Overview
GR00T N1 addresses the challenge of creating general-purpose humanoid robots through an innovative "data pyramid" approach. Rather than relying solely on expensive real-world data collection, the model integrates heterogeneous data sources including web data, human videos, synthetic simulations, and actual robot trajectories. This hierarchical data strategy enables training at scale while keeping real-world data requirements manageable.
The architecture uses a dual-system design that separates reasoning from motor control. A vision-language module (System 2) based on Eagle-2 VLM handles high-level scene understanding and task reasoning at 10Hz, while a flow-matching diffusion transformer (System 1) generates 16-action chunks at 120Hz. These two systems communicate through cross-attention mechanisms with embodiment-specific encoders, allowing the model to adapt to different robot morphologies.
A notable contribution is the concept of "neural trajectories" -- AI-generated videos augmented with pseudo-action labels via learned action prediction and inverse dynamics models (LAPA and IDM). These synthetic trajectories consistently improve real-world performance by 4-9%, effectively bridging the gap between cheap video data and expensive teleoperated demonstrations.
Key Contributions
- Data pyramid framework: Hierarchical integration of web/human video (base), synthetic simulation (middle), and real robot trajectories (peak) for scalable training
- Dual-system architecture: Separation of slow reasoning (VLM at 10Hz) from fast action generation (flow-matching diffusion transformer at 120Hz) via cross-attention
- Neural trajectory augmentation: AI-generated videos with pseudo-action labels that improve task success by 4-9% over baselines without this data
- Open foundation model: Released as an open model enabling the broader robotics community to build on generalist humanoid control
- Cross-embodiment design: Embodiment-specific encoders allow the same architecture to be deployed on different robot platforms
Architecture / Method
┌─────────────────────────────────────────────────────────────┐
│ DATA PYRAMID │
│ │
│ /\ │
│ / \ Real Robot Trajectories │
│ / \ (teleoperated demos) │
│ /──────\ │
│ / Synth. \ Synthetic Simulation │
│ / (Isaac) \ (MuJoCo, Isaac Gym) │
│ /────────────\ │
│ / Web + Human \ Internet Video & Text │
│ / Video Data \ (neural trajectories) │
│ /───────────────────\ │
└─────────────────────────────────────────────────────────────┘
┌──────────────────────────────────────────────────────────────┐
│ DUAL-SYSTEM ARCHITECTURE │
│ │
│ ┌─────────────┐ Language ┌──────────────────────┐ │
│ │ Camera │ Instruction │ System 2 (10 Hz) │ │
│ │ Images │───────────────►│ Eagle-2 VLM (2B) │ │
│ └─────────────┘ │ Scene Understanding │ │
│ │ Task Reasoning │ │
│ └─────────┬────────────┘ │
│ Semantic │ Embeddings │
│ (cross-attention) │
│ ▼ │
│ ┌─────────────┐ ┌──────────────────────┐ │
│ │ Propriocep. │───────────────►│ System 1 (120 Hz) │ │
│ │ State │ Embodiment- │ Diffusion │ │
│ │ (joints, │ Specific │ Transformer (DiT) │──►│ Actions
│ │ forces) │ Encoders │ Flow Matching │ │
│ └─────────────┘ └──────────────────────┘ │
└──────────────────────────────────────────────────────────────┘
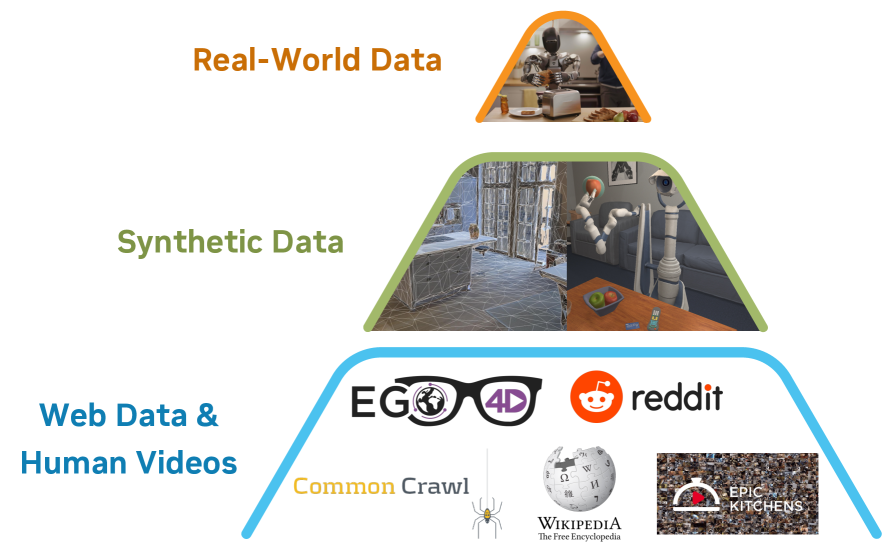
The data pyramid organizes training data by cost and fidelity: internet-scale video and text at the base, synthetic simulation data in the middle, and expensive real robot demonstrations at the peak.
