Chain-of-Thought Prompting Elicits Reasoning in Large Language Models
Citation
Wei et al., arXiv 2201.11903, 2022 (NeurIPS 2022).
Canonical link
Overview
Chain-of-thought (CoT) prompting demonstrates that including intermediate reasoning steps in few-shot prompt exemplars dramatically improves large language model accuracy on arithmetic, commonsense, and symbolic reasoning tasks. The ability emerges only in models with 100B+ parameters, establishing it as an emergent capability tied to scale.
Chain-of-thought prompting revealed that LLMs possess latent multi-step reasoning capabilities that standard prompting fails to elicit. By simply changing the format of few-shot examples to include step-by-step reasoning, GSM8K accuracy jumped from 18% to 57% with PaLM 540B -- no retraining, no architectural changes, just a different prompt. This result reshaped how the field thinks about LLM capabilities: models may "know" more than they reveal under default prompting, and inference-time computation (generating more tokens of reasoning) can substitute for additional training.
CoT prompting became the foundation for subsequent techniques including self-consistency, tree-of-thought, and reasoning-focused training (e.g., OpenAI o1, DeepSeek R1). Its influence extends beyond language models to driving VLAs like AlphaDrive that use chain-of-thought reasoning to explain planning decisions.
Key Contributions
- Chain-of-thought as a prompting paradigm: Provide few-shot exemplars where each answer includes natural-language intermediate reasoning steps before the final answer; the model then imitates this format on new questions
- Emergent scaling behavior: CoT provides negligible benefit for models under ~10B parameters, modest benefit at 10-100B, and dramatic improvement at 100B+, establishing chain-of-thought as an emergent ability tied to model scale
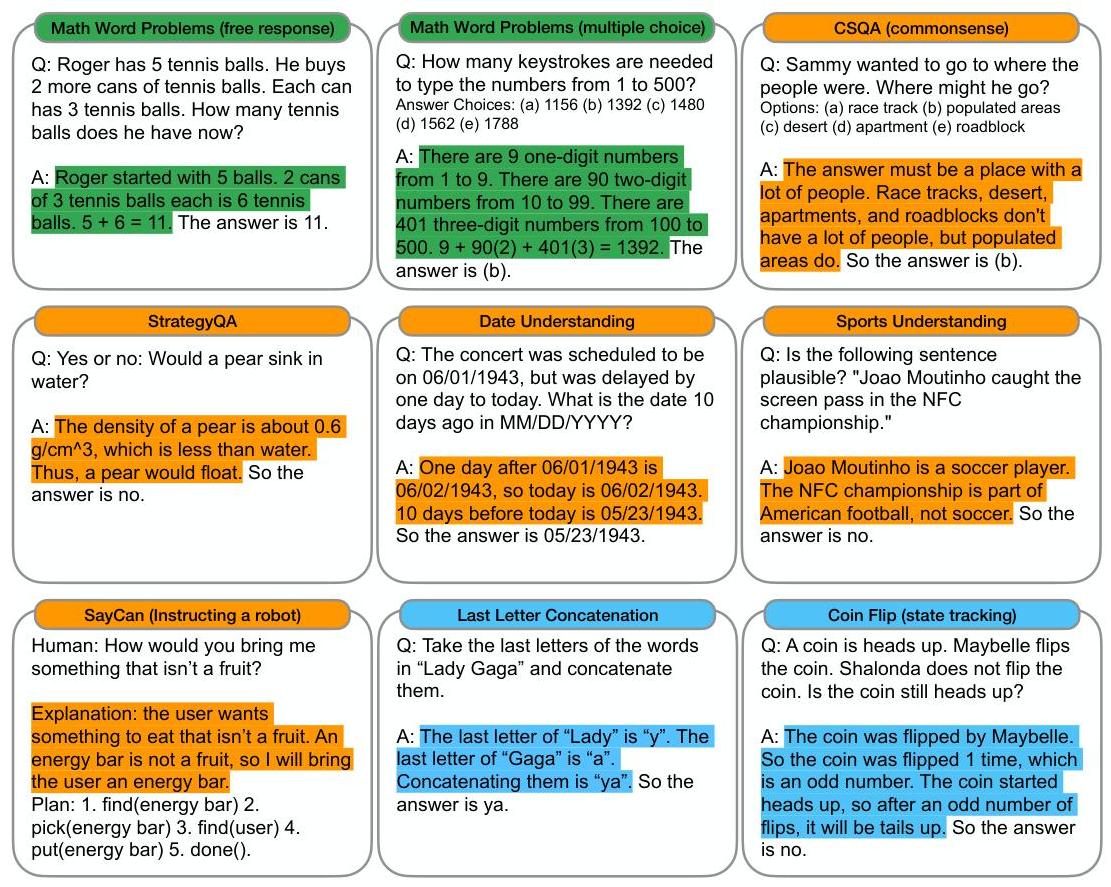
