SpatialVLA: Exploring Spatial Representations for VLA Models
Overview
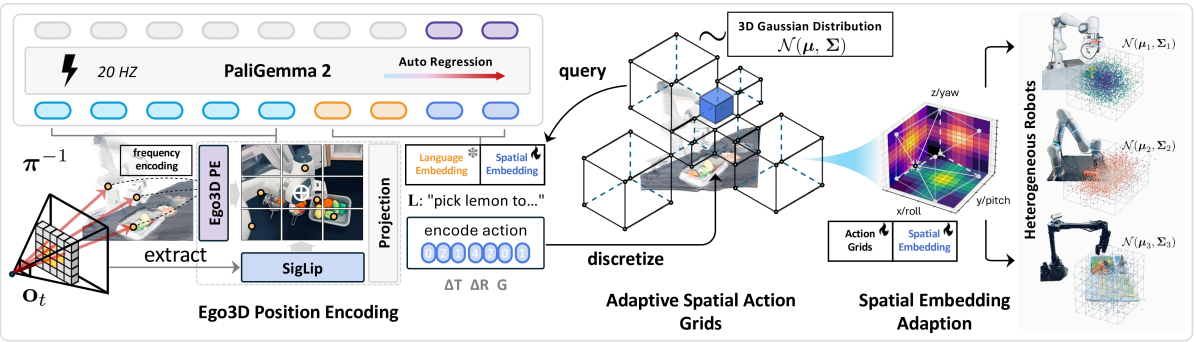
SpatialVLA addresses a fundamental limitation of existing VLA models: they operate on 2D visual inputs despite robot manipulation requiring understanding of 3D spatial relationships. Developed by Shanghai AI Laboratory in collaboration with top Chinese universities, SpatialVLA builds on PaliGemma 2 (3.5B parameters) and introduces two core innovations -- Ego3D Position Encoding and Adaptive Action Grids -- to inject spatial awareness into the VLA framework. The model is pre-trained on 1.1 million real-world robot demonstrations from Open X-Embodiment and RH20T, achieving state-of-the-art zero-shot performance on SimplerEnv (outperforming RT-2-X at 55B parameters) and 73% spatial accuracy on targeted Franka spatial reasoning tasks.
The key insight is that robot manipulation is inherently a 3D task: grasping requires understanding depth, relative positions, and object orientations that are ambiguous in 2D images. By converting monocular images into spatially-aware representations using estimated depth and 3D position encoding, SpatialVLA bridges the gap between 2D VLM pre-training and 3D robotic control.
Key Contributions
- Ego3D Position Encoding: Transforms 2D image observations into spatially-aware representations by estimating depth, computing 3D positions in the robot's ego-centric frame, and applying sinusoidal encoding -- all without requiring explicit 3D sensors
- Adaptive Action Grids: Replaces uniform action discretization with Gaussian-distribution-based equal-probability intervals, concentrating resolution where actions are most likely and reducing quantization error
- 1.1M real episode pre-training: Trained on one of the largest real-world robot datasets, spanning multiple embodiments and environments
- Spatial Embedding Adaptation: A lightweight post-training scheme that adapts pre-trained spatial embeddings to new robot setups without full retraining
Architecture / Method
┌──────────────────────────────────────────────────────────┐
│ SpatialVLA │
│ │
│ ┌──────────┐ ┌───────────────────┐ │
│ │ RGB Image│────►│ Monocular Depth │ │
│ └─────┬────┘ │ Estimator │ │
│ │ └────────┬──────────┘ │
│ │ │ per-pixel depth │
│ │ ▼ │
│ │ ┌───────────────────┐ │
│ │ │ Back-project to │ │
│ │ │ 3D (ego-centric) │ │
│ │ └────────┬──────────┘ │
│ │ │ 3D coordinates │
│ │ ▼ │
│ │ ┌───────────────────┐ │
│ │ │ Sinusoidal 3D │ │
│ │ │ Position Encoding │ │
│ │ └────────┬──────────┘ │
│ │ │ Ego3D PE │
│ ▼ ▼ │
│ ┌──────────────────────────────┐ │
│ │ Vision Encoder │ │
│ │ (patch embeds + Ego3D PE) │ │
│ └──────────────┬───────────────┘ │
│ │ │
│ ┌──────────┐ │ │
│ │ Task Text│───┤ │
│ └──────────┘ ▼ │
│ ┌──────────────┐ │
│ │ VLM Backbone │ │
│ └──────┬───────┘ │
│ ▼ │
│ ┌──────────────────────────────┐ │
│ │ Adaptive Action Grids │ │
│ │ (Gaussian equal-probability │ │
│ │ bins per action dimension) │──► Robot Actions │
│ └──────────────────────────────┘ │
└──────────────────────────────────────────────────────────┘
SpatialVLA is built on PaliGemma 2 as its vision-language backbone (using the SigLIP visual encoder), augmented with two key spatial modules:
Ego3D Position Encoding works in three steps: (1) ZoeDepth estimates per-pixel depth from the RGB image, (2) depth values are back-projected into 3D coordinates using camera intrinsics in the robot's ego-centric reference frame, (3) sinusoidal encodings of the 3D coordinates are passed through a learnable MLP and added to the SigLIP image patch embeddings before they enter the VLM backbone. This gives the model explicit spatial information without requiring depth cameras or point clouds at inference time.
