Overview
PaLM (Pathways Language Model) is a 540-billion parameter dense decoder-only Transformer language model trained by Google using the Pathways distributed training system. It represents a landmark in large language model development, demonstrating that continued scaling of dense Transformers yields substantial improvements in few-shot learning, reasoning, and code generation -- and crucially, that certain capabilities emerge only at sufficient scale rather than improving gradually. PaLM achieved state-of-the-art few-shot performance on 28 of 29 English NLP benchmarks, surpassing GPT-3, Gopher, and Chinchilla across the board.
The core technical contribution is twofold. First, PaLM demonstrates pipeline-free training at unprecedented scale: 6,144 TPU v4 chips across two datacenter pods, achieving 46.2% Model FLOPs Utilization (MFU) -- far higher than prior large models. This was enabled by Google's Pathways system, which orchestrates accelerator resources without the pipeline parallelism that introduces bubbles and complexity. Second, PaLM provides a systematic study of scaling behavior across three model sizes (8B, 62B, 540B), revealing "discontinuous improvements" on roughly 25% of BIG-bench tasks where performance jumps sharply from 62B to 540B, suggesting emergent capabilities at critical scale thresholds.
When combined with chain-of-thought prompting, PaLM 540B achieved 58% on GSM8K math reasoning (surpassing fine-tuned specialist models), strong performance on logical inference and multi-step problem solving, and 76.2% pass@100 on HumanEval code generation despite only 5% code in training data. These results were among the first strong demonstrations that general-purpose language models could match or surpass task-specific systems on reasoning and coding tasks.
Key Contributions
- Efficient large-scale training via Pathways: Pipeline-free training of a 540B parameter model across 6,144 TPU v4 chips in two pods, achieving 46.2% MFU -- a significant efficiency improvement over prior large model training setups that relied on pipeline parallelism.
- Discontinuous scaling behavior: Systematic analysis showing ~25% of BIG-bench tasks exhibit sharp capability jumps from 62B to 540B, providing evidence for emergent abilities in large language models.
- State-of-the-art few-shot performance: SOTA on 28/29 English NLP benchmarks in few-shot evaluation, surpassing average human performance on BIG-bench across 58 tasks.
- Reasoning breakthroughs with chain-of-thought: When combined with chain-of-thought prompting, PaLM achieved 58% on GSM8K and strong multi-step reasoning, demonstrating that output structure (intermediate steps) can substitute for scale alone.
- Code generation from a general model: 76.2% pass@100 on HumanEval despite only 5% code training data, rising to 88.4% with PaLM-Coder fine-tuning -- showing that code and natural language share transferable reasoning patterns.
Architecture / Method
PaLM Transformer Block
──────────────────────
Input x
│
├──────────────────┬──────────────────┐
│ │ │
▼ ▼ │
┌──────────┐ ┌──────────┐ │
│LayerNorm │ │LayerNorm │ │
└────┬─────┘ └────┬─────┘ │
│ │ │
▼ ▼ │
┌──────────┐ ┌──────────┐ │
│Multi-Query│ │ SwiGLU │ │
│Attention │ │ MLP │ Parallel │
│(shared KV │ │ │ Formulation
│ heads) │ │ │ │
└────┬─────┘ └────┬─────┘ │
│ │ │
└───────┬───────┘ │
│ sum │
└──────────┬───────────────┘
│ residual add
▼
Output y = x + Attn(LN(x)) + MLP(LN(x))
Pathways Training System
────────────────────────
┌─────────────────────┐ ┌─────────────────────┐
│ TPU v4 Pod 1 │ │ TPU v4 Pod 2 │
│ 3,072 chips │ │ 3,072 chips │
│ 12-way model │ │ 12-way model │
│ parallelism │ │ parallelism │
└──────────┬──────────┘ └──────────┬──────────┘
└──────────┬─────────────┘
│ 2-way pod-level data parallelism
│ (pipeline-free)
▼
6,144 TPU v4 total
46.2% MFU

PaLM uses a standard Transformer decoder-only architecture with several modifications optimized for training efficiency and quality at scale:
| Component | Detail |
|---|---|
| Parameters | 540B (also 8B and 62B variants) |
| Layers | 118 |
| Model dimension | 18,432 |
| Attention heads | 48 |
| Head dimension | 256 |
| Activation | SwiGLU (Swish-gated linear unit) |
| Position encoding | RoPE (Rotary Position Embeddings) |
| Attention variant | Multi-query attention (shared KV heads across all query heads) |
| Layer structure | Parallel formulation (attention and MLP computed simultaneously, then summed) |
| Biases | None in dense layers or layer norms |
| Vocabulary | SentencePiece, 256K tokens with lossless encoding |
| Sequence length | 2,048 tokens |
The parallel layer formulation computes attention and feedforward in parallel rather than sequentially:
y = x + Attention(LayerNorm(x)) + MLP(LayerNorm(x))
This provides ~15% faster training throughput compared to the standard sequential formulation, with no quality degradation at the 540B scale (though it slightly hurts smaller models).