- Broad applicability across reasoning types: Evaluated on arithmetic (GSM8K, SVAMP, AQuA, MAWPS), commonsense (CommonsenseQA, StrategyQA), and symbolic reasoning (last letter concatenation, coin flip) with consistent gains
- Interpretable intermediate steps: Each reasoning step can be inspected for correctness, enabling error diagnosis -- a qualitative advantage over opaque direct-answer prompting
- Zero-shot CoT via "Let's think step by step": Concurrent work by Kojima et al. (not this paper) shows that simply appending "Let's think step by step" to a prompt triggers chain-of-thought reasoning without any exemplars; this paper focuses on few-shot CoT with manually crafted exemplars
Architecture / Method
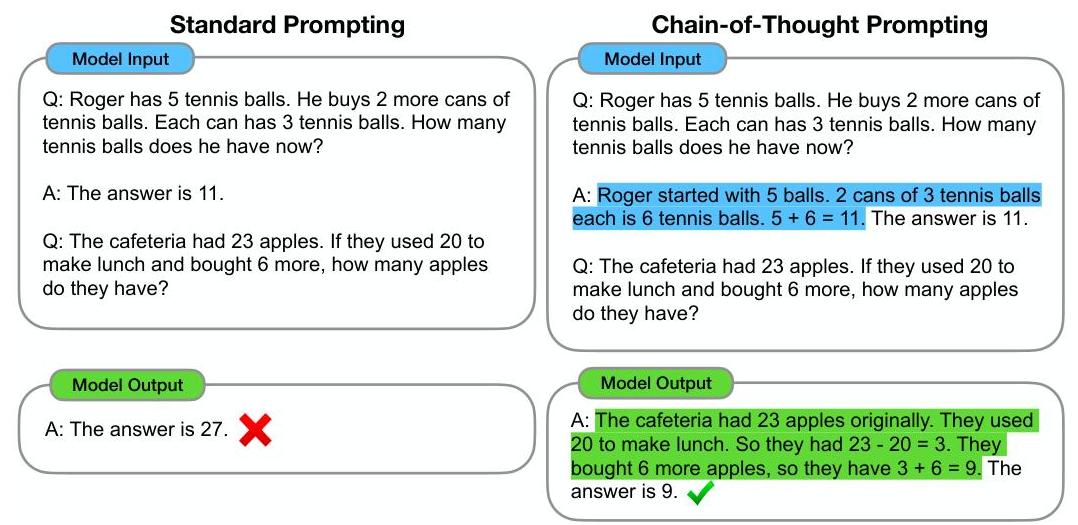
Standard Few-Shot Prompting:
┌───────────────────────────────────────┐
│ Prompt │
│ ┌───────────────────────────────────┐ │
│ │ Q: [example 1] A: [answer 1] │ │
│ │ Q: [example 2] A: [answer 2] │ │
│ │ ... │ │
│ │ Q: [test question] │ │
│ └───────────────┬───────────────────┘ │
└─────────────────┼─────────────────────┘
▼
┌──────────────┐
│ LLM (100B+)│──► A: [final answer]
└──────────────┘
Chain-of-Thought Prompting:
┌───────────────────────────────────────────────────┐
│ Prompt │
│ ┌───────────────────────────────────────────────┐ │
│ │ Q: [example 1] │ │
│ │ A: [step1] ─► [step2] ─► ... ─► [answer 1] │ │
│ │ Q: [example 2] │ │
│ │ A: [step1] ─► [step2] ─► ... ─► [answer 2] │ │
│ │ ... │ │
│ │ Q: [test question] │ │
│ └─────────────────────┬─────────────────────────┘ │
└───────────────────────┼───────────────────────────┘
▼
┌──────────────┐
│ LLM (100B+)│
└──────┬───────┘
▼
A: [step1] ─► [step2] ─► ... ─► [final answer]
▲ ▲
│ │
Interpretable Parsed for
reasoning chain evaluation
CoT prompting requires no architectural changes or retraining. The method modifies only the prompt format: instead of standard few-shot exemplars that show (question, answer) pairs, CoT exemplars show (question, reasoning_chain, answer) triples where the reasoning chain is a natural-language sequence of intermediate steps.
