OpenVLA: An Open-Source Vision-Language-Action Model
Overview
OpenVLA is a 7-billion parameter open-source vision-language-action model that demonstrates generalist robotic manipulation by fine-tuning a pretrained vision-language model (Prismatic VLM, built on SigLIP + DinoV2 vision encoders with a Llama 2 7B language backbone) on the Open X-Embodiment dataset -- the largest open robot manipulation dataset containing over 970K trajectories across 22 robot embodiments. The model takes a single camera image and a natural language task instruction as input and directly outputs discretized robot actions (7-DoF: 3 translation, 3 rotation, 1 gripper).
The key contribution is demonstrating that a single generalist policy, trained on diverse robot data and released with full weights and code, can match or exceed the performance of specialist policies (like RT-2-X) on multiple manipulation benchmarks while being practically fine-tunable on new tasks with modest compute (a single GPU in hours). This bridges the gap between closed, proprietary VLA systems (RT-2, Octo) and the broader robotics research community that needs accessible, reproducible baselines.
OpenVLA addresses a critical bottleneck in robot learning: prior VLA models were either closed-source (RT-2), required massive compute for training (PaLM-E), or were not pretrained on sufficient data to generalize. By combining a strong VLM backbone with the scale of Open X-Embodiment data and releasing everything openly, OpenVLA provides the robotics community with a practical foundation model that can be adapted to new robots, tasks, and environments through parameter-efficient fine-tuning.
Key Contributions
- Open-source generalist VLA: First fully open (weights, code, data pipeline) 7B-parameter VLA model that matches RT-2-X performance on generalist manipulation benchmarks
- Efficient fine-tuning recipe: Demonstrates that LoRA fine-tuning on a single A100 GPU for 10-15 hours adapts the generalist policy to new tasks, achieving performance competitive with or exceeding training from scratch
- Action tokenization via discretization: Robot actions are discretized into 256 bins per dimension and predicted as token sequences through the LLM's vocabulary, avoiding the need for separate action heads
- Dual vision encoder: Uses both SigLIP (semantic) and DinoV2 (spatial/geometric) encoders to provide complementary visual features, which improves manipulation performance over single-encoder baselines
- Systematic evaluation across embodiments: Tests on WidowX, Franka, and Google Robot platforms with real-world evaluations, not just simulation
Architecture / Method
OpenVLA Architecture
────────────────────
Camera Image Language Instruction
│ │
▼ ▼
┌─────────────┐ ┌─────────────┐ ┌─────────────┐
│ SigLIP │ │ DinoV2-L │ │ Tokenizer │
│ SO400M │ │ (spatial/ │ │ (text) │
