Towards Embodiment Scaling Laws in Robot Locomotion
Overview
This paper investigates whether increasing robot diversity during training improves generalization to unseen robots, analogous to how data scaling improves language and vision models. While deep learning has established clear scaling laws in NLP (Chinchilla, Kaplan) and vision, robot embodiment has remained largely unexplored as a scaling axis.
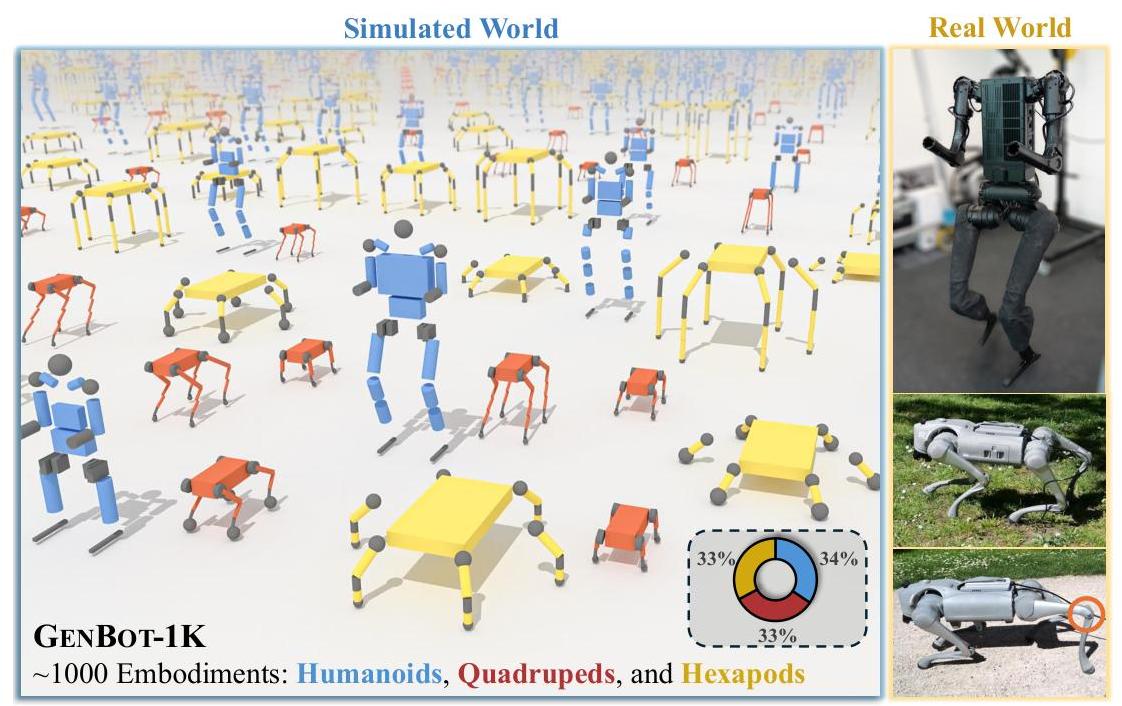
Using GENBOT-1K -- a dataset of nearly 1,000 procedurally generated robots spanning humanoids, quadrupeds, and hexapods with topological, geometric, and kinematic variations -- the authors train a unified control architecture and measure generalization to held-out embodiments. The results provide the first empirical evidence for embodiment scaling laws: training on more diverse morphologies produces consistent positive scaling trends in generalization to unseen robots. An extended URMA (Universal Robot Morphology Architecture) with multi-head attention handles variable input/output spaces and embodiment descriptors. The trained policy achieves zero-shot sim-to-real transfer to physical Unitree Go2 and H1 robots.
