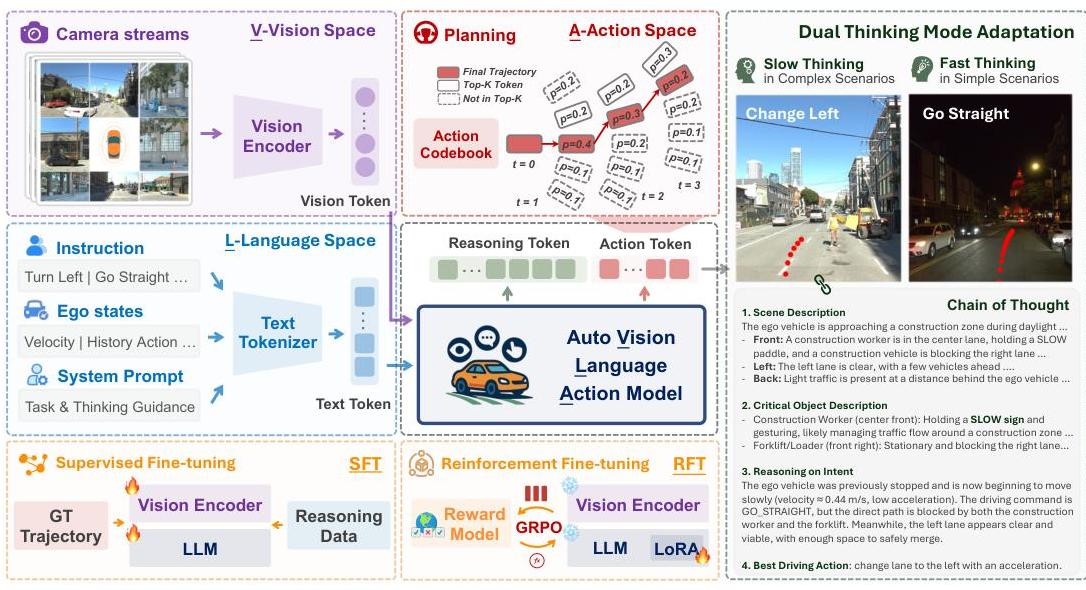
Overview
AutoVLA presents a unified approach to autonomous driving that integrates vision, language understanding, and action generation within a single autoregressive model. Developed at UCLA, the system addresses critical limitations in existing VLA models by introducing adaptive reasoning capabilities and direct physical action generation for end-to-end driving.
The core innovation is a dual-thinking adaptation mechanism inspired by cognitive science's dual-process theory. The model dynamically switches between fast thinking (direct action generation for straightforward scenarios like highway driving) and slow thinking (enhanced chain-of-thought reasoning for complex situations like construction zones or ambiguous traffic). This adaptive approach avoids unnecessary computational overhead in simple scenarios while providing detailed reasoning when the situation demands it.
AutoVLA builds upon the Qwen2.5-VL-3B vision-language model as its backbone, chosen to balance strong visual understanding with computational efficiency suitable for on-board deployment. The architecture introduces three key innovations: physical action tokenization that maps continuous driving actions into discrete tokens, unified reasoning and action generation within a single autoregressive framework, and RL fine-tuning (reinforcement learning) that pushes performance beyond the supervised learning ceiling.
