Overview
Gemini 2.5 is Google's frontier multimodal model family, built on a sparse Mixture-of-Experts (MoE) Transformer architecture. It represents a major advance in reasoning, multimodal understanding, long-context processing (exceeding 1 million tokens), and agentic capabilities. The model family spans multiple capability tiers -- Gemini 2.5 Pro, Gemini 2.5 Flash, and the earlier Gemini 2.0 Flash and Flash-Lite -- covering the full capability-cost spectrum for deployment.
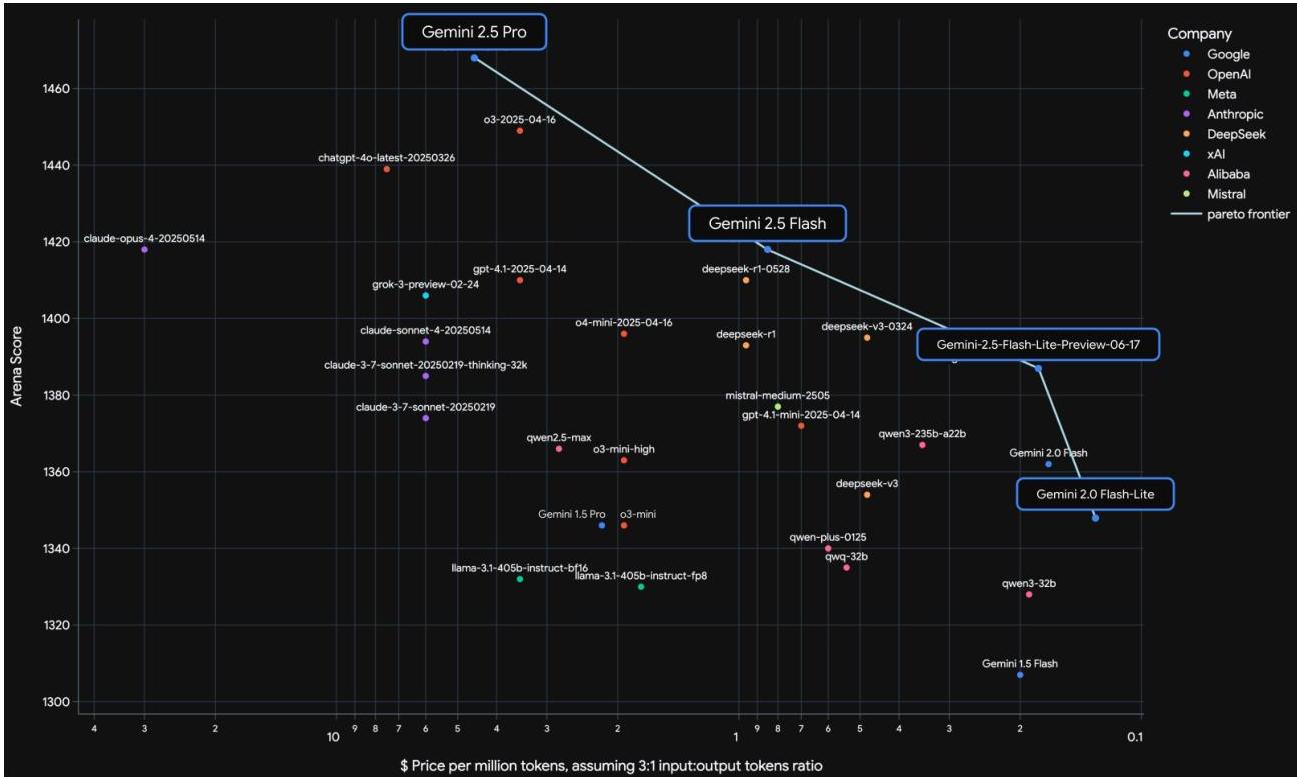
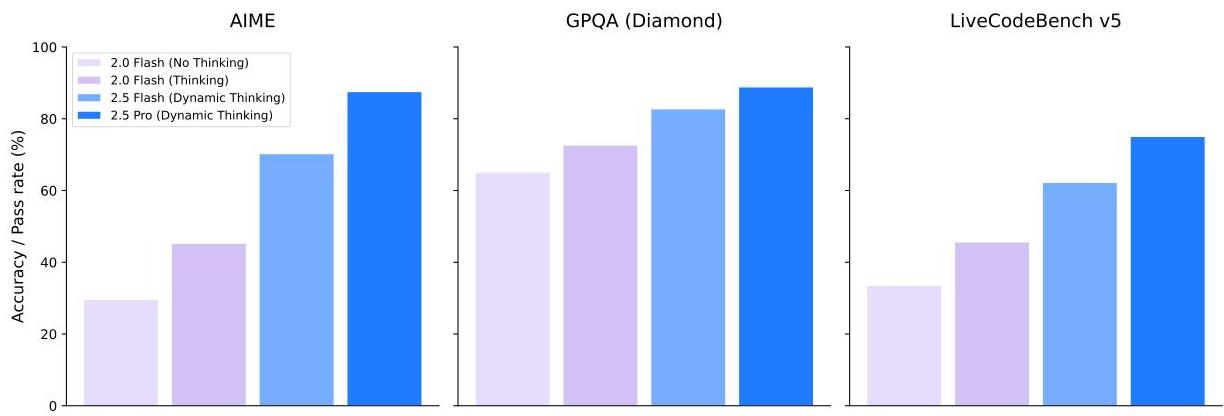
A defining feature is the "Thinking" mechanism, which allows models to perform tens of thousands of forward passes during a dedicated reasoning phase before producing a final answer. This extended inference-time compute dramatically improves performance on tasks requiring deep reasoning: LiveCodeBench scores jump from 29.7% to 74.2% and AIME 2025 scores from 17.5% to 88.0% compared to Gemini 1.5 Pro. The approach aligns with the broader trend of scaling inference-time compute (test-time compute scaling) rather than only training-time compute.
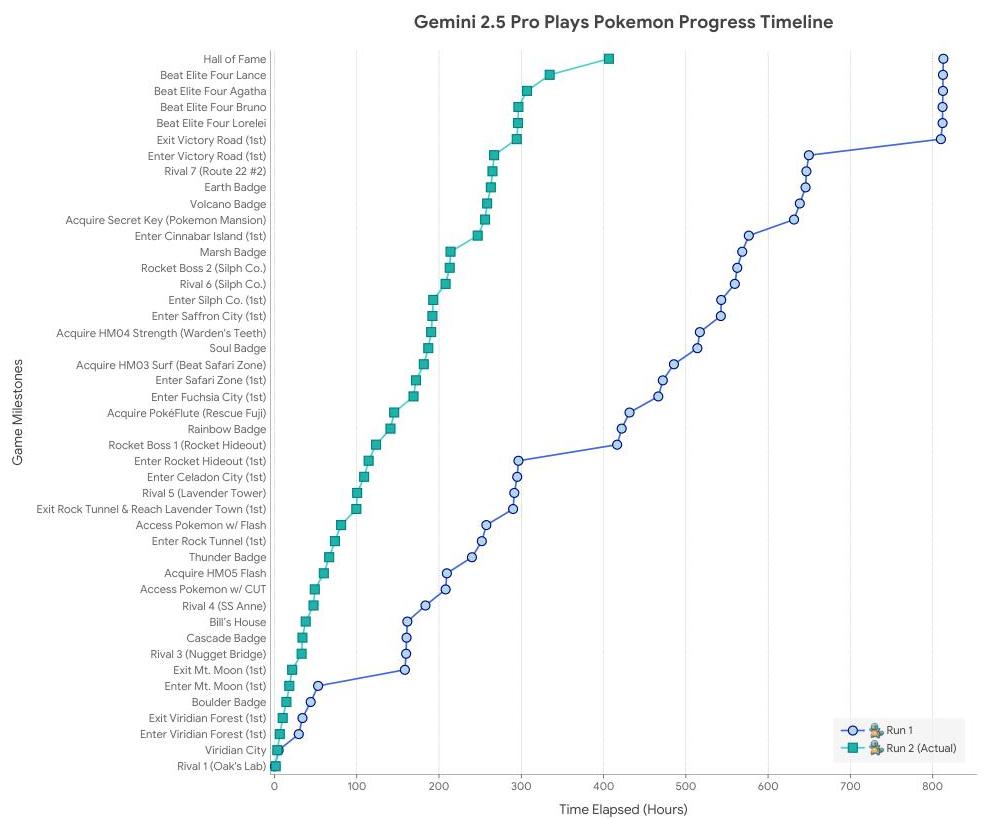
Training was conducted on Google's TPUv5p architecture using synchronous data-parallel processing across multiple pods. The paper describes key infrastructure innovations for reliability at scale: "Slice-Granularity Elasticity" maintains approximately 97% throughput during hardware failures by dynamically adjusting the training configuration, and "Split-Phase SDC Detection" identifies