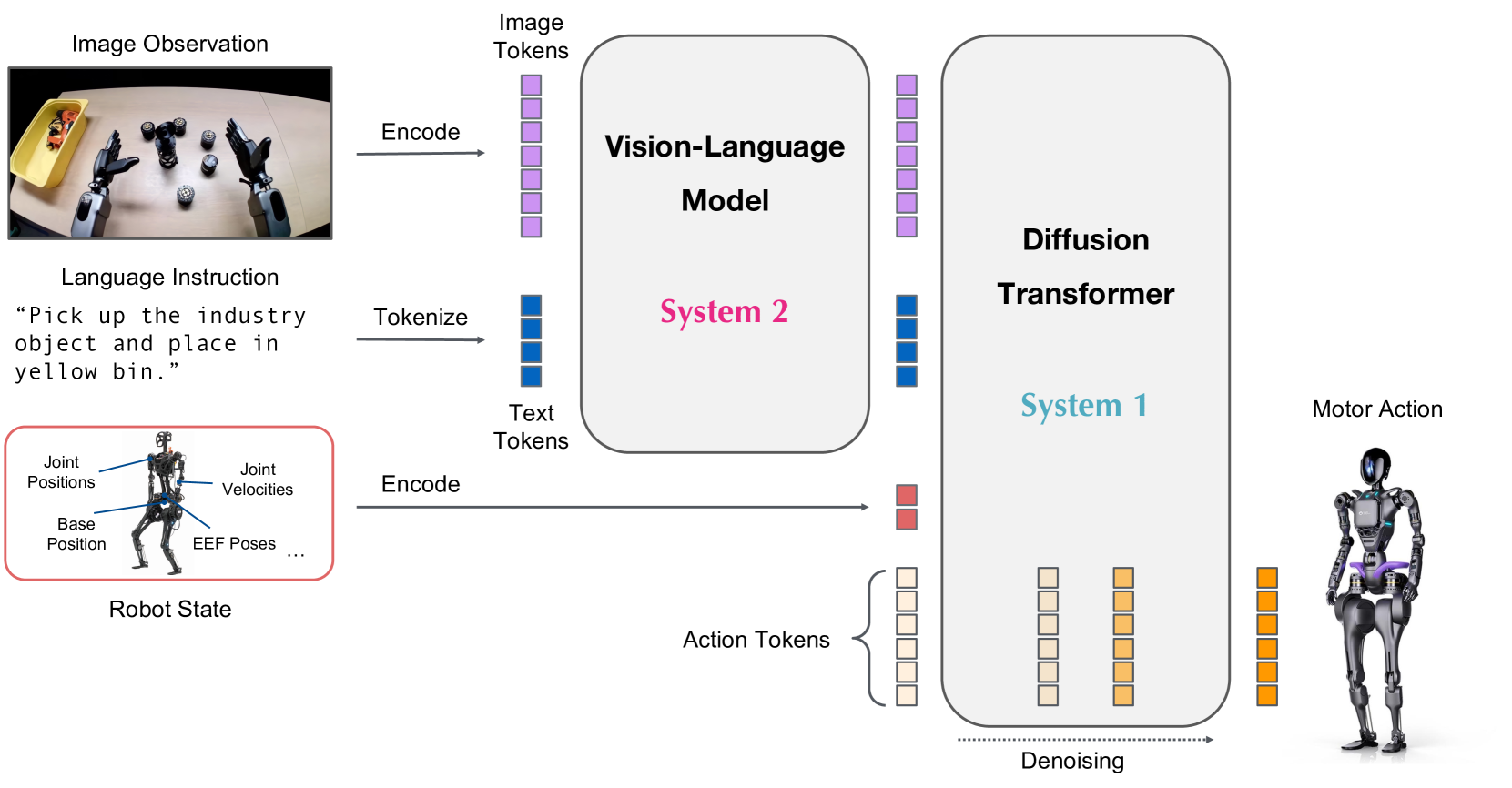
System 2 (Vision-Language) processes camera images and language instructions through Eagle-2 VLM, producing semantic embeddings at 10Hz. System 1 (Flow-Matching DiT) consumes these embeddings alongside proprioceptive state and generates 16-action chunks at 120Hz via flow matching.