│ (semantic) │ │ geometric)│ │ │
└──────┬──────┘ └──────┬──────┘ └──────┬──────┘
│ │ │
└───────┬────────┘ │
│ concat │
▼ │
┌──────────────┐ │
│ 2-Layer MLP │ │
│ Projector │ │
└──────┬───────┘ │
│ │
▼ ▼
┌─────────────────────────────────────┐
│ Llama 2 7B LLM │
│ [visual tokens] + [text tokens] │
│ │
│ Next-token prediction ──► │
└─────────────────┬───────────────────┘
│
▼
7 Action Tokens
(each: 256 bins discretized)
┌───┬───┬───┬───┬───┬───┬───┐
│ dx│ dy│ dz│ r │ p │ y │ g │
└───┴───┴───┴───┴───┴───┴───┘
translation rotation grip
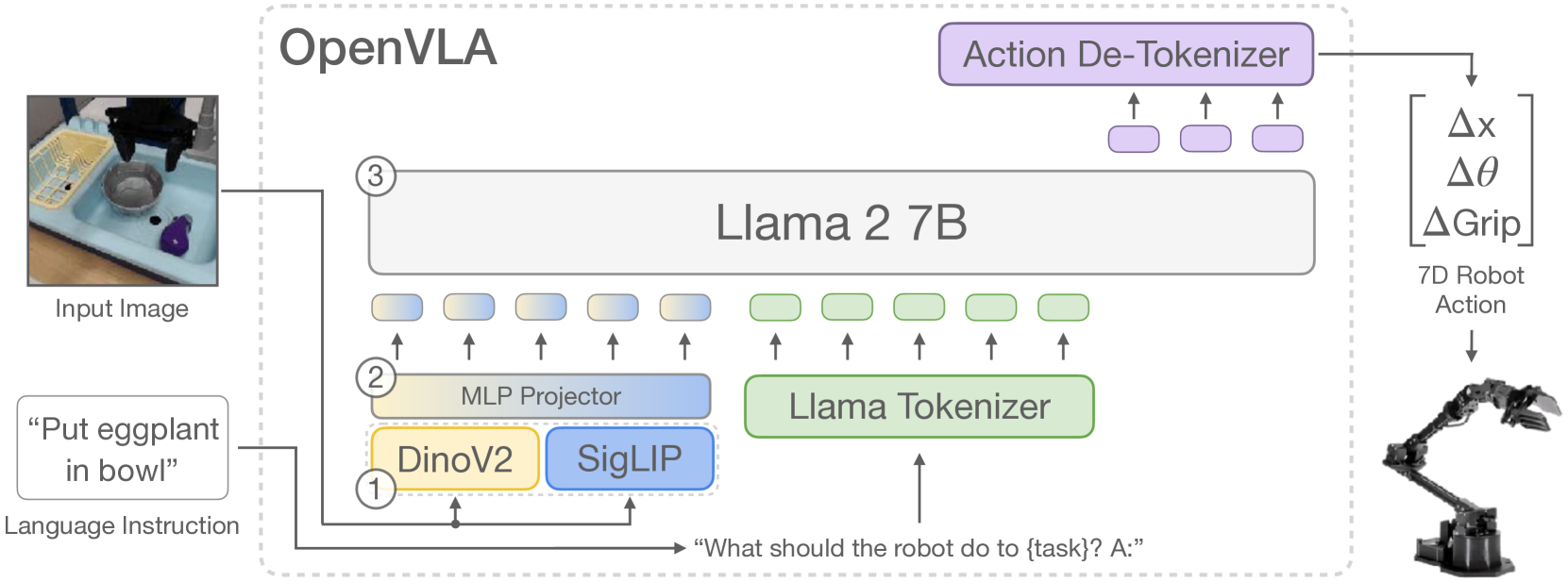
OpenVLA builds on the Prismatic-7B VLM architecture. The visual pipeline employs a dual-encoder fusion approach with a 600M-parameter visual encoder: SigLIP-SO400M (for higher-level semantic understanding) and DinoV2-L (for fine-grained spatial information crucial for precise manipulation). Input images are processed through both encoders simultaneously, with feature vectors concatenated channel-wise to create rich visual representations. This feeds into a compact 2-layer MLP projector that maps visual features into the language model's embedding space.
The language backbone is Llama 2 7B, with the entire visual encoder fine-tuned during training (contrary to common VLM practices of freezing vision components -- this proved essential for spatial precision in robotic control). The input to the model is: [visual tokens] + [instruction text tokens]. The output is a sequence of 7 action tokens, each representing a discretized dimension of the robot action (delta x, y, z, roll, pitch, yaw, gripper open/close). Each continuous action dimension is uniformly discretized into 256 bins spanning the 1st to 99th percentile of action values (a refinement over min-max bounds to handle outliers). These bins are mapped by overwriting the 256 least-used tokens in Llama's vocabulary, enabling the LLM's next-token prediction objective to be applied directly to action generation.
Training uses the Open X-Embodiment dataset (970K real-world demonstrations), filtered to manipulation datasets with at least one third-person camera view, restricted to single-arm end-effector control, with balanced mixture weights across embodiments. Critically, "all-zero" (no-op) actions are removed to prevent policy freezing. The model trains for 27 epochs (significantly more than typical VLM training) on 64 A100 GPUs over 14 days (~21,500 A100-hours), using a fixed learning rate of 2x10^{-5}. Key insight: 224x224 pixel resolution provided equivalent performance to 384x384 while being 3x faster to train.
For fine-tuning, LoRA fine-tuning matches full fine-tuning performance (68.2% vs. 69.7% success rate) while training only 1.4% of model parameters -- an 8x reduction in compute (1 vs 8 A100 GPUs), with training time reduced to 10-15 hours on a single GPU.