Key Contributions
- Dual-process adaptive reasoning: Dynamic switching between fast (direct action) and slow (chain-of-thought) thinking modes based on scenario complexity
- Physical action tokenization: Continuous driving trajectories discretized into tokens within the VLM vocabulary for unified autoregressive generation
- Reinforcement fine-tuning: RL applied after supervised training to improve driving quality beyond the imitation ceiling
- Efficient backbone: Qwen2.5-VL-3B enables potential on-board deployment while retaining strong visual understanding
- Data scaling analysis: Demonstrates consistent improvement with reasoning-augmented training data
Architecture / Method
┌────────────────────────────────────────────────────────────┐
│ AutoVLA Architecture │
├────────────────────────────────────────────────────────────┤
│ │
│ Multi-Camera Images Navigation Instructions │
│ │ │ │
│ ▼ ▼ │
│ ┌────────────┐ ┌────────────┐ │
│ │ Qwen2.5-VL │ │ Text │ │
│ │ Vision Enc. │ │ Tokenizer │ │
│ └─────┬──────┘ └─────┬──────┘ │
│ │ │ │
│ └───────────┬───────────┘ │
│ ▼ │
│ ┌────────────────┐ │
│ │ Qwen2.5-VL-3B │ │
│ │ Backbone │ │
│ └───────┬────────┘ │
│ ▼ │
│ ┌────────────────┐ │
│ │ Dual-Process │ │
│ │ Thinking Mode │ │
│ └───┬────────┬───┘ │
│ Simple │ │ Complex │
│ ▼ ▼ │
│ ┌──────────┐ ┌──────────────┐ │
│ │ Fast │ │ Slow │ │
│ │ Thinking │ │ Thinking │ │
│ │ (direct) │ │ (CoT reason) │ │
│ └────┬─────┘ └──────┬───────┘ │
│ │ │ │
│ └───────┬───────┘ │
│ ▼ │
│ ┌────────────────┐ │
│ │ Action Tokens │ Continuous trajectory ──► │
│ │ (discretized) │ discrete VLM tokens │
│ └────────────────┘ │
│ │ │
│ ▼ │
│ ┌────────────────┐ │
│ │ RL Fine-Tuning │ (post-SFT refinement) │
│ └────────────────┘ │
└────────────────────────────────────────────────────────────┘
The architecture extends Qwen2.5-VL-3B with action tokenization and dual-process reasoning:
- Visual encoding: Multi-camera images are processed through the Qwen2.5 vision encoder
- Language conditioning: Navigation instructions and optional reasoning prompts are encoded as text tokens
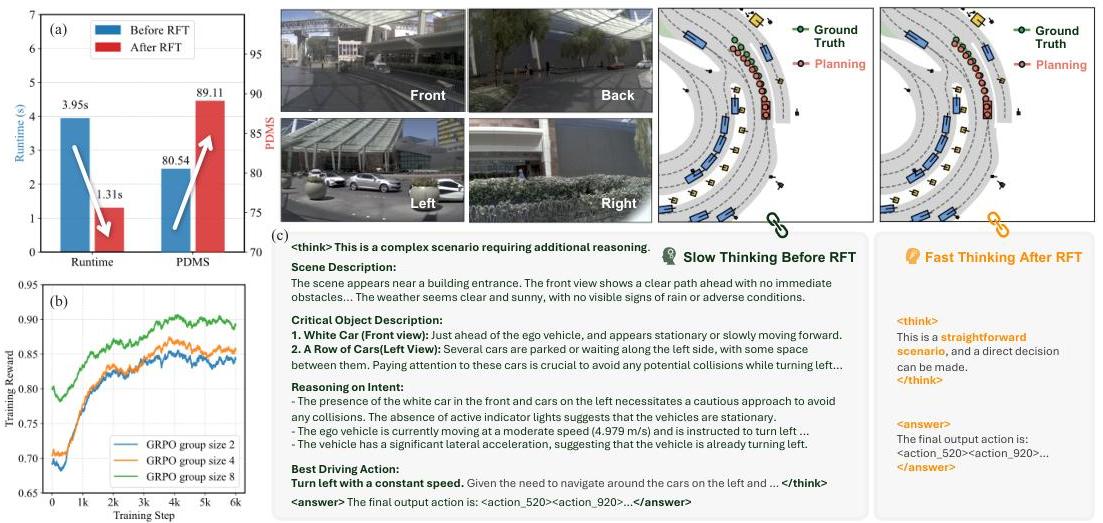
- Dual-process thinking: The model supports both slow thinking (chain-of-thought) and fast thinking (direct action) modes, trained via SFT on both modes and refined by GRPO to reduce unnecessary reasoning in straightforward scenarios
- Action generation: Physical actions are tokenized and generated autoregressively alongside language tokens
- RL fine-tuning: After SFT, Group Relative Policy Optimization (GRPO) refines the policy using a reward combining driving quality (PDMS for nuPlan, ADE for Waymo) minus a CoT length penalty to discourage unnecessary reasoning
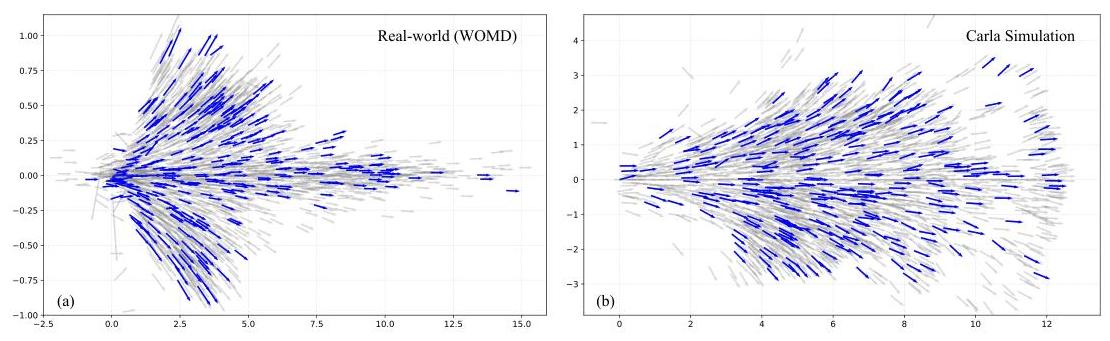
The action tokenization maps continuous trajectory waypoints into discrete tokens compatible with the VLM vocabulary. Each token represents short-term spatial position and heading movements (delta-x, delta-y, delta-theta) over 0.5-second intervals, drawn from a codebook of 2,048 tokens built via K-disk clustering on real-world and simulation data. This enables the model to generate both reasoning text and driving actions within the same autoregressive framework.