For arithmetic reasoning, a typical CoT exemplar might show: "Roger has 5 tennis balls. He buys 2 more cans of 3. How many does he have? Roger started with 5 balls. 2 cans of 3 is 6 balls. 5 + 6 = 11. The answer is 11." The model then generates similar step-by-step reasoning for new questions before outputting the final answer.
The authors manually wrote 8 CoT exemplars for each benchmark. At inference time, these exemplars are prepended to the test question, and the model generates a completion that includes both reasoning and answer. The final answer is extracted by parsing the text after "The answer is." No special decoding strategy is used -- standard greedy or sampling decoding works. The same approach extends to commonsense (reasoning about world knowledge) and symbolic reasoning (following algorithmic rules step by step).
Results
| Benchmark | Standard Prompting | CoT Prompting | Improvement |
|---|---|---|---|
| GSM8K | 17.9% | 56.9% | +39.0% |
| StrategyQA | 68.6% | 77.8% | +9.2% |
| Sports Understanding | 80.5% | 95.4% | +14.9% |
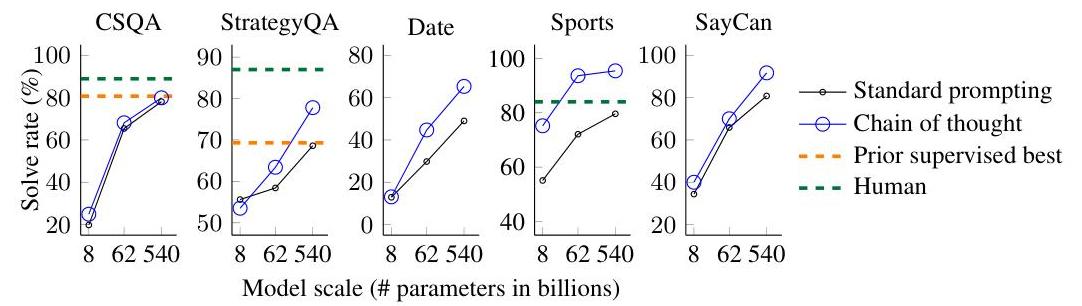
- CoT + PaLM 540B achieves 56.9% on GSM8K: Compared to 17.9% with standard few-shot prompting and 55% for the previous SOTA fine-tuned model, demonstrating that prompting alone can match task-specific training
- Performance gains scale with model size: On GSM8K, GPT-3 6.7B gains <1% from CoT, GPT-3 175B gains ~15%, and PaLM 540B gains ~39%, showing a clear emergent scaling curve
- Commonsense reasoning gains: StrategyQA improved from 68.6% to 77.8%; Sports Understanding reached 95.4% (vs. 80.5% baseline), exceeding human performance of 84%
- Symbolic reasoning generalization: CoT enabled length generalization beyond training examples -- models could solve problems with more steps than seen in few-shot exemplars
- CoT does not help on tasks without multi-step reasoning: On single-step tasks (e.g., sentiment classification), CoT provides no benefit or slight degradation, confirming the mechanism is specifically about decomposing multi-step problems
- Robustness across model families: Gains hold for PaLM, GPT-3, LaMDA, UL2 20B, and Codex, indicating the phenomenon is not architecture-specific. Different human annotators creating reasoning chains, various exemplar sets, and different orderings all maintained effectiveness
- New SOTA on multiple benchmarks: CoT + PaLM 540B achieves SOTA on GSM8K, SVAMP, and several other reasoning benchmarks at the time of publication
- Ablation insights: "Equation only" prompting (math without natural language reasoning) helped on simple arithmetic but not complex word problems; "variable compute only" (generating meaningless dots before answering) showed no improvement, proving the content of intermediate steps matters; placing reasoning after the answer performed no better than baseline, confirming sequential reasoning is essential
- Error analysis: Common error patterns include calculator errors in intermediate steps, symbol mapping errors, one-step-missing errors, and semantic understanding errors. Scaling from PaLM 62B to 540B fixed many semantic understanding and missing-step errors, providing qualitative evidence that larger models develop better reasoning capabilities
Limitations & Open Questions
- CoT requires very large models (100B+ parameters); smaller models produce incoherent or incorrect reasoning chains that hurt rather than help, limiting practical deployment
- The reasoning chains are not guaranteed to be faithful to the model's actual computation; the model may arrive at correct answers through different internal mechanisms than what the chain describes
- Prompt sensitivity: the specific choice and ordering of few-shot exemplars can significantly affect performance, and there is no principled method for selecting optimal CoT demonstrations