Silent Data Corruption errors that can silently degrade model quality. Agentic capabilities are demonstrated through complex tasks including autonomous completion of Pokemon Blue, which requires long-term strategic planning and coherent decision-making over extended horizons. Safety evaluations using the Frontier Safety Framework confirmed no Critical Capability Levels reached for dangerous domains (though an alert threshold for Cyber Uplift Level 1 was triggered, prompting mitigation), with improved helpfulness and reduced memorization.
Key Contributions
- Sparse MoE Transformer architecture supporting native multimodal input (text, image, video, audio, code) with context windows exceeding 1 million tokens -- enabling processing of entire code repositories, lengthy documents, and up to 3 hours of video
- "Thinking" mechanism for extended inference-time reasoning via tens of thousands of forward passes, producing dramatic gains on math and coding benchmarks (AIME 2025: 17.5% → 88.0%; LiveCodeBench: 29.7% → 74.2% vs. Gemini 1.5 Pro)
- Training infrastructure innovations -- Slice-Granularity Elasticity (~97% throughput maintenance during failures) and Split-Phase SDC Detection for silent data corruption, enabling reliable training at massive scale on TPUv5p
- Full capability-cost spectrum with Gemini 2.5 Pro, 2.5 Flash, 2.0 Flash, and 2.0 Flash-Lite tiers, allowing deployment across different latency and cost requirements
- Agentic capabilities demonstrated through complex long-horizon tasks requiring strategic planning and sustained coherence
