Segment Anything
Overview
Segment Anything introduces a foundation model for image segmentation -- the Segment Anything Model (SAM) -- together with a new task definition (promptable segmentation) and the largest segmentation dataset ever assembled (SA-1B, containing over 1 billion masks on 11 million images). The paper's core argument is that segmentation needs its own "GPT-3 moment": a single model trained on broad data that generalizes to new tasks and domains without retraining.
The key insight is that by defining segmentation as a prompt-driven task -- where a user provides points, bounding boxes, masks, or text, and the model returns valid segmentation masks -- the authors create an interface flexible enough to power a wide range of downstream applications (interactive editing, object proposals, instance segmentation, etc.) while being trainable with a simple per-prompt loss. This is directly analogous to how GPT-3 used prompting to unify diverse NLP tasks.
SAM achieved remarkable zero-shot transfer, matching or exceeding prior task-specific models on edge detection, object proposal generation, instance segmentation, and text-to-mask prediction without any task-specific fine-tuning. The model processes prompts in real time (~50ms per mask) thanks to its lightweight decoder, while the heavy image encoder runs once per image. With ~19,700 citations by early 2026, SAM became one of the most impactful computer vision papers of the decade and spawned a large ecosystem of derivative work across medical imaging, remote sensing, video segmentation, and 3D scene understanding.
Key Contributions
- Promptable segmentation task: Defined a new task where any segmentation prompt (point, box, mask, or text) produces a valid segmentation mask, enabling a single pretrained model to serve as a component in diverse downstream systems
- Segment Anything Model (SAM): A three-component architecture -- a ViT-based image encoder (MAE-pretrained), a flexible prompt encoder, and a lightweight transformer mask decoder -- that produces high-quality masks in real time
- Data engine for SA-1B: A three-stage annotation pipeline (assisted-manual, semi-automatic, fully automatic) that used SAM-in-the-loop to progressively scale annotation from human-assisted to fully automatic, producing 1.1 billion masks on 11 million images
- SA-1B dataset: The largest segmentation dataset by an order of magnitude, with 400x more masks than any prior dataset, high geographic and subject diversity, and responsible data practices (face blurring, license compliance)
- Zero-shot transfer: Demonstrated strong generalization across 23 diverse segmentation datasets without any fine-tuning, establishing that foundation model scaling works for dense prediction tasks
Architecture / Method
┌──────────────────────────────────────────────────────────┐
│ Segment Anything Model (SAM) │
├──────────────────────────────────────────────────────────┤
│ │
│ ┌──────────────┐ ┌───────────────────┐ │
│ │ Input Image │ │ Prompts │ │
│ │ (1024x1024) │ │ ┌───┐ ┌───┐ ┌──┐│ │
│ └──────┬───────┘ │ │Pts│ │Box│ │Mk││ │
│ │ │ └─┬─┘ └─┬─┘ └┬─┘│ │
│ │ (runs once │ └─────┼─────┘ │ │
│ │ per image) └─────────┼────────┘ │
│ ▼ │ │
│ ┌──────────────────┐ ┌───────────┴─────────┐ │
│ │ Image Encoder │ │ Prompt Encoder │ │
│ │ ViT-H (632M) │ │ Sparse: embeddings │ │
│ │ MAE-pretrained │ │ +positional enc │ │
│ │ │ │ │ Dense: convolutions │ │
│ │ ▼ │ └───────────┬─────────┘ │
│ │ 64x64 feature │ │ │
│ │ map (256-dim) │ │ │
│ └──────┬───────────┘ │ │
│ │ │ │
│ └──────────────┬────────────────────┘ │
│ ▼ │
│ ┌──────────────────────────────┐ │
│ │ Lightweight Mask Decoder │ │
│ │ (2-layer transformer) │ │
│ │ prompt-to-image cross-attn │ │
│ │ image-to-prompt cross-attn │ │
│ │ │ │ │
│ │ ▼ │ │
│ │ 4x upsample + dynamic MLP │ │
│ └──────────┬───────────────────┘ │
│ │ (~50ms on CPU) │
│ ▼ │
│ ┌──────────────────────┐ │
│ │ 3 Masks + IoU Scores│ │
│ │ (multi-granularity) │ │
│ └──────────────────────┘ │
└──────────────────────────────────────────────────────────┘
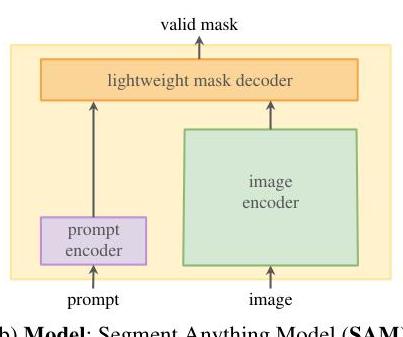
SAM consists of three components designed to separate the expensive image processing from the interactive prompting:
Image Encoder: A Vision Transformer (ViT-H by default: 632M parameters, 16x16 patches) pretrained with Masked Autoencoders (MAE). The encoder processes a 1024x1024 input image and produces a 64x64 feature map with 256-dimensional embeddings. Crucially, this runs only once per image, enabling real-time interactive use.