Results
| Configuration | Success Rate | Parameters | Memory |
|---|---|---|---|
| OpenVLA (full fine-tune) | 69.7% | 7B (100%) | 16.8 GB |
| OpenVLA (LoRA) | 68.2% | 7B (1.4%) | 59.7 GB |
| OpenVLA (4-bit quant) | 71.9% | 7B | 7.0 GB |
| RT-2-X | ~53% | 55B | - |
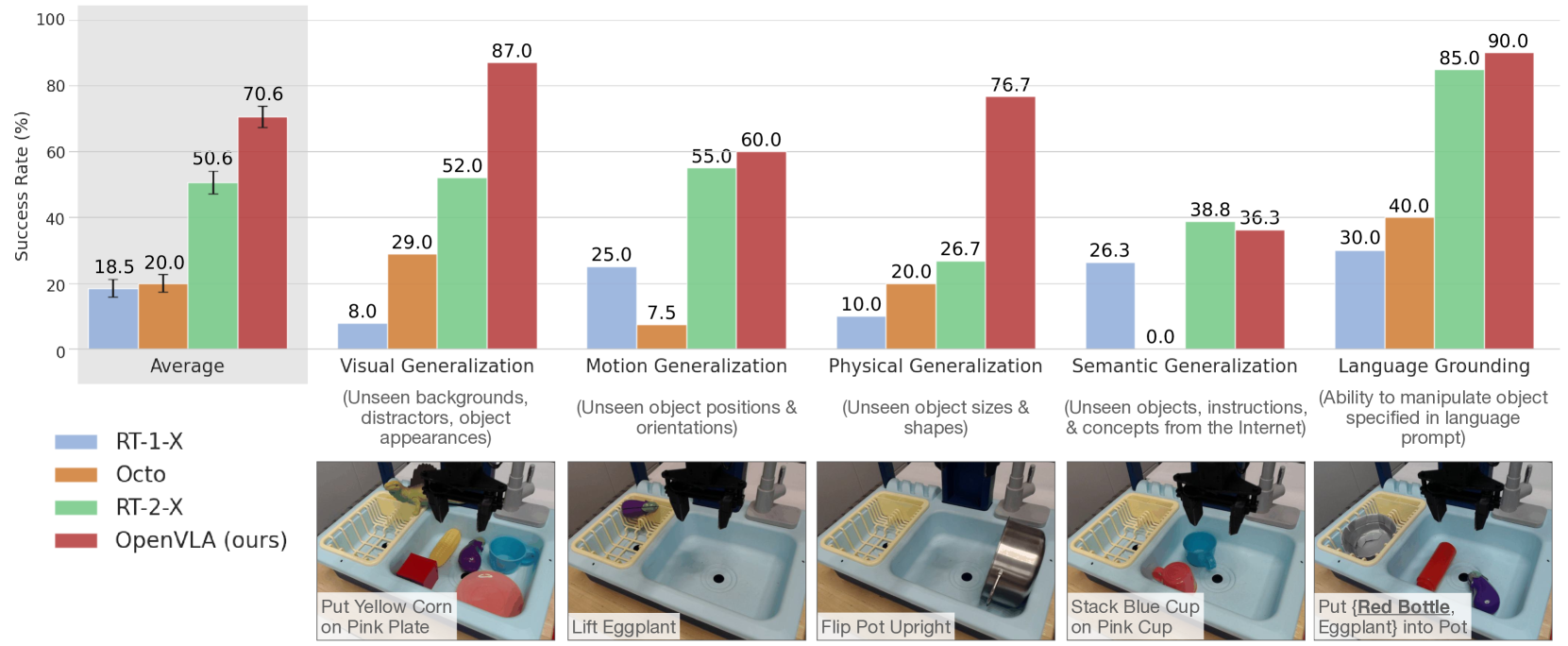
- Generalist policy performance: OpenVLA achieved a 16.5% absolute improvement in success rate over RT-2-X (55B parameters) across 29 tasks spanning two robot embodiments (WidowX and Google Robot), establishing a new state-of-the-art for generalist robot manipulation with 7x fewer parameters
- On the WidowX BridgeV2 evaluation suite, OpenVLA achieves 70.6% average success rate across 17 tasks, significantly outperforming RT-2-X (50.6%) despite being 7B vs. 55B parameters
- Fine-tuning on a new WidowX task (e.g., "put the spoon on the towel") reaches 90%+ success after 10-15 hours of LoRA training on a single GPU
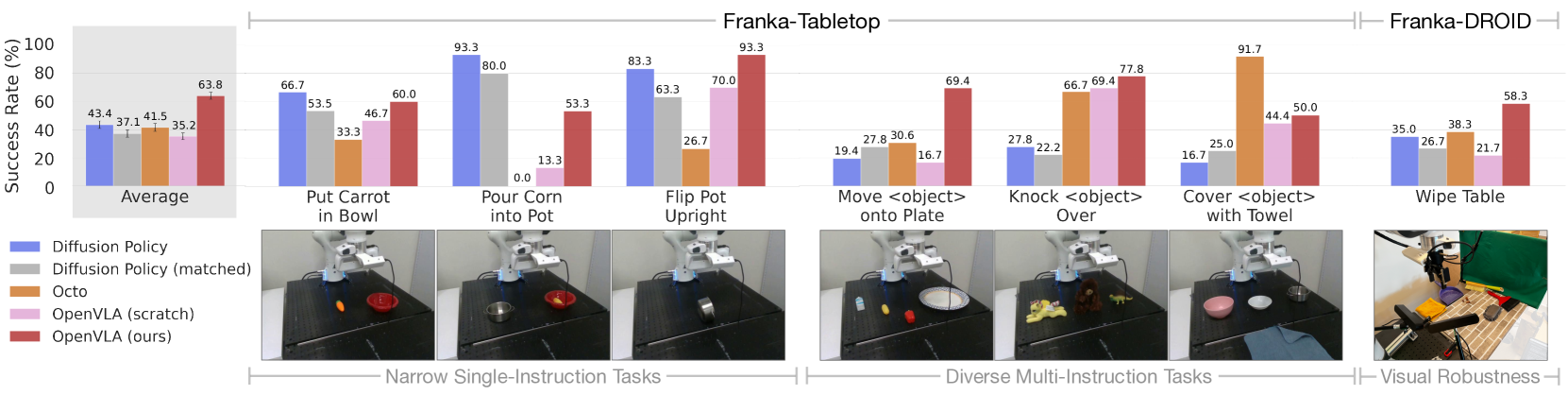
- Adaptation to new robots: 20.4% improvement over Diffusion Policy on diverse multi-instruction tasks on Franka platforms (10-150 demonstrations). Consistent robustness across all tested tasks (the only method achieving >=50% success rate universally). Superior on tasks requiring language grounding and distractor handling
- The dual vision encoder (SigLIP + DinoV2) outperforms single-encoder variants by 8-12% on spatial reasoning tasks, validating the complementary feature design
