Overview
CrossFormer addresses a fundamental limitation in robot learning: the requirement for specialized policies for each robotic platform. Traditional approaches train separate models per embodiment, which wastes data that could be shared across platforms and requires repeating the full training pipeline for every new robot. CrossFormer proposes a single transformer-based policy trained on 900,000 trajectories across 20 distinct robot embodiments — spanning single-arm manipulation, bimanual manipulation, wheeled navigation, quadruped locomotion, and even quadcopter aviation — making it the largest and most diverse cross-embodiment policy to date.
The core architectural insight is to frame cross-embodied imitation learning as a sequence-to-sequence problem using a decoder-only causal transformer, with three key innovations: (1) flexible observation tokenization that processes heterogeneous sensor inputs without manual alignment, (2) action readout tokens that allow each embodiment to maintain its own optimal action representation, and (3) embodiment-specific action heads that decode these readout tokens into the native action space of each robot. This avoids the common pitfall of forcing all robots into a single shared action representation, which can degrade performance.
CrossFormer achieves a 73% average success rate across evaluation tasks, compared to 67% for single-robot dataset baselines — demonstrating no negative transfer from the diverse training mixture. It significantly outperforms prior cross-embodiment methods (51% for the best prior approach) and, remarkably, demonstrates zero-shot generalization to a Tello quadcopter, an embodiment entirely absent from training data.
Key Contributions
- A flexible transformer architecture that handles 20+ robot embodiments with heterogeneous observation and action spaces through a single set of shared weights
- Action readout tokens with embodiment-specific heads, eliminating the need to manually align action spaces across robots
- Training on 900K trajectories from diverse sources (Open X-Embodiment, DROID, ALOHA, GNM navigation, Go1 quadruped) — the largest cross-embodiment dataset used for a single policy
- Demonstration that cross-embodiment training yields no negative transfer: the unified policy matches or exceeds single-robot baselines
- Zero-shot generalization to a novel embodiment (Tello quadcopter) not present in training data
Architecture / Method
┌──────────────────────────────────────────────────────────────┐
│ CrossFormer (130M params) │
│ Decoder-Only Causal Transformer (12 layers) │
├──────────────────────────────────────────────────────────────┤
│ │
│ ┌─── Observation Tokenization ────────────────────────────┐ │
│ │ │ │
│ │ ┌───────────┐ ┌───────────┐ ┌───────────┐ ┌──────────┐│ │
│ │ │ 3rd-Person│ │ Wrist Cam │ │ Wrist Cam │ │ Proprio- ││ │
│ │ │ Camera │ │ (shared │ │ (shared │ │ ception ││ │
