High-Resolution Image Synthesis with Latent Diffusion Models
Overview
Latent Diffusion Models (LDMs), the architecture behind Stable Diffusion, address the prohibitive computational cost of applying diffusion models directly in pixel space. The core insight is to decompose image generation into two stages: first, an autoencoder compresses images into a lower-dimensional latent space that preserves perceptually relevant information; second, a diffusion model operates entirely in this compressed latent space. This separation of perceptual compression from generative modeling yields dramatic efficiency gains -- LDM-4 achieves 2.7x faster inference than pixel-based diffusion while improving FID scores -- making high-resolution image synthesis accessible on consumer hardware.
The paper introduces a flexible cross-attention conditioning mechanism integrated into the UNet denoiser. Domain-specific encoders preprocess conditioning inputs (text prompts, semantic maps, class labels, bounding boxes) into intermediate representations that interact with the diffusion model's features through cross-attention layers. This unified conditioning interface enables a single architecture to excel across text-to-image generation, layout-to-image synthesis, semantic synthesis, super-resolution, and inpainting by changing only the conditioning encoder.
LDMs had an outsized impact on the field. The 1.45B parameter text-to-image model trained on LAION-400M achieved competitive performance with much larger autoregressive models (DALL-E) at a fraction of the compute. The open release as Stable Diffusion democratized high-quality image generation, catalyzed an ecosystem of fine-tuning techniques (LoRA, DreamBooth, ControlNet), and established latent diffusion as the dominant paradigm for generative modeling. The architecture's influence extends to video generation, 3D synthesis, audio, molecular design, and trajectory planning in robotics and autonomous driving.
Key Contributions
- Two-stage latent diffusion architecture: Separates perceptual compression (autoencoder) from generative learning (diffusion in latent space), dramatically reducing compute while maintaining image quality
- Cross-attention conditioning mechanism: A general-purpose interface that enables flexible conditional generation from text, semantic maps, layouts, and other modalities through domain-specific encoders projected into cross-attention layers
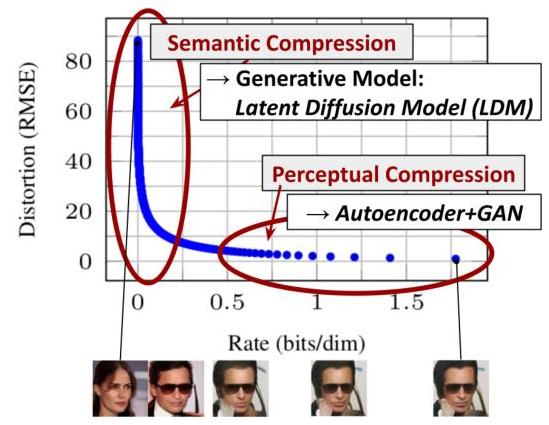
- Systematic analysis of compression-quality tradeoff: Demonstrates that downsampling factors 4-16 provide the optimal balance -- too little compression (1-2x) yields minimal speedup, while excessive compression (32x) degrades quality
- Convolutional generalization beyond training resolution: Models trained at 256x256 can generate coherent megapixel images (1024x1024+) for spatially conditioned tasks, exploiting the convolutional nature of the UNet
- State-of-the-art across multiple tasks: Achieves competitive or superior results on unconditional image generation, text-to-image, inpainting, super-resolution, and semantic synthesis with significantly reduced compute
Architecture / Method
┌──────────────────────────────────────────────────────────────────┐
│ LATENT DIFFUSION MODEL (LDM) │
│ │