Adaptive Action Grids discretize 7-DOF robot actions by fitting parameterized Gaussian distributions to each action dimension in the training data and placing bins at equal-probability intervals (Grid_i = Φ⁻¹(i/M)). Translation components are first converted to polar coordinates (φ, θ, r) before fitting. This concentrates bins where actions are most likely and reduces the total action token count from 7 to 3 per timestep, enabling ~20Hz inference.
Spatial Embedding Adaptation enables transfer to new robots: new Gaussian distributions are fitted to the target robot's action data, new action grids are created, and the new action token embeddings are initialized via trilinear interpolation from the pre-trained tokens. Only the spatial action embeddings and Ego3D MLP are updated, making adaptation fast and data-efficient even with limited demonstrations.
Training: Pre-training uses standard autoregressive next-token prediction with text token embeddings frozen to preserve language knowledge. Spatial action embeddings and Ego3D MLP parameters are randomly initialized and trained from scratch on 1.1M demonstrations.
Results
| Benchmark | Metric | SpatialVLA | Comparison | Notes |
|---|---|---|---|---|
| SimplerEnv Google Robot (zero-shot) | Visual Matching | 71.9% | RT-2-X (55B params) | Uses 3.5B params |
| SimplerEnv Google Robot (zero-shot) | Variant Aggregation | 68.8% | RT-2-X | Outperforms larger model |
| WidowX (sim, zero-shot) | Success rate | 34.4% | 13.5% (RoboVLM) | +20.9% |
| LIBERO (adaptation) | Avg. success rate | 78.1% | - | 88.2% on LIBERO-Spatial |
| Franka multi-task (adaptation) | Multi-task accuracy | 57% | - | Surpasses generalist policies |
| Franka spatial prompts | Spatial accuracy | 73% | <50% (competitors) | Height-change manipulation |
- Zero-shot SimplerEnv results show SpatialVLA (3.5B params) outperforms RT-2-X (55B params), demonstrating strong spatial generalization
- WidowX zero-shot success rate of 34.4% is more than double RoboVLM (13.5%)
- Ablation: removing Ego3D encoding drops variant aggregation from 81.6% to 68.9%; adaptive vs. linear discretization gives +36.5%/+42.1% on variant aggregation/visual matching
- Spatial Embedding Adaptation provides +4.6% gain on LIBERO-Spatial with limited fine-tuning data; LoRA outperforms full-parameter tuning on small datasets
- 73% spatial accuracy on Franka spatial prompts; competitors fall below 50% on height-change tasks
Limitations
- Relies on a learned monocular depth estimator, which introduces errors in depth ambiguous scenes (reflective surfaces, transparent objects, thin structures)
- The Ego3D encoding assumes known camera intrinsics; deployment to new camera setups requires calibration
- Despite 1.1M episodes, the dataset is dominated by tabletop manipulation; spatial reasoning for navigation or aerial manipulation is not evaluated
- The Gaussian assumption for action distribution in adaptive grids may not hold for highly multimodal action spaces
Connections
- Openvla An Open Source Vision Language Action Model -- SpatialVLA builds on the VLA paradigm established by OpenVLA, adding 3D spatial awareness
- Lift Splat Shoot Encoding Images From Arbitrary Camera Rigs By Implicitly Unprojecting To 3D -- Lift-Splat-Shoot pioneered image-to-3D lifting for driving; SpatialVLA applies similar intuition to manipulation
- Vision Language Action -- demonstrates that spatial representation is a critical design axis for VLAs
- Perception -- monocular 3D perception for manipulation
- Robotics -- spatial reasoning for dexterous manipulation