Multi-query attention uses a single key-value head shared across all 48 query heads, reducing memory bandwidth during autoregressive inference while maintaining quality.
Training Infrastructure
The Pathways system enabled pipeline-free 2-way pod-level data parallelism across two TPU v4 pods (3,072 chips each), with each pod running 12-way model parallelism. Key efficiency metrics:
| Metric | PaLM 540B | GPT-3 175B | Gopher 280B |
|---|---|---|---|
| Hardware FLOPs Utilization (HFU) | 57.8% | — | — |
| Model FLOPs Utilization (MFU) | 46.2% | 21.3% | 32.5% |
| Training chips | 6,144 TPU v4 | 10,000 V100 | 4,096 TPU v3 |
Training Data
The model was trained on a 780B token multilingual corpus:
| Source | Proportion |
|---|---|
| Social media conversations | 50% |
| Filtered web pages | 27% |
| Books | 13% |
| GitHub code | 5% |
| Wikipedia | 4% |
| News | 1% |
Approximately 78% English, trained for exactly one epoch to avoid memorization effects. The optimizer was Adafactor with dynamic learning rate scheduling and gradient clipping.
Results
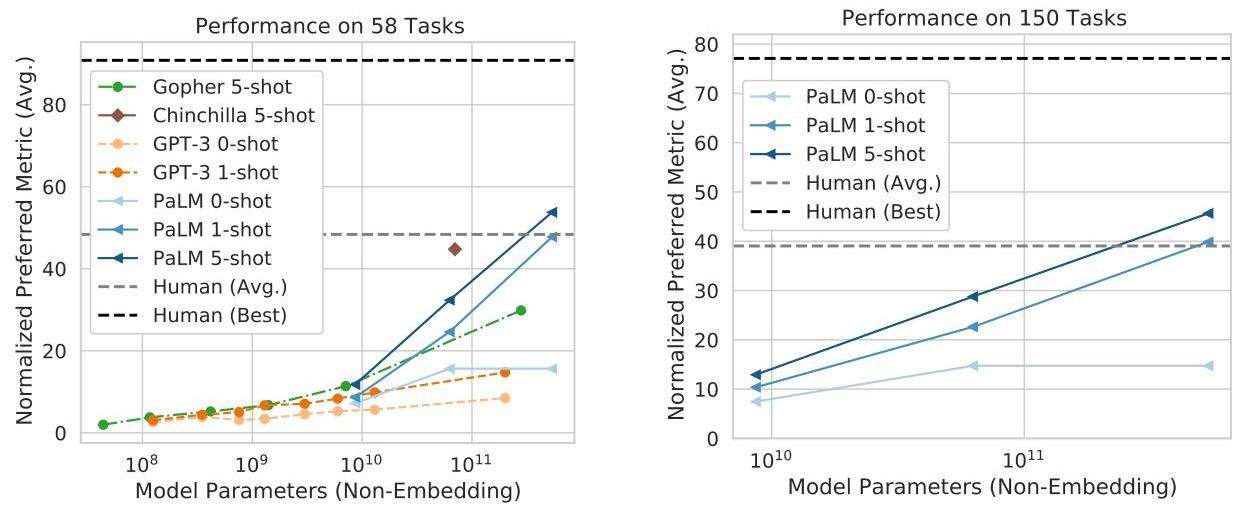
Few-shot NLP Benchmarks
PaLM 540B achieved SOTA on 28/29 English NLP benchmarks in few-shot evaluation. Key results:
| Benchmark | PaLM 540B | Previous SOTA | Setting |
|---|---|---|---|
| BIG-bench (avg over 58 tasks) | > human avg | Gopher, Chinchilla | few-shot |
| GSM8K (math reasoning + CoT) | 58.1% | 55% (fine-tuned verifier) | few-shot + CoT |
| HumanEval (code, pass@100) | 76.2% | Codex | few-shot |
| HumanEval (PaLM-Coder, pass@100) | 88.4% | — | fine-tuned |
Discontinuous Improvements
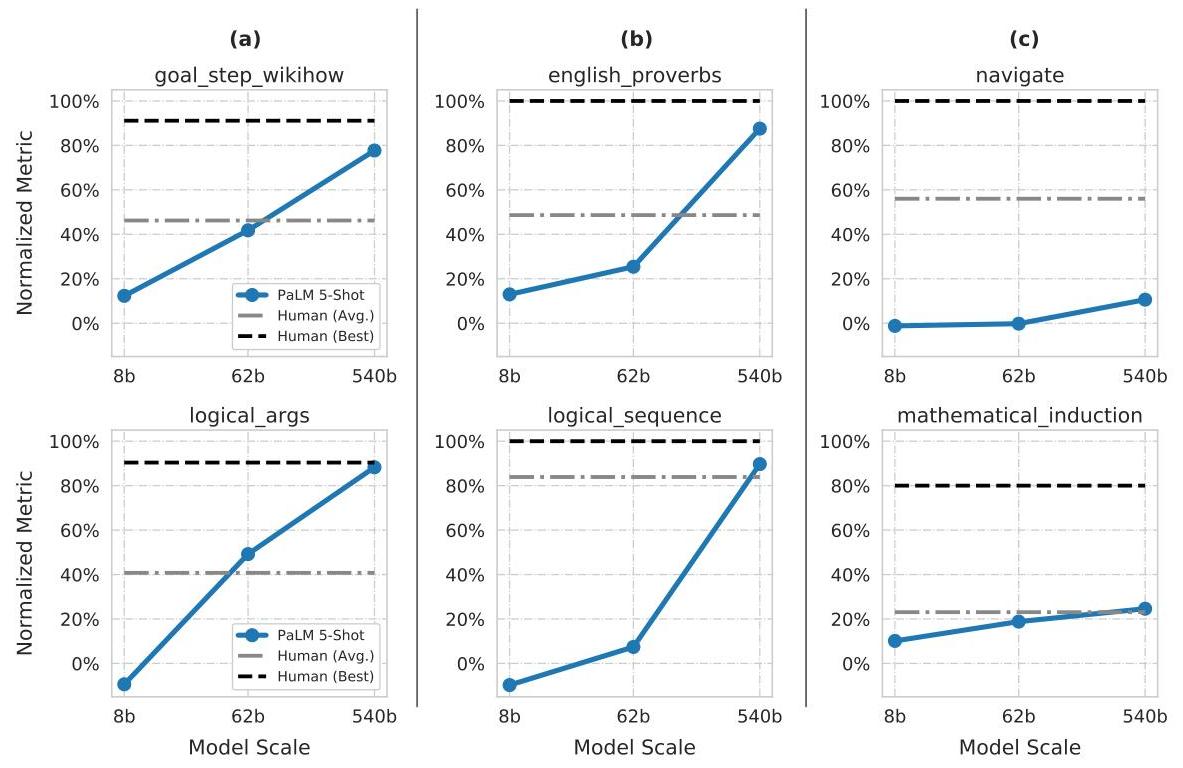
Approximately 25% of BIG-bench tasks showed "discontinuous" scaling behavior -- near-random performance at 8B and 62B, then sharp jumps to strong performance at 540B. This pattern was observed in tasks requiring multi-step reasoning, world knowledge, or compositional understanding, providing some of the earliest systematic evidence for emergent capabilities in LLMs.
Multilingual and Translation
Despite predominantly English training data, PaLM showed strong multilingual transfer. In few-shot translation, it outperformed prior LLMs and, for certain language pairs, even surpassed supervised baselines -- demonstrating cross-lingual generalization from scale alone.