Prompt Encoder: Handles two types of prompts. Sparse prompts (points, boxes, text) are encoded as learned embeddings plus positional encodings. Points use a learned embedding per foreground/background label plus a positional encoding of the point location. Boxes are represented as two points (top-left, bottom-right) with learned embeddings. Text prompts use CLIP's text encoder. Dense prompts (masks) are encoded via convolutions (two 2x2 stride-2 convolutions plus a 1x1 conv) and summed element-wise with the image embedding.
Mask Decoder: A lightweight transformer decoder (two layers) that uses prompt-to-image and image-to-prompt cross-attention, followed by a dynamic mask prediction head. The decoder takes as input the image embedding, prompt embeddings, and a set of output tokens (one per predicted mask plus an IoU prediction token). After the transformer layers, the image embedding is upsampled 4x via transposed convolutions, and a dynamic linear classifier (MLP-generated per-mask weights) produces the final masks at 256x256 resolution. The entire decoder runs in ~50ms on a CPU.
Ambiguity-aware output: When a prompt is ambiguous (e.g., a single point could refer to a part, subpart, or whole object), SAM predicts 3 masks simultaneously at different granularity levels, each with a predicted IoU score. The highest-IoU mask is selected by default, but the multi-mask output enables downstream systems to choose the appropriate granularity.
Training: SAM is trained with a combination of focal loss and dice loss on per-mask predictions. The model is trained to predict a valid mask for any prompt, where "valid" means it corresponds to at least one reasonable object or region. Training uses the SA-1B data with a mixture of point, box, and mask prompts simulated from ground truth.
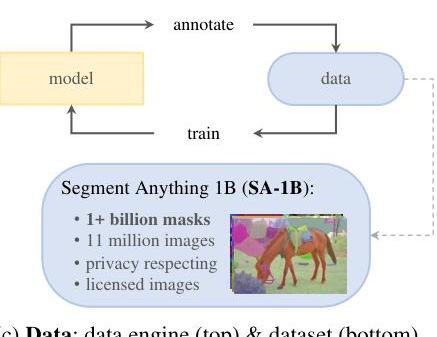
Data engine: The annotation pipeline that created SA-1B operated in three stages: 1. Assisted-manual (Stage 1): Professional annotators labeled masks using SAM with a browser-based tool. SAM provided automatic suggestions that annotators corrected. This produced 4.3M masks on 120K images. 2. Semi-automatic (Stage 2): SAM automatically detected confident masks, and annotators labeled additional unannotated objects, increasing mask diversity. This produced 5.9M additional masks on 180K images. 3. Fully automatic (Stage 3): SAM generated masks automatically using a 32x32 grid of point prompts per image, with NMS and filtering for quality. This produced the bulk of the dataset: ~1.1B masks on 11M images.
