Overview
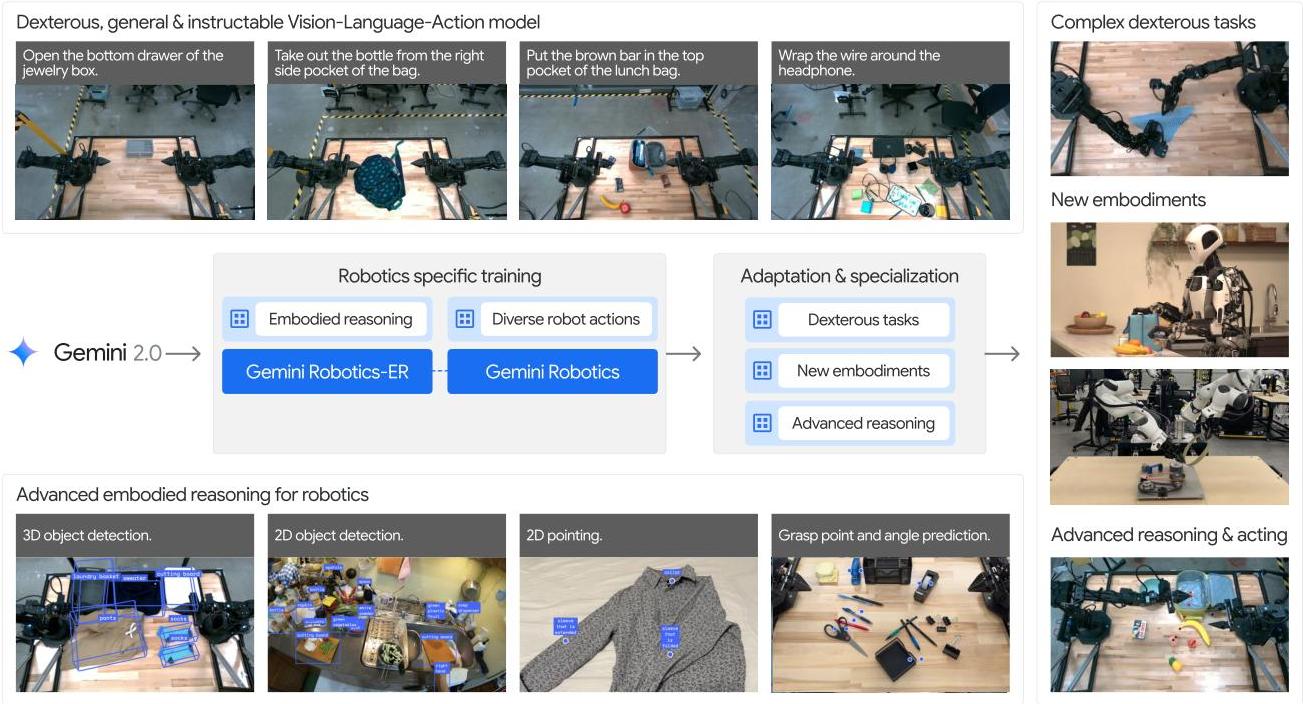
Gemini Robotics introduces a family of AI models built on Gemini 2.0 designed to extend advanced multimodal capabilities into physical robotics. The work addresses a fundamental challenge in AI: translating digital understanding abilities into embodied agents capable of safe, effective real-world manipulation and interaction.
The system comprises two core models. Gemini Robotics-ER (Embodied Reasoning) enhances Gemini 2.0 with advanced spatial understanding, enabling object detection, pointing, trajectory prediction, top-down grasp prediction, and 3D scene comprehension. Gemini Robotics functions as a full Vision-Language-Action model for direct robot control, combining a cloud-hosted backbone optimized for low latency with a local action decoder on the robot's computer, achieving 50Hz control frequency.