│ │ │ ResNet-26 │ │ ResNet-26)│ │ ResNet-26)│ │ (linear) ││ │
│ │ └─────┬─────┘ └─────┬─────┘ └─────┬─────┘ └─────┬────┘│ │
│ │ └──────────────┴──────────────┴─────────────┘ │ │
│ │ Concatenated Tokens │ │
│ └─────────────────────────┬───────────────────────────────┘ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Shared Causal Transformer Backbone │ │
│ │ (cross-embodiment knowledge transfer) │ │
│ │ [obs tokens] + [action readout tokens] │ │
│ └─────────────────────────┬───────────────────────────────┘ │
│ │ │
│ ┌─────────────────┼─────────────────┐ │
│ ▼ ▼ ▼ │
│ ┌──────────────┐ ┌──────────────┐ ┌────────────────┐ │
│ │ Single-Arm │ │ Navigation │ │ Bimanual / │ │
│ │ Cartesian 7D │ │ Waypoint 2D │ │ Quadruped Head │ │
│ │ (WidowX, │ │ (LoCoBot, │ │ (ALOHA 14D, │ │
│ │ Franka) │ │ Jackal) │ │ Go1 12D) │ │
│ └──────────────┘ └──────────────┘ └────────────────┘ │
│ Embodiment-Specific Action Heads │
└──────────────────────────────────────────────────────────────┘
│ │ │
▼ ▼ ▼
20 Robot Embodiments (900K trajectories)
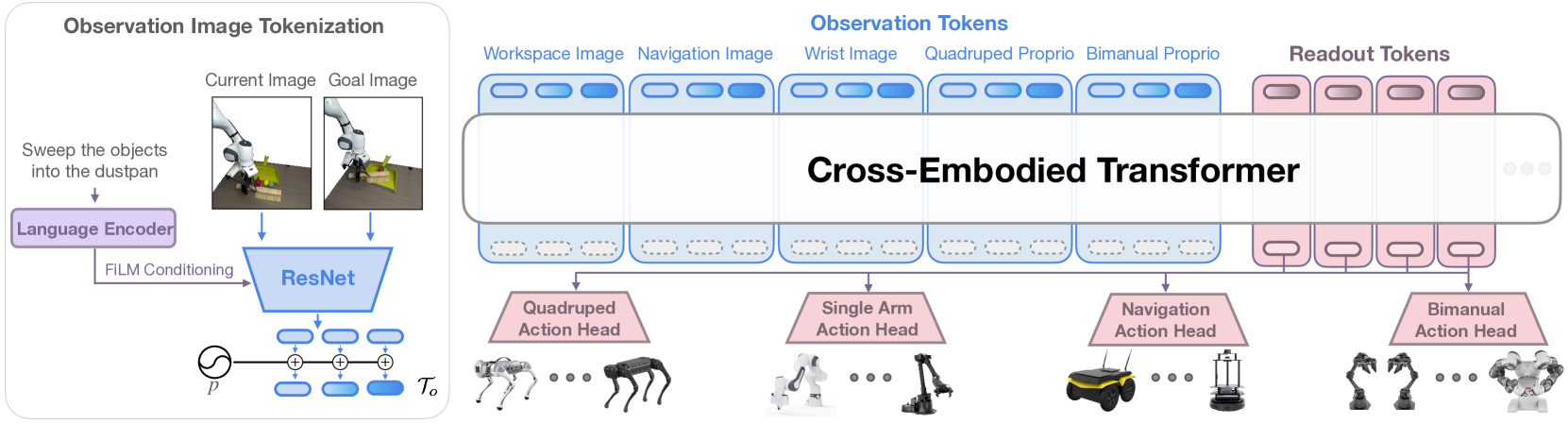
CrossFormer uses a decoder-only causal transformer with 12 layers, 8 attention heads, 2048 MLP dimension, and 512 token embedding size (130M total parameters). The architecture has three main components:
Observation Tokenization
- Images are processed through shared ResNet-26 encoders. Weights are shared by camera type (e.g., all wrist cameras share one encoder, all third-person cameras share another), allowing the model to learn camera-type-specific features while amortizing across embodiments.
- Proprioceptive data (joint angles, end-effector poses, etc.) is linearly projected to the 512-dim embedding space. Each embodiment's proprioceptive format is handled by its own projection layer.
- Observation tokens from all modalities are concatenated into a single sequence for the transformer.
Transformer Backbone
The causal transformer processes the concatenated observation tokens autoregressively. This shared backbone is where cross-embodiment knowledge transfer occurs — the model learns general manipulation, navigation, and locomotion primitives that are useful across platforms.
Action Readout Tokens and Embodiment-Specific Heads
Special action readout tokens are appended to the observation sequence. The transformer's outputs at these positions are fed to one of four embodiment-specific action heads:
| Action Head | Dimensionality | Embodiments |
|---|---|---|
| Single Arm Cartesian | 7D (xyz + rotation + gripper) | WidowX, Franka (single-arm) |
| Navigation Waypoints | 2D (x, y) | LoCoBot, Jackal, other wheeled platforms |
| Bimanual Joint Positions | 14D (7 per arm) | ALOHA bimanual setup |
| Quadruped Joint Positions | 12D (3 per leg) | Unitree Go1 |
This design allows each robot to maintain its native action representation without compromising other embodiments.