Limitations & Open Questions
- Compute cost: Training PaLM 540B required approximately 2.56 × 10^24 FLOPs, making it one of the most expensive models at the time. Chinchilla's subsequent analysis suggested PaLM was undertrained relative to its parameter count.
- Bias and toxicity: PaLM exhibited persistent representational biases, particularly for non-stereotypical associations, and a "like-begets-like" toxicity pattern where output toxicity correlated with input toxicity. Scale improved some bias benchmarks (Winogender) but not all.
- Memorization at scale: Larger models showed higher rates of training data memorization, raising privacy concerns for deployment.
- Dense vs. sparse scaling: PaLM demonstrates the viability of dense scaling, but whether dense or sparse (MoE) architectures are more efficient at frontier scale remained an open question.
- Pathways generality: The Pathways infrastructure was a major enabler, but it was not publicly available, limiting reproducibility outside Google.
Connections
Related papers in the wiki:
- Attention Is All You Need — the Transformer architecture that PaLM builds on
- Language Models Are Few Shot Learners — GPT-3, the primary baseline PaLM surpasses on few-shot benchmarks
- Scaling Laws For Neural Language Models — the scaling laws that motivated training at 540B scale
- Training Compute Optimal Large Language Models — Chinchilla, published concurrently, which argued PaLM was undertrained for its size
- Chain Of Thought Prompting Elicits Reasoning In Large Language Models — the prompting technique that unlocked PaLM's strongest reasoning results
- Gpipe Easy Scaling With Micro Batch Pipeline Parallelism — the pipeline parallelism approach that Pathways explicitly avoided
- Bert Pre Training Of Deep Bidirectional Transformers For Language Understanding — bidirectional pretraining; PaLM uses decoder-only architecture instead
- Palm E An Embodied Multimodal Language Model — PaLM-E, which extends PaLM to embodied multimodal tasks
- Foundation Models — broader context on scaling and foundation model paradigm