Architecture / Method
┌─────────────────────────────────────────────────────────────┐
│ Gemini 2.5 (Sparse MoE Transformer) │
│ │
│ Inputs: Text ─┐ │
│ Image ─┤ │
│ Video ─┼──► Tokenizer ──► [Token Sequence] │
│ Audio ─┤ (native multimodal) │
│ Code ─┘ │
│ │ │
│ ▼ │
│ ┌────────────────────────┐ │
│ │ MoE Transformer Layers│ │
│ │ ┌──────────────────┐ │ │
│ │ │ Attention │ │ │
│ │ └────────┬─────────┘ │ │
│ │ ▼ │ │
│ │ ┌──────────────────┐ │ │
│ │ │ Expert Router │ │ Context: >1M tokens│
│ │ │ ┌───┐┌───┐┌───┐│ │ │
│ │ │ │E_1││E_2││E_k││ │ (sparse activation │
│ │ │ └───┘└───┘└───┘│ │ per token) │
│ │ └────────┬─────────┘ │ │
│ └───────────┼────────────┘ │
│ ▼ │
│ ┌────────────────────────┐ │
│ │ "Thinking" Phase │ │
│ │ (extended CoT reasoning│ │
│ │ 10K+ forward passes) │ │
│ │ [tunable budget] │ │
│ └───────────┬────────────┘ │
│ ▼ │
│ Final Response │
└─────────────────────────────────────────────────────────────┘
Model Tiers: 2.5 Pro (max capability)
2.5 Flash (balanced)
2.0 Flash (high performance, low cost)
2.0 Flash-Lite (efficiency)
Gemini 2.5 uses a sparse Mixture-of-Experts Transformer, where each input token is routed to a subset of expert modules rather than activating the full network. This enables the model to maintain a very large total parameter count (and thus capacity) while keeping per-token compute manageable. Native multimodal processing means images, video, audio, and code are handled directly by the model without separate external encoders at inference time.