- Visual/motion/physical generalization: Strong performance on unseen backgrounds, distractors, novel object positions/orientations, and different object sizes/shapes, though success rates drop ~15-20% compared to in-distribution evaluation
- Quantization for deployment: 4-bit quantization maintains performance (71.9% vs. 71.3% at bfloat16) while reducing memory footprint by >50% (7.0 GB vs. 16.8 GB), enabling deployment on consumer GPUs like RTX 4090 at ~6Hz inference
Limitations & Open Questions
- The 7-DoF action space with single-step prediction limits the model to quasi-static manipulation; dynamic tasks (throwing, catching, contact-rich assembly) require multi-step action chunking or diffusion-based decoders not present in OpenVLA
- Action discretization into 256 bins introduces quantization error (~0.4mm at typical workspace scales), which may be insufficient for precision tasks; continuous action heads could address this
- The model operates on single images without temporal context, meaning it cannot reason about velocities, dynamics, or multi-step progress -- a significant gap compared to methods with history conditioning
Connections
- Vision Language Action -- OpenVLA is a canonical VLA instantiation
- Robotics -- primary application domain
- Foundation Models -- demonstrates VLM-to-VLA transfer learning
- Palm E An Embodied Multimodal Language Model -- PaLM-E pioneered embodied multimodal LMs; OpenVLA provides an open alternative
- Attention Is All You Need -- transformer backbone architecture