Learning For Image Recognition -- ResNet-50 is the primary backbone used in SimSiam experiments - Bert Pre Training Of Deep Bidirectional Transformers For Language Understanding -- BERT's masked pretraining is the NLP analog of self-supervised visual representation learning - Machine Learning -- SimSiam fits into the broader self-supervised pretraining paradigm - Foundation Models -- Self-supervised methods like SimSiam are precursors to modern foundation model pretraining