The "Thinking" mechanism introduces an extended reasoning phase at inference time. Before generating a final response, the model performs a dedicated chain-of-thought reasoning process involving potentially tens of thousands of forward passes. This is conceptually related to chain-of-thought prompting but is built into the model's inference procedure rather than relying on prompt engineering. The thinking budget can be tuned, trading off latency for reasoning quality.
Training leverages Google's TPUv5p infrastructure with synchronous data parallelism distributed across multiple pods. Two key infrastructure contributions address reliability at extreme scale:
- Slice-Granularity Elasticity: When hardware failures occur (inevitable at the scale of thousands of accelerators), the system dynamically reconfigures training to continue with reduced resources rather than halting entirely, maintaining ~97% throughput.
- Split-Phase SDC Detection: Silent Data Corruption -- hardware errors that produce wrong results without triggering error flags -- is detected through a split-phase verification scheme that catches corrupted computations before they pollute the model.
Results
| Benchmark | Gemini 1.5 Pro (baseline) | Gemini 2.5 Pro | Domain |
|---|---|---|---|
| AIME 2025 | 17.5% | 88.0% | Mathematical reasoning |
| LiveCodeBench | 29.7% | 74.2% | Code generation |
| Context window | 1M+ tokens | 1M+ tokens | Long-context |
Gemini 2.5 Pro achieves state-of-the-art or near-state-of-the-art results across a wide range of benchmarks spanning mathematical reasoning, coding, multimodal understanding, and agentic tasks. The most dramatic improvements come from the Thinking mechanism on tasks requiring extended reasoning chains.
The model family demonstrates strong agentic capabilities, with the Pokemon Blue demonstration serving as a challenging benchmark for long-horizon planning, memory, and strategic decision-making over thousands of sequential actions.
Limitations & Open Questions
- Inference cost of Thinking: The extended reasoning phase dramatically improves accuracy but increases latency and compute cost; the optimal thinking budget for different task types remains an open tuning question
- Opacity of MoE routing: How expert specialization develops and whether certain experts specialize for certain modalities or reasoning types is not fully characterized
- Agentic reliability: While impressive demonstrations exist, systematic evaluation of agentic failure modes and recovery strategies at production scale is still developing
- Comparison methodology: As with many frontier model reports, exact architectural details (total parameters, number of experts, routing strategy) are withheld, making independent reproduction and fair comparison difficult
- Safety at scale: While no Critical Capability Levels were reached, an alert threshold for Cyber Uplift Level 1 was triggered, and the rapidly improving reasoning capabilities raise questions about future evaluations as models become more capable
Connections
Related papers in the wiki: - Gpt 4 Technical Report -- closest comparable work: frontier multimodal model technical report with similar disclosure constraints and emphasis on predictable scaling - Attention Is All You Need -- foundational Transformer architecture underlying Gemini - Mixtral Of Experts -- sparse MoE architecture for LLMs; Gemini 2.5 extends MoE to the multimodal frontier scale - Chain Of Thought Prompting Elicits Reasoning In Large Language Models -- Gemini 2.5's Thinking mechanism builds on and internalizes the chain-of-thought reasoning paradigm - Scaling Laws For Neural Language Models -- scaling laws that motivate the large-scale training approach - Training Compute Optimal Large Language Models -- compute-optimal training insights relevant to Gemini's training infrastructure design - Palm Scaling Language Modeling With Pathways -- Google's prior large-scale LM trained on the Pathways system; Gemini represents the next generation - Gemini Robotics Bringing Ai Into The Physical World -- downstream application of the Gemini 2.0 foundation to physical robotics; Gemini 2.5 provides the upgraded reasoning backbone - Foundation Models -- broader context on foundation models and their role in AI - Machine Learning -- scaling laws and transformer architecture context