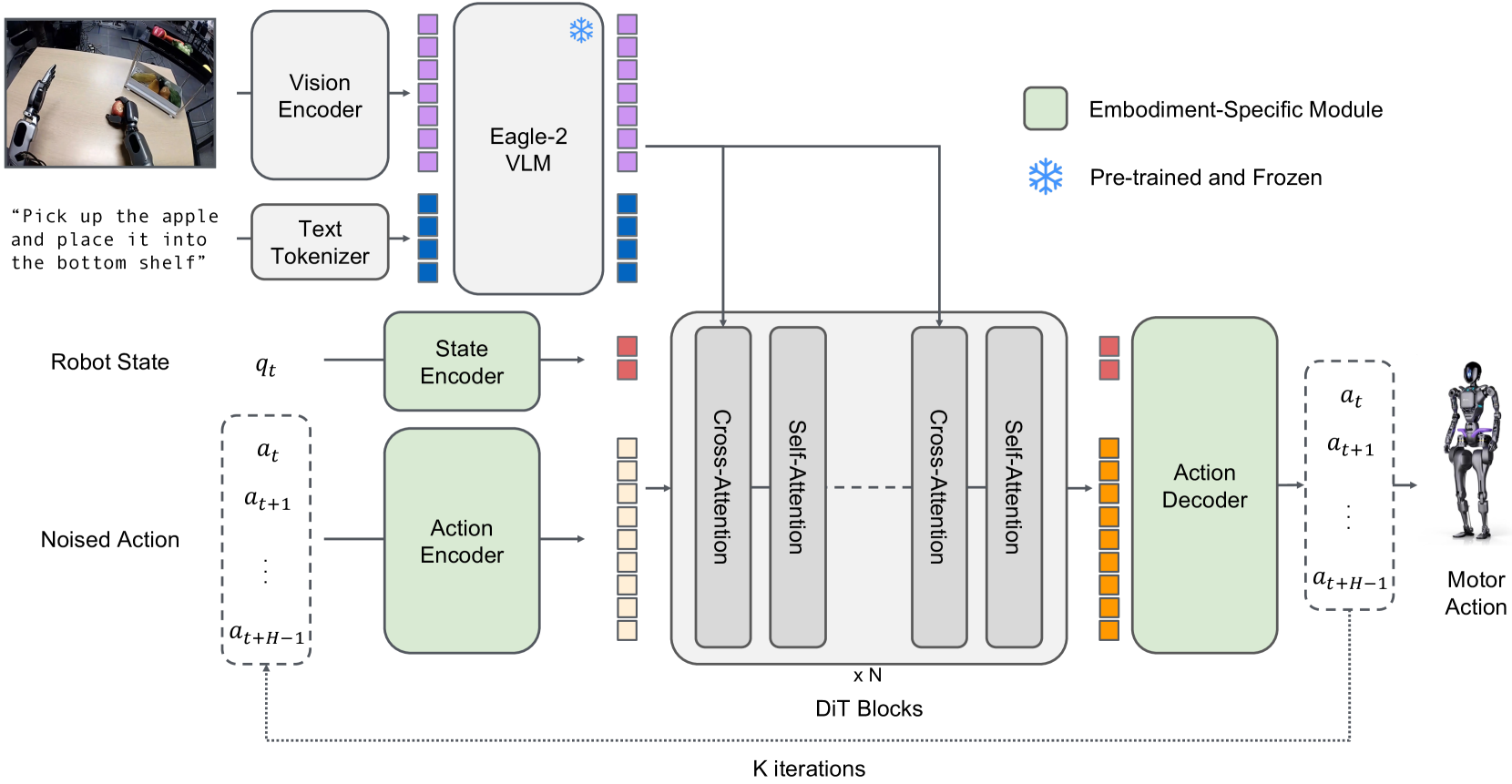
The integration uses cross-attention between the VLM output tokens and the diffusion transformer's action tokens. Embodiment-specific encoders handle proprioception for different robot platforms (GR-1 humanoid, tabletop arms).