Key Contributions
- Embodiment scaling hypothesis validated: First empirical demonstration that training on diverse morphologies yields consistent positive scaling trends for generalization to unseen robots
- GENBOT-1K dataset: ~1,000 procedurally generated embodiments with topological, geometric, and kinematic variations across three robot classes (348 humanoids, 332 quadrupeds, 332 hexapods)
- Extended URMA architecture: Multi-head attention encoder processing variable-length joint observations with embodiment descriptors, enabling a single policy to control morphologically diverse robots
- Two-stage training pipeline: Expert policy training via PPO (2 trillion simulation steps) followed by behavior cloning distillation (2 billion samples)
- Zero-shot sim-to-real transfer: Policy trained on 817 simulated embodiments transfers directly to Unitree Go2 (quadruped) and H1 (humanoid) hardware
Architecture / Method
┌─────────────────────────────────────────────────────────────────┐
│ Extended URMA Architecture │
│ │
│ Per-Joint Inputs Fixed Inputs │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ Joint Obs o_j │ │ Trunk Vel, │ │
│ │ (pos,vel,torq)│ │ Gravity Vec │ │
│ └──────┬───────┘ └──────┬───────┘ │
│ │ │ │
│ ▼ │ │
│ ┌──────────────┐ ┌──────────────┐ │ │
│ │ f_psi(o_j) │ │ f_phi(phi_j) │ │ │
│ │ Obs Encoder │ │ Descriptor │ │ │
│ └──────┬───────┘ │ Encoder │ │ │
│ │ └──────┬───────┘ │ │
│ ▼ ▼ │ │
│ ┌────────────────────────────┐ │ │
│ │ Multi-Head Attention │ │ │
│ │ alpha_j = softmax(f_phi . │ │ │
│ │ f_psi) │ │ │
│ └────────────┬───────────────┘ │ │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────────────────────────────────┐ │
│ │ Global Representation │ │
│ │ (concat attention out + fixed) │ │
│ └──────────────────┬───────────────────┘ │
│ │ │
│ ▼ │
│ ┌──────────────────────────────────────┐ │
│ │ Universal Decoder │ │
│ │ (global repr + joint desc ──► a_j) │ │
│ └──────────────────────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
┌─────────────────────────────────────────────────────────────────┐
│ Two-Stage Training Pipeline │
│ │
│ Stage 1: Expert Training (PPO) Stage 2: Distillation │
│ ┌───────────────────────────┐ ┌──────────────────────┐ │
│ │ Per-embodiment PPO experts│ │ Behavior Cloning │ │
│ │ Isaac Lab, 160 RTX GPUs │─────►│ 2B samples │ │
│ │ 2T+ simulation steps │ │ ──► Single Universal │ │
│ └───────────────────────────┘ │ Policy │ │
│ └──────────────────────┘ │
└─────────────────────────────────────────────────────────────────┘
Core Architecture (Extended URMA): - Embodiment descriptors (phi(e)): Encode fixed kinematic/dynamic properties per joint (joint type, limits, link mass, inertia) - Multi-head attention encoder: Processes variable-length joint observations, capturing inter-joint dependencies. Attention weights: alpha_j = softmax(f_phi(phi_j) . f_psi(o_j)) - Variable I/O handling: Splits observations into fixed general observations (trunk velocity, gravity vector) and variable joint-specific observations (position, velocity, torque) - Universal decoder: Generates joint-specific actions by concatenating a global representation with individual joint descriptions
Two-Stage Training: 1. Expert training: PPO across all embodiments in NVIDIA Isaac Lab, 4,096 parallel environments (2+ trillion steps, 160 RTX 4090/3090 GPUs, ~5 days), with domain randomization and performance-based curriculum 2. Student distillation: Behavior cloning from expert demonstrations (2 billion samples), producing a single universal policy (1 week on a single NVIDIA H100 GPU)
Results
| Metric | Result |
|---|---|
| Humanoid scaling | Linear improvement with more training embodiments |
| Quadruped/Hexapod | Saturation ~100 embodiments within-class |
| Cross-class generalization | 2-5x higher reward vs. single-class policies |
| GENBOT-1K split | 80% train / 20% test across all embodiments |
- Scaling curves: Humanoid performance scales consistently with number of training embodiments (no saturation observed); quadrupeds and hexapods show diminishing returns around 100 within-class embodiments
- Cross-class benefit: Training across all three morphology classes yields 2-5x higher average reward on held-out embodiments compared to single-class training
- Real-world transfer: Unitree Go2 achieves stable walking across grass, cobblestone, and gravel; Unitree H1 walks on flat surfaces -- all zero-shot from simulation
- Kinematic adaptation: Policy learns stable limping gaits when robot has restricted knee range of motion, demonstrating morphological robustness
Computational requirements: Expert training takes ~5 days on 160 NVIDIA RTX 4090/3090 GPUs (NVIDIA Isaac Lab). Distillation takes ~1 week on a single NVIDIA H100 GPU.
Limitations
- Locomotion only -- no manipulation, navigation, or driving tasks; unclear if embodiment scaling extends to contact-rich or dexterous tasks
- Positive scaling trends are observed but their precise functional form and constants are not fully characterized; the "Chinchilla" of embodiment scaling remains unknown
- Procedurally generated robots, while diverse, may not capture the full complexity of real-world robot designs
- Distillation from per-embodiment experts to a universal policy may lose specialist performance; direct multi-embodiment RL could yield different scaling behavior
- Real-world evaluation limited to two Unitree robots; broader hardware validation needed
Connections
- Scaling Laws For Neural Language Models -- Kaplan scaling laws for language; this paper asks whether analogous laws exist for embodiment diversity
- Training Compute Optimal Large Language Models -- Chinchilla established compute-optimal scaling; embodiment scaling adds a new axis
- Uniact Universal Actions For Enhanced Embodied Foundation Models -- UniAct handles cross-embodiment manipulation via universal actions; this paper handles cross-embodiment locomotion via architectural design
- Groot N1 An Open Foundation Model For Generalist Humanoid Robots -- GR00T N1 targets humanoid generalization; this work covers broader morphology classes
- Robotics -- Directly addresses cross-embodiment transfer, a core open problem
- Foundation Models -- Extends scaling law analysis to embodied AI