│ STAGE 1: Perceptual Compression (trained once, then frozen) │
│ │
│ ┌─────────┐ ┌───────────┐ ┌─────────┐ │
│ │ Image │────►│ Encoder │────►│ Latent z │ │
│ │ x │ │ E(x) │ │ (h×w×c) │ │
│ │(H×W×3) │ └───────────┘ └────┬────┘ │
│ └─────────┘ │ │
│ │ f = H/h (4-16x) │
│ ┌─────────┐ ┌───────────┐ │ │
│ │ Recon │◄────│ Decoder │◄───────────┘ │
│ │ x̂ │ │ D(z) │ │
│ └─────────┘ └───────────┘ │
│ │
│ STAGE 2: Latent Diffusion (operates in compressed space) │
│ │
│ ┌──────────────┐ │
│ │ Conditioning │ e.g. text prompt y │
│ │ Input y │ │
│ └──────┬───────┘ │
│ ▼ │
│ ┌──────────────┐ τ_θ(y) │
│ │ Domain Encoder│───────────────────────┐ │
│ │ (BERT/CLIP) │ K, V projections │ │
│ └──────────────┘ │ │
│ ▼ │
│ z_T (noise) ──► ┌─────────────────────────────┐ ──► z_0 (clean)│
│ │ UNet Denoiser ε_θ │ │
│ Iterative │ ┌───────────────────────┐ │ │
│ Denoising │ │ Cross-Attention Layers │ │ │
│ T steps │ │ Q = UNet features │ │ │
│ │ │ K,V = τ_θ(y) │ │ │
│ │ └───────────────────────┘ │ │
│ └─────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────┐ ┌───────────┐ │
│ │ Latent z_0 │────►│ Decoder D │──► Image │
│ └──────────────┘ └───────────┘ │
└──────────────────────────────────────────────────────────────────┘
Stage 1: Perceptual Compression (Autoencoder)
The autoencoder learns an encoder E and decoder D such that given an image x in R^{H x W x 3}, the encoder produces z = E(x) in R^{h x w x c} where the spatial downsampling factor f = H/h = W/w. Two regularization variants are explored:
- KL-regularization (KL-reg): Imposes a slight KL penalty toward N(0,1) on the learned latent, similar to a standard VAE but with very small weight to avoid excessive regularization
- VQ-regularization (VQ-reg): Uses a vector quantization layer within the decoder, similar to VQGAN, producing discrete latent codes
The autoencoder is trained with a combination of perceptual loss (LPIPS), pixel-level reconstruction loss, and patch-based adversarial loss. The adversarial component uses a patch discriminator to ensure sharp, realistic reconstructions. Crucially, the autoencoder is trained once and then frozen -- the diffusion model is trained separately on the fixed latent space.
Stage 2: Latent Diffusion
The diffusion model is a time-conditional UNet operating on the latent representation z. The forward process adds Gaussian noise to z over T timesteps. The reverse process learns to denoise, parameterized as an epsilon-prediction network:
Training objective (simplified): L_LDM = E_{z, epsilon ~ N(0,1), t} [ || epsilon - epsilon_theta(z_t, t, c) ||_2^2 ]
where z_t is the noised latent at timestep t, and c is the optional conditioning input.
Cross-Attention Conditioning
For conditional generation, a domain-specific encoder tau_theta maps conditioning input y to an intermediate representation tau_theta(y) in R^{M x d_tau}. This representation is projected into the UNet via cross-attention:
Attention(Q, K, V) = softmax(QK^T / sqrt(d)) * V
where Q = W_Q * phi(z_t), K = W_K * tau_theta(y), V = W_V * tau_theta(y). Here phi(z_t) denotes intermediate UNet features. This mechanism is applied at multiple resolutions within the UNet.
For text conditioning, tau_theta is a transformer-based text encoder (e.g., BERT or CLIP). For spatial conditioning (semantic maps, layouts), appropriate CNN or embedding encoders are used.

Results

Unconditional Image Generation
| Method | Dataset | FID ↓ |
|---|---|---|
| LDM-4 | CelebA-HQ 256 | 5.11 |
| LSGM | CelebA-HQ 256 | 7.22 |
| UDM | CelebA-HQ 256 | 2.16 |
| PGGAN | CelebA-HQ 256 | 8.0 |
| VQGAN+T | CelebA-HQ 256 | 10.2 |
| DC-VAE | CelebA-HQ 256 | 15.8 |
Note: DDPM and ADM are not reported on CelebA-HQ in the paper. LDM-4 achieves state-of-the-art FID of 5.11. By contrast, pixel-based diffusion models (ADM) required 150-1000 V100 days of training; LDMs achieve competitive or better results while training on significantly fewer resources (e.g., a single A100 GPU).
Text-to-Image (LAION-400M)
The 1.45B parameter LDM trained on LAION-400M achieves competitive FID with DALL-E (12B parameters, autoregressive) while requiring substantially less compute and enabling much faster inference.
Class-Conditional ImageNet
LDM-4-G achieves FID 3.60 on ImageNet 256x256 class-conditional synthesis, outperforming the previous best ADM-G (FID 4.59) while using half the parameters and requiring 4x fewer training resources.
Inpainting
LDM-based inpainting outperforms prior approaches on both perceptual quality and semantic coherence, achieving state-of-the-art FID of 9.39 on the Places benchmark.
Super-Resolution
LDM-SR on ImageNet achieves competitive results with SR3 and other diffusion-based super-resolution methods while requiring significantly less compute.
Key Ablation: Compression Factor
| Downsampling f | FID ↓ | Sampling Speed | Notes |
|---|---|---|---|
| f=1 (pixel) | Baseline | 1x | No compression benefit |
| f=2 | Slightly better | ~1.5x | Minimal efficiency gain |
| f=4 | Best quality | ~2.7x | Sweet spot |
| f=8 | Competitive | ~5x | Good quality-speed balance |
| f=16 | Slightly degraded | ~10x | Acceptable for many tasks |
| f=32 | Noticeably worse | ~20x | Too much information loss |
Limitations & Open Questions
- Sequential sampling remains slow: Despite latent-space efficiency, generation still requires iterative denoising (though later work like DDIM, DPM-Solver, and consistency models address this)
- Autoencoder reconstruction ceiling: The frozen autoencoder imposes a quality ceiling -- any detail lost in compression cannot be recovered by the diffusion model
- Text-image alignment: The cross-attention conditioning with BERT/CLIP encoders can struggle with compositional prompts (multiple objects, spatial relationships, attribute binding) -- a limitation later addressed by improved text encoders (T5, SDXL)
- Societal risks: The accessibility of high-quality image generation raises concerns about deepfakes, bias amplification, and misuse -- the open release of Stable Diffusion intensified these debates
- Fixed latent space: The two-stage approach means the autoencoder and diffusion model cannot be jointly optimized, potentially leaving quality on the table
Connections
Related papers in the wiki: - Denoising Diffusion Probabilistic Models — DDPM established the diffusion framework that LDM builds upon; LDM's key contribution is moving this process to latent space for efficiency - Variational Lossy Autoencoder — Introduced the information-theoretic perspective on separating global structure from local detail in autoencoders, directly relevant to LDM's perceptual compression stage - Attention Is All You Need — The transformer architecture underlies LDM's cross-attention conditioning mechanism and text encoders - Learning Transferable Visual Models From Natural Language Supervision — CLIP provides the text encoder used in Stable Diffusion's conditioning pipeline - An Image Is Worth 16X16 Words Transformers For Image Recognition At Scale — ViT-based architectures used in later LDM variants for both image encoding and text conditioning - Deep Residual Learning For Image Recognition — ResNet blocks form the backbone of the UNet architecture used in LDM - Diffusiondrive Truncated Diffusion Model For End To End Autonomous Driving — Applies truncated diffusion (inspired by LDM's efficiency insights) to autonomous driving trajectory planning - Cosmos World Foundation Model Platform For Physical Ai — Uses diffusion-based world models that build on the LDM paradigm for physical AI applications - Foundation Models — LDM is a foundational generative model whose paradigm extends to driving, robotics, and world modeling