Results
| Feature | AutoVLA |
|---|---|
| Backbone | Qwen2.5-VL-3B |
| Reasoning | Adaptive dual-process (fast/slow) |
| Action space | Tokenized trajectories |
| Training | SFT + RL fine-tuning |
| Evaluation | Closed-loop |
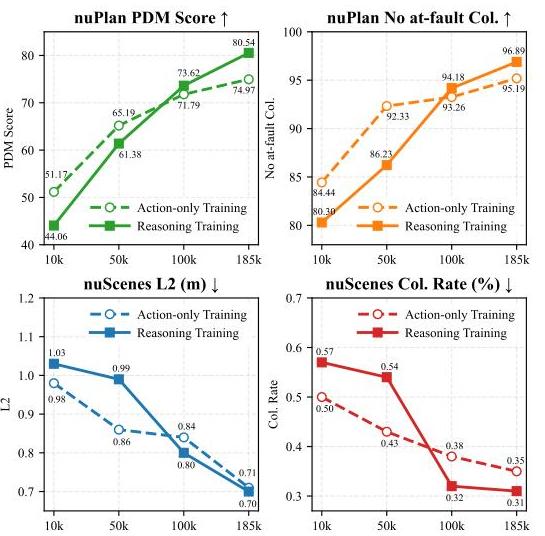
The data scaling analysis shows consistent improvements as reasoning-augmented training data increases, suggesting the approach has not yet saturated.

In complex scenarios (construction zones, multiple moving objects), AutoVLA engages detailed chain-of-thought reasoning. In straightforward scenarios (highway driving, clear intersections), it generates direct actions efficiently.
Limitations & Open Questions
- The 3B parameter model, while more efficient than larger VLAs, still faces latency challenges for real-time deployment at full reasoning depth
- The dual-process routing mechanism's robustness to adversarial or truly novel scenarios (where slow thinking should always be engaged) is not fully characterized
- Evaluation is primarily in simulation; real-world deployment validation is needed
Connections
- Alphadrive Unleashing The Power Of Vlms In Autonomous Driving -- AlphaDrive similarly applies RL (GRPO) to driving VLMs; AutoVLA uses RL fine-tuning with adaptive reasoning
- Emma End To End Multimodal Model For Autonomous Driving -- EMMA pioneered everything-as-tokens for driving; AutoVLA extends this with adaptive reasoning and RL
- Senna Bridging Large Vision Language Models And End To End Autonomous Driving -- Contrasting architecture: Senna decouples reasoning from planning, AutoVLA unifies them
- Alpamayo R1 Bridging Reasoning And Action Prediction For Autonomous Driving -- Both combine reasoning with RL; Alpamayo-R1 focuses on production latency, AutoVLA on adaptive reasoning depth
- Chain Of Thought Prompting Elicits Reasoning In Large Language Models -- Chain-of-thought reasoning foundations that AutoVLA applies adaptively to driving
- Vision Language Action -- Adds dual-process reasoning as a new design axis for driving VLAs
- End To End Architectures -- Type 4 VLA system with adaptive computation
- Planning -- RL fine-tuning to push planning beyond imitation ceiling