AlphaDrive: Unleashing the Power of VLMs in Autonomous Driving via Reinforcement Learning and Reasoning
Citation
Bo Jiang, Shaoyu Chen, Qian Zhang, Wenyu Liu, Xinggang Wang, arXiv, 2025.
Overview
AlphaDrive is the first application of GRPO (Group Relative Policy Optimization) reinforcement learning to driving VLMs, using four domain-specific reward functions to develop emergent multimodal planning reasoning beyond what supervised fine-tuning alone can teach. Inspired by reasoning-enhanced LLMs like DeepSeek R1 and OpenAI o1, AlphaDrive applies RL to make driving VLMs "think before they act."
Supervised fine-tuning of VLMs for driving teaches the model to imitate expert behavior but does not develop reasoning about why certain actions are correct. The GRPO approach generates multiple trajectory candidates, scores them with driving-specific rewards (planning accuracy, action-weighted safety, planning diversity, planning format), and uses relative rankings for policy improvement -- no separate reward model needed. The result is emergent multimodal planning capabilities: reasoning patterns that are not present in the supervised training data but emerge from RL optimization.
From the same team as Senna, AlphaDrive represents the RL enhancement of the decoupled VLA paradigm. It demonstrates that the reasