UniAct: Universal Actions for Enhanced Embodied Foundation Models
Overview
UniAct addresses a critical challenge in embodied AI: robot action data suffers from severe heterogeneity across platforms, control interfaces, and physical embodiments, making it difficult to train cross-embodiment foundation models. Unlike text and images that aggregate easily, action spaces differ fundamentally between robots -- similar encodings can represent completely different physical behaviors.
UniAct proposes a Universal Action Space (UAS) that abstracts away embodiment-specific details by learning a discrete, vector-quantized codebook of 256 generic atomic behaviors shared across diverse robots. A VLM backbone maps observations and language instructions into this universal space, and lightweight embodiment-specific MLP decoders translate universal actions back to native control commands. The 0.5B instantiation outperforms 14x larger SOTA models (OpenVLA-7B, LAPA-7B) on real-world WidowX tasks and LIBERO simulation benchmarks, requiring only 0.8% parameter fine-tuning for new robots.
The significance is a paradigm shift from "one action space per robot" to a shared, interpretable action vocabulary: 40% of universal actions produce consistent, semantically meaningful behaviors across different robot platforms. This enables internet-scale robot data utilization and parameter-efficient cross-embodiment transfer.
Key Contributions
- Universal Action Space (UAS): A discrete VQ codebook (256 codes, 128-dim) capturing generic atomic behaviors universal across 28 robot embodiments, trained end-to-end with Gumbel-Softmax selection
- VLM-based action extractor: Fine-tuned VLM (LLaVA-OneVision-0.5B) that forces diverse robots to map behaviors into the same discrete space, using the model as an information bottleneck
- Lightweight decoder architecture: Per-embodiment MLP heads translating universal actions to precise native control signals, requiring minimal new parameters for adaptation
- Action interpretability: 40% of codebook entries produce consistent, semantically meaningful behaviors across robots; Jensen-Shannon divergence confirms task-focused rather than embodiment-focused clustering
- Parameter efficiency at scale: 0.5B model outperforms 14x larger baselines through superior action representation rather than model scale alone
Architecture
┌──────────────────────────────────────────────────────────┐
│ UniAct Framework │
│ │
│ ┌──────────┐ ┌───────────┐ │
│ │ Visual │ │ Language │ │
│ │Observation│ │Instruction │ │
│ └────┬─────┘ └─────┬─────┘ │
│ │ │ │
│ ▼ ▼ │
│ ┌────────────────────────────┐ │
│ │ LLaVA-OneVision-0.5B │ │
│ │ (Shared VLM Backbone) │ │
│ └────────────┬───────────────┘ │
│ │ │
│ ▼ │
│ ┌────────────────────────────┐ │
│ │ Universal Action Codebook │ │
│ │ 256 codes x 128 dims │ │
│ │ (Gumbel-Softmax select) │ │
│ │ ┌───┬───┬───┬─── ───┐ │ │
│ │ │ u1│ u2│ u3│ ...u256│ │ │
│ │ └───┴───┴───┴─── ───┘ │ │
│ └────────────┬───────────────┘ │
│ │ u* (selected universal action) │
│ ┌─────────┼─────────┐ │
│ ▼ ▼ ▼ │
│ ┌──────┐ ┌──────┐ ┌──────┐ Embodiment-specific │
│ │MLP_1 │ │MLP_2 │ │MLP_k │ decoder heads │
│ │Panda │ │WidowX│ │AIRBOT│ │
│ └──┬───┘ └──┬───┘ └──┬───┘ │
│ ▼ ▼ ▼ │
│ a_1 a_2 a_k Native control commands │
└──────────────────────────────────────────────────────────┘
Architecture / Method
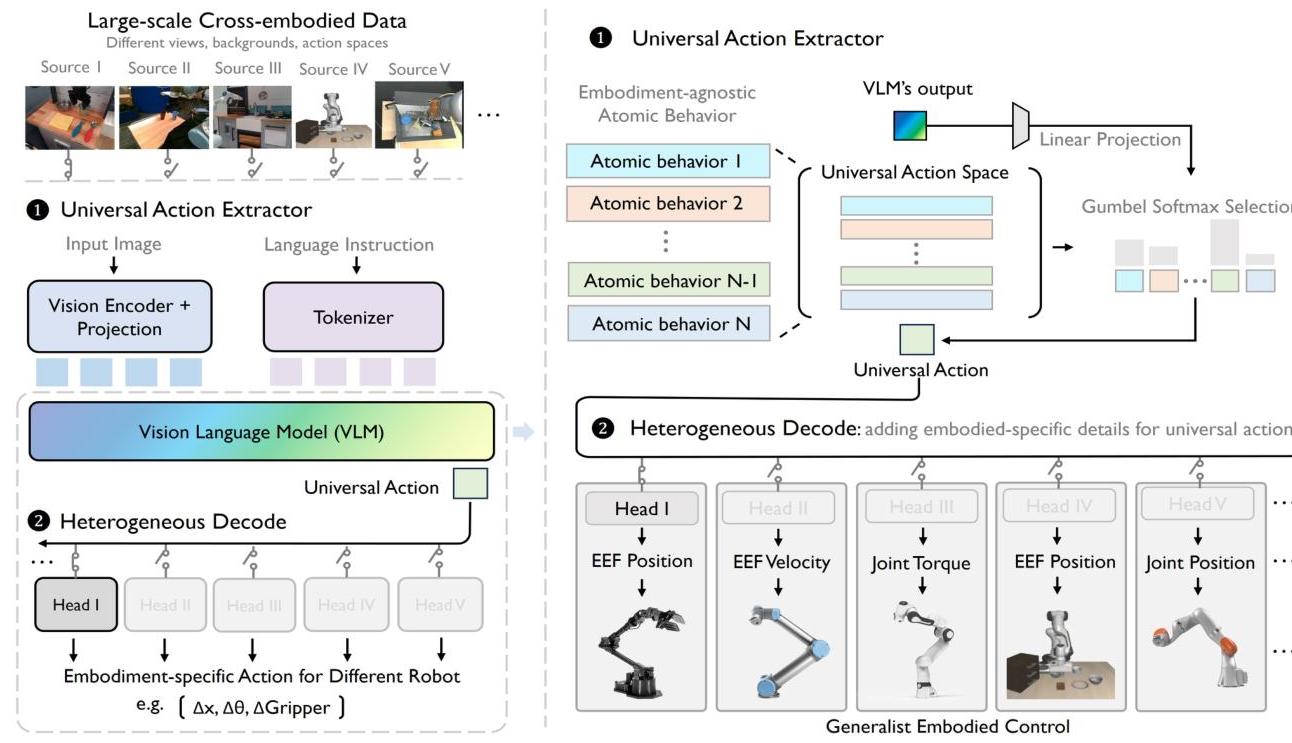
The architecture has three core components:
-
Universal Action Codebook: 256 codes x 128 dimensions, learned via VQ with Gumbel-Softmax for differentiable discrete selection with temperature decay.
-
Shared VLM Backbone: LLaVA-OneVision-0.5B processes visual observations and language instructions, mapping them to universal action selections. The VLM acts as an information bottleneck forcing diverse robot behaviors into a shared discrete space.
-
Embodiment-Specific Decoder Heads: Lightweight MLPs (one per embodiment) that translate universal actions back to native commands: a_k = h_k(u, o), where u is the selected universal action and o is the observation.
Training uses end-to-end behavior cloning across 28 embodiments with 1M demonstrations on 64 A100 GPUs over 10 days. Domain-specific batch sampling ensures balanced learning across embodiments.