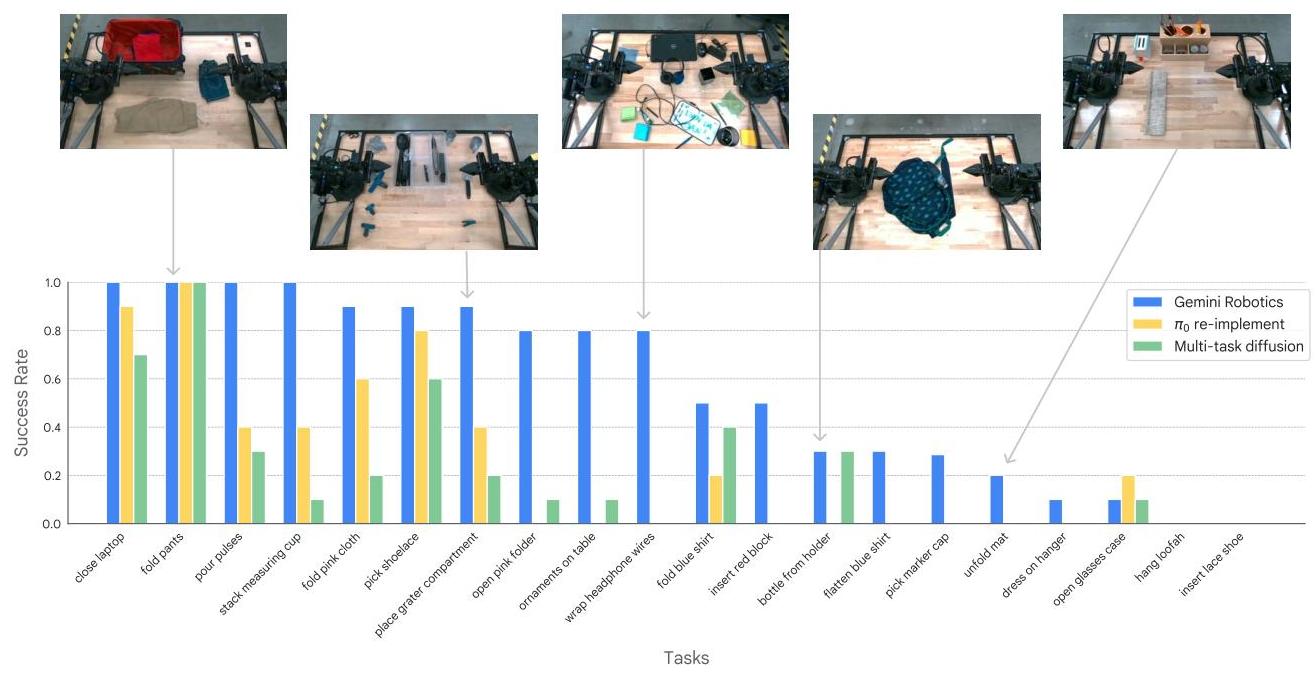
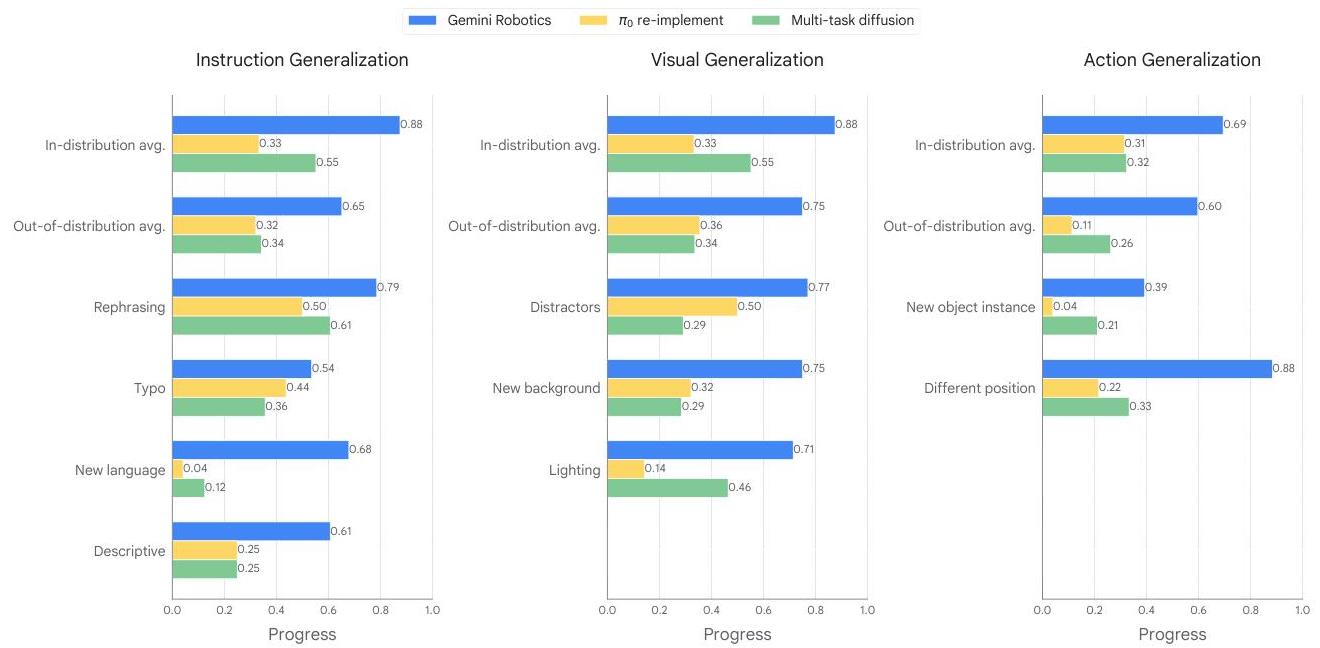
Training leverages thousands of hours of expert teleoperated demonstrations on ALOHA 2 robots, combined with Gemini's extensive multimodal web pretraining. The model achieves over 80% success on half of 20 diverse manipulation tasks, generalizes robustly across visual and instruction variations, and adapts rapidly to new tasks with minimal demonstrations. Specialized variants achieve 79% average success on demanding long-horizon tasks including origami folding. The work also emphasizes responsible development through inherited safety mechanisms and a novel semantic action safety evaluation framework (ASIMOV).