Results
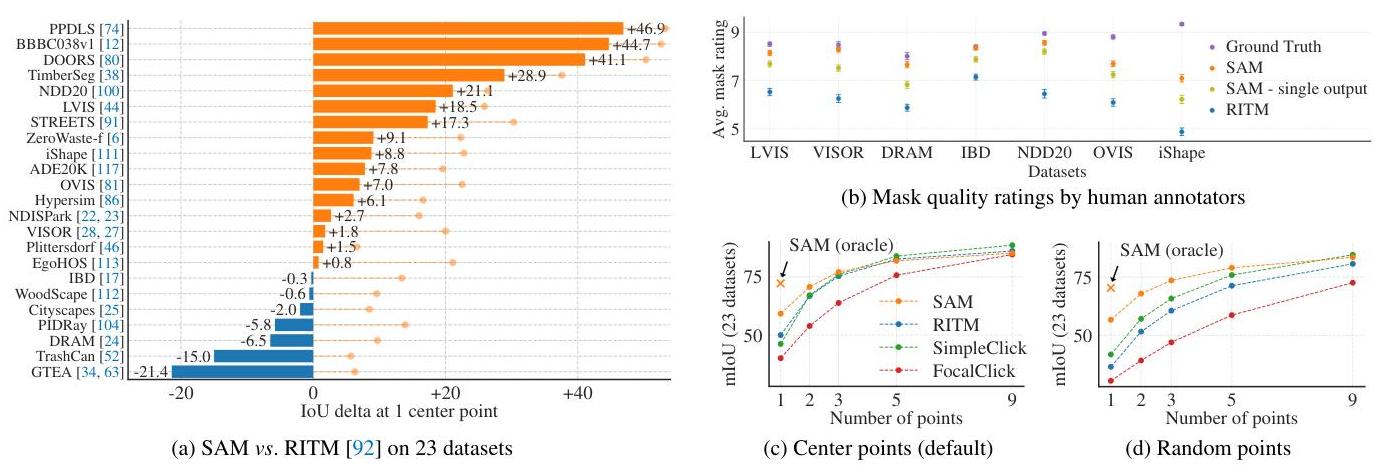
Zero-shot single-point segmentation: Human evaluators rated SAM's masks as higher quality than those from the strongest baseline (RITM) in 7 out of 9 experiments when using a single foreground point prompt. SAM's masks improved further with additional prompts.
| Task | Metric | SAM (zero-shot) | Best prior (task-specific) |
|---|---|---|---|
| Edge detection (BSDS500) | ODS | 76.8 | 78.8 (HED, trained) |
| Object proposals (LVIS) | AR@1000 | 59.3 | 63.0 (ViTDet-H) |
| Instance segmentation (LVIS) | AP | comparable | ViTDet (trained on LVIS) |
| Single-point valid mask | Human preference | 7/9 wins | RITM |
Key findings: - SAM produces highly coherent object boundaries, even for objects not represented in its training data - Performance scales with encoder size: ViT-H > ViT-L > ViT-B across all evaluations - Multi-point prompting significantly improves mask quality (as expected), with diminishing returns after ~5-9 points - Box prompts generally outperform single-point prompts and approach oracle-prompted performance - On LVIS (1203 categories), SAM zero-shot AR@1000 of 59.3 does not overall exceed ViTDet-H (63.0), though SAM outperforms on medium/large objects and rare/common categories; ViTDet-H's advantage on small and frequent objects reflects LVIS-specific training biases - Automatic mask generation at scale (the 32x32 grid strategy) produces high-quality masks suitable for downstream model training
Limitations & Open Questions
- No semantic understanding: SAM segments objects but does not classify them -- it produces masks without labels. Combining SAM with classification models (as in Grounded-SAM) is an active area
- Fine structures: Performance degrades on thin structures (bicycle spokes, fence wires) and highly occluded objects
- Real-time full pipeline: While the decoder is fast, the ViT-H image encoder takes ~0.15s per image on an A100, making truly real-time video segmentation challenging without model distillation (addressed by SAM 2 and EfficientSAM)
- Text prompts: The text-to-mask capability was trained but not extensively evaluated; it was noted as a proof of concept rather than a mature feature
- 3D and video: SAM operates on single images; extending to temporally consistent video segmentation and 3D scene segmentation are natural next steps (addressed by SAM 2 in 2024)
- Domain gaps: While zero-shot transfer is strong, performance on specialized domains (medical imaging, satellite imagery) benefits from fine-tuning, raising questions about the limits of foundation model generalization
Connections
Related papers in the wiki: - An Image Is Worth 16X16 Words Transformers For Image Recognition At Scale -- ViT, the backbone architecture for SAM's image encoder - Learning Transferable Visual Models From Natural Language Supervision -- CLIP, whose text encoder SAM uses for text prompts; both are vision foundation models trained on massive data - Deep Residual Learning For Image Recognition -- ResNet, the prior dominant paradigm for vision backbones that ViT/SAM superseded - Imagenet Classification With Deep Convolutional Neural Networks -- AlexNet, the beginning of the deep learning vision era that SAM's foundation model approach extends - Language Models Are Few Shot Learners -- GPT-3, the NLP foundation model whose prompting paradigm directly inspired SAM's promptable segmentation task - Attention Is All You Need -- Transformer architecture underlying both SAM's encoder and decoder - Foundation Models -- SAM as a seminal vision foundation model demonstrating that the foundation model paradigm extends to dense prediction - Perception -- SAM's segmentation capabilities are relevant to perception pipelines, particularly for generating training data and interactive annotation