Results
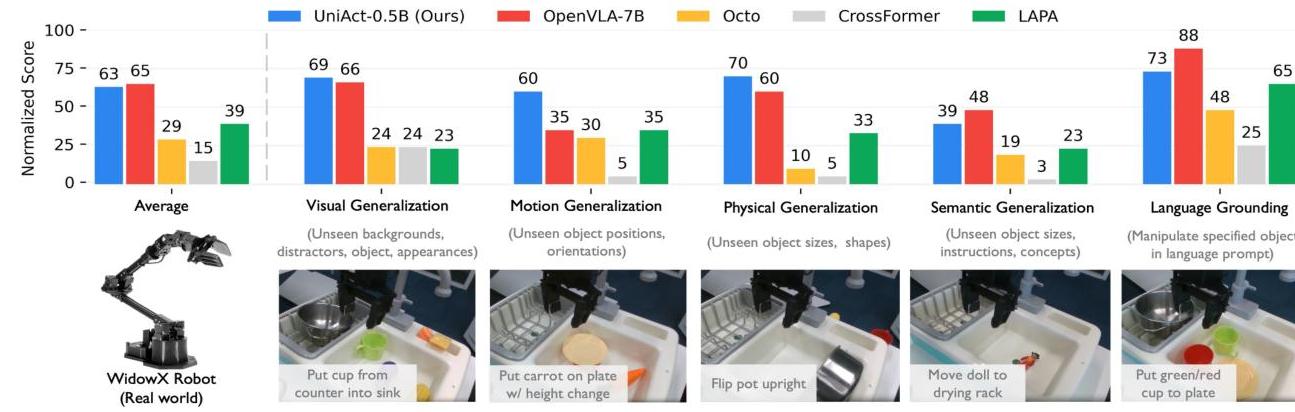
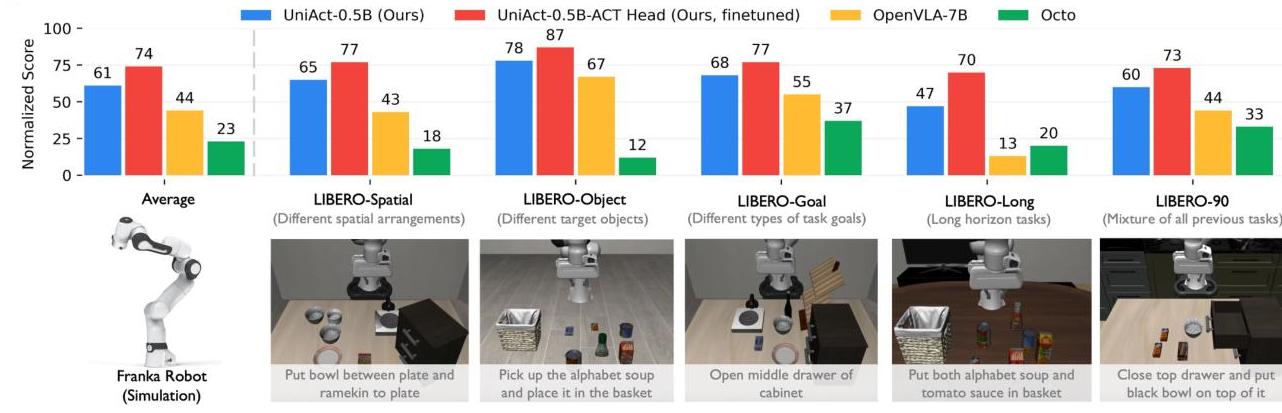
| Configuration | Params | Fine-tune % | Key Result |
|---|---|---|---|
| UniAct-0.5B | 500M | 0.8% (4M) | Outperforms 14x larger models |
| OpenVLA-7B | 7B | 1.4% (97M) | Baseline |
| LAPA-7B | 7B | - | Baseline |
| Octo | 100M | 2% (2M) | Baseline |
- Real-world (WidowX): Outperforms OpenVLA-7B and LAPA-7B across visual, motion, and physical generalization on 19 tasks (190 rollouts)
- Simulation (LIBERO): Surpasses all baselines (Octo, CrossFormer, OpenVLA, LAPA) across five task suites on 130 Franka tasks
- Fast adaptation (AIRBOT): Strong generalization across four controller types using only 100 demonstrations per interface
- Training stability: Universal action space eliminates "conflicted learning patterns" (oscillating losses across modalities) seen in baselines
Limitations
- The 256-code codebook may not capture the full granularity of complex manipulation behaviors; optimal codebook size is not thoroughly explored
- Evaluation focuses on manipulation; applicability to locomotion, navigation, or driving is unvalidated
- Lightweight decoder heads may struggle with high-dimensional or continuous action spaces requiring fine-grained precision
- Reliance on behavior cloning; no RL or self-play refinement of the universal action space
Connections
- Openvla An Open Source Vision Language Action Model -- UniAct outperforms OpenVLA-7B at 14x fewer parameters through better action representation
- Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control -- RT-2 established the VLA paradigm; UniAct decouples action representation from model scale
- A Generalist Agent -- Gato pioneered multi-embodiment control via unified tokens; UniAct replaces flat tokenization with learned universal actions
- Robotics -- Cross-embodiment transfer is a core open problem
- Vision Language Action -- Advances the VLA paradigm with universal action representation
- Foundation Models -- Demonstrates that action representation quality matters more than model scale