Training Details
- Data: 900,000 trajectories from Open X-Embodiment data, DROID (Franka manipulation), ALOHA (bimanual), GNM (navigation), and Go1 (quadruped locomotion)
- Compute: Trained for 300K steps on TPU V5e-256
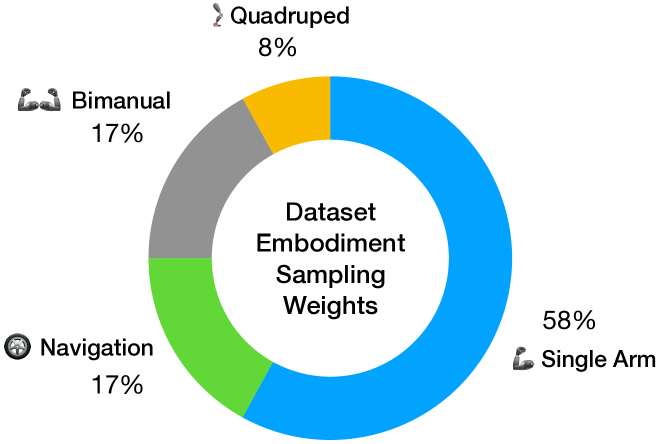
- Sampling: Hand-picked per-dataset sampling weights to balance the training mixture across embodiments
Results
CrossFormer demonstrates strong performance across all four control domains:
| Method | Avg Success Rate | WidowX Manip. | Navigation | Notes |
|---|---|---|---|---|
| CrossFormer | 73% | 33-75% | Superior | Single policy, 20 embodiments |
| Single-robot baselines | 67% | Comparable | Comparable | One model per robot |
| Yang et al. (prior cross-embodiment) | 51% | 0% | Inferior | Prior SOTA for cross-embodiment |
Key findings:
- No negative transfer: Training on diverse embodiments does not hurt performance on any individual robot, and in most cases slightly improves it
- Cross-embodiment outperforms specialist baselines: The 73% vs 67% gap suggests positive transfer from the data mixture
- Prior methods fail on diverse settings: The best prior cross-embodiment approach (Yang et al.) achieves 0% on WidowX manipulation tasks, highlighting the difficulty of the problem
- Zero-shot aviation: CrossFormer successfully controls a Tello quadcopter — an embodiment type (quadcopter) entirely absent from training data — demonstrating that the learned representations generalize beyond the training distribution

Limitations & Open Questions
- Limited positive transfer across embodiments: While there is no negative transfer, the diverse training mixture does not dramatically boost individual robot performance — the gains are modest (73% vs 67%)
- Hand-picked sampling weights: The per-dataset sampling ratios require manual tuning, which does not scale elegantly as more embodiments are added
- Transformer inference speed: The 130M-parameter transformer may be too slow for very high-frequency control loops (e.g., 1kHz force control), though it works for the tested embodiments
- Data diversity could expand: The current dataset consists entirely of expert demonstrations; incorporating sub-optimal data, play data, or action-free video could improve generalization further
- Scaling laws unclear: Whether CrossFormer follows predictable scaling laws with respect to data, compute, and embodiment diversity (as later shown by Embodiment Scaling Laws for locomotion) remains to be explored
Connections
Related papers in the wiki:
- Hpt Scaling Proprioceptive Visual Learning With Heterogeneous Pre Trained Transformers — HPT takes a similar stem-trunk-head approach to cross-embodiment learning but at larger scale (1B+ params) and demonstrates the first robotics scaling laws; CrossFormer's action readout tokens are analogous to HPT's embodiment-specific heads
- Uniact Universal Actions For Enhanced Embodied Foundation Models — UniAct takes the opposite design choice: instead of embodiment-specific heads, it learns a universal VQ action codebook shared across 28 embodiments; outperforms larger models at only 0.5B params
- Openvla An Open Source Vision Language Action Model — OpenVLA is the open-source 7B VLA that CrossFormer can be compared against; CrossFormer is much smaller (130M) but handles more embodiment types
- Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control — RT-2 established the VLA paradigm CrossFormer builds on, but focused on a single embodiment; CrossFormer extends to 20
- Robocat A Self Improving Generalist Agent For Robotic Manipulation — RoboCat also trains across multiple embodiments (3 robots, 253 tasks) with self-improvement, but CrossFormer handles far more diverse embodiment types including navigation and locomotion
- Embodiment Scaling Laws In Robot Locomotion — Provides the theoretical foundation for why CrossFormer's cross-embodiment approach works, showing power-law scaling with embodiment diversity
- Dita Scaling Diffusion Transformer For Generalist Vla Policy — Dita uses diffusion transformers for cross-embodiment VLA with in-context conditioning, a different generative approach to the same problem
- Pi0 A Vision Language Action Flow Model For General Robot Control — pi0 uses flow matching instead of autoregressive prediction for multi-embodiment control (7 platforms, 68 tasks)
- Robotics — Broader context on the VLA revolution and cross-embodiment learning
- Vision Language Action — Design axes for VLA systems