Results
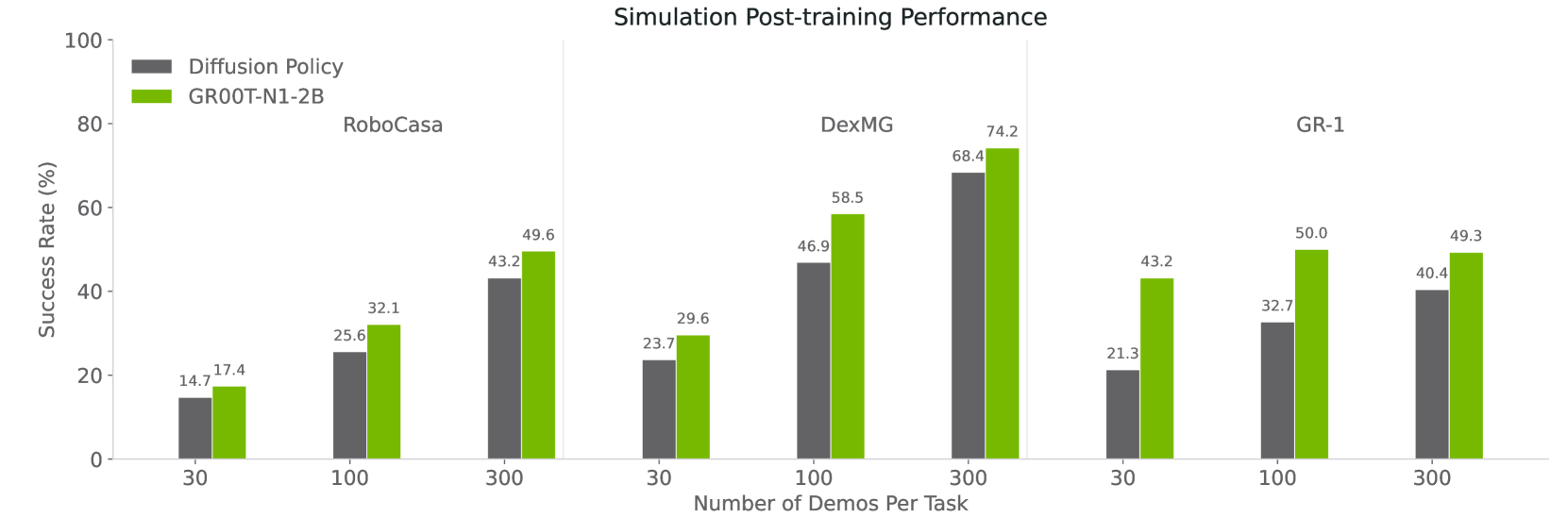
| Benchmark | GR00T N1 | Best Baseline | Improvement |
|---|---|---|---|
| RoboCasa + DexMG (sim avg) | 45.0% | 33.4% | +11.6% |
| GR-1 Real (full data) | 76.8% | -- | -- |
| GR-1 Real (10% data) | 42.6% | -- | -- |
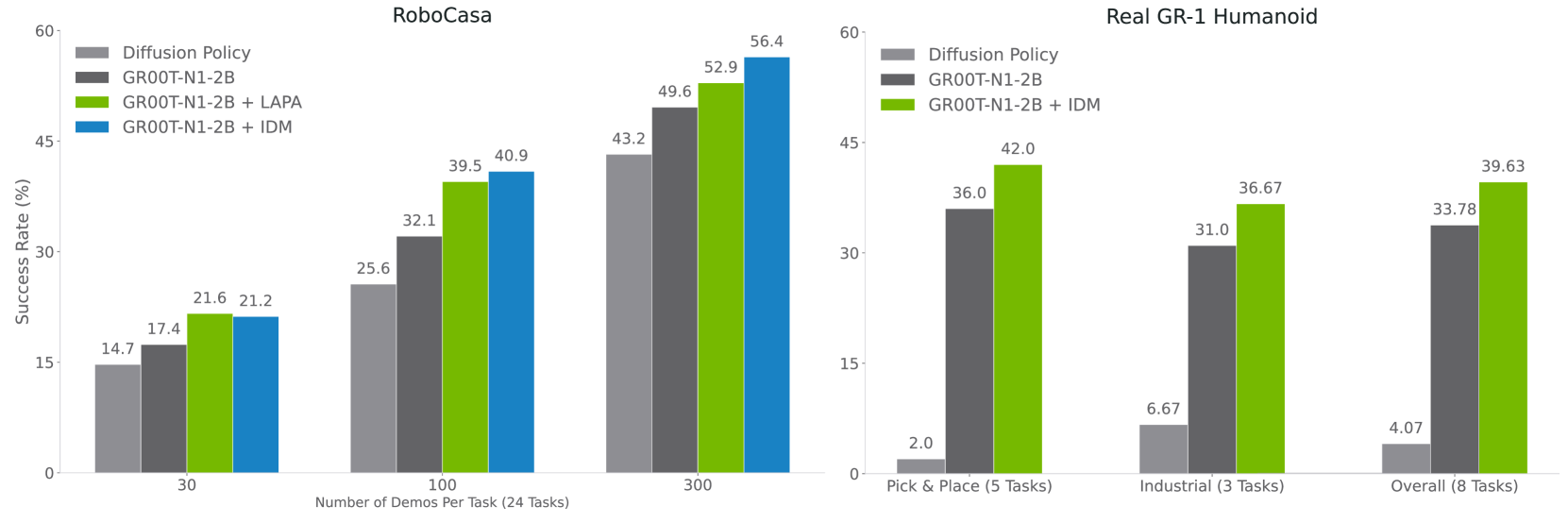
Neural trajectory augmentation consistently improves performance by 4-9% across benchmarks, validating the data pyramid approach for scaling robot learning.
Limitations & Open Questions
- Performance on long-horizon tasks and multi-step planning remains limited compared to short tabletop manipulation
- The 10Hz reasoning frequency may be too slow for highly dynamic environments requiring rapid replanning
- Real-world evaluation is primarily on structured tabletop and pick-and-place tasks; generalization to unstructured environments is not fully demonstrated
Connections
- Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control -- RT-2 established the VLA blueprint that GR00T N1 extends to humanoid robots
- Openvla An Open Source Vision Language Action Model -- OpenVLA similarly aimed to democratize VLA research; GR00T N1 extends this to humanoid scale
- Palm E An Embodied Multimodal Language Model -- PaLM-E pioneered VLM-as-reasoning-backbone for embodied agents, which GR00T N1's System 2 builds on
- A Generalist Agent -- Gato's generalist agent paradigm is a direct ancestor of the generalist humanoid agent vision
- Robotics -- Extends the VLA revolution to full humanoid embodiment
- Vision Language Action -- Dual-system design is a new point in the VLA design space