Key Contributions
- Two-tier model family: Gemini Robotics-ER for embodied reasoning (spatial understanding, top-down grasp prediction) and Gemini Robotics for direct VLA control at 50Hz
- Cloud-local hybrid architecture: Cloud-hosted VLM backbone for rich reasoning with local action decoder for low-latency control
- Strong generalization: Robust performance across visual variations, instruction paraphrasing, and unseen object categories
- Long-horizon capabilities: 79% success on complex multi-step tasks including origami folding
- Cross-embodiment transfer: Successful adaptation to novel robot embodiments beyond the training platform
- ASIMOV safety framework: Novel semantic action safety evaluation for responsible robot deployment
Architecture / Method
┌─────────────────────────────────────────────────────────────────┐
│ Gemini Robotics System │
│ │
│ ┌──────────────────────────────────────────┐ ┌────────────┐ │
│ │ Cloud (Gemini 2.0 Backbone) │ │ Robot │ │
│ │ │ │ (ALOHA 2) │ │
│ │ Camera ──► Vision ──► Gemini 2.0 VLM │ │ │ │
│ │ Images Encoder (multimodal │ │ ┌────────┐ │ │
│ │ reasoning) │ │ │ Local │ │ │
│ │ Language ──────────────┘ │ │ │ Action │ │ │
│ │ Instruction │ │ │ │Decoder │ │ │
│ │ ▼ │ │ │ (50Hz) │ │ │
│ │ ┌────────────────┐ │ │ └───┬────┘ │ │
│ │ │ Gemini │ latent ──────────►│ │ │ │
│ │ │ Robotics-ER │ features │ │ ▼ │ │
│ │ │ (spatial │ │ │ Joint │ │
│ │ │ understanding)│ │ │ Actions │ │
│ │ └────────────────┘ │ │ ──► Robot│ │
│ │ - Object detection │ │ │ │
│ │ - Top-down grasp prediction │ └────────────┘ │
│ │ - Trajectory prediction │ │
│ └──────────────────────────────────────────┘ │
│ │
│ Training: Web pretraining ──► Teleoperation fine-tuning │
│ (Gemini 2.0) (1000s hrs on ALOHA 2) │
└─────────────────────────────────────────────────────────────────┘
The architecture builds on Gemini 2.0's multimodal foundation. Gemini Robotics-ER adds spatial understanding modules for object detection, pointing, top-down grasp prediction (y, x, rotation angle), and trajectory prediction. The full Gemini Robotics model extends this with an action generation head.

The VLA model uses a split architecture: the Gemini backbone runs in the cloud with optimized serving for low latency, while a lightweight action decoder runs locally on the robot's computer at 50Hz. This hybrid approach balances the reasoning power of a large model with the real-time requirements of physical control.
Training combines: (1) Gemini 2.0's multimodal web pretraining for world knowledge, (2) thousands of hours of expert teleoperated demonstrations on ALOHA 2 platforms, and (3) task-specific fine-tuning for specialized capabilities.
Results
| Evaluation Dimension | Performance |
|---|---|
| Manipulation tasks (20 tasks) | >80% success on 10+ tasks |
| Long-horizon tasks (6 tasks) | 79% average success |
| Visual generalization | Robust across appearance variations |
| Instruction generalization | Robust across paraphrasing |
| Object generalization | Transfers to unseen object categories |
| Few-shot adaptation | Rapid task learning from minimal demos |

The model successfully transfers to novel robot embodiments not seen during training, suggesting that the Gemini backbone captures manipulation knowledge that generalizes across physical platforms.
Limitations & Open Questions
- Cloud-hosted backbone introduces network latency dependency; fully on-device deployment of large models remains unsolved
- Evaluation primarily on ALOHA 2 bimanual manipulation; mobile manipulation and locomotion are not addressed
- Safety framework (ASIMOV) is a first step but lacks formal guarantees for deployment in unstructured human environments
Connections
- Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control -- RT-2 established the VLM-to-VLA fine-tuning paradigm that Gemini Robotics scales up with Gemini 2.0
- Palm E An Embodied Multimodal Language Model -- PaLM-E pioneered large VLM for embodied reasoning; Gemini Robotics-ER is the next-generation version
- Openvla An Open Source Vision Language Action Model -- Contrasting approach: open-source smaller model vs. proprietary large-scale system
- Groot N1 An Open Foundation Model For Generalist Humanoid Robots -- Contemporary work on foundation models for robotics; GR00T N1 targets humanoids while Gemini Robotics targets bimanual manipulation
- Robotics -- Represents the industry frontier of VLA robotics
- Foundation Models -- Demonstrates transfer from web-scale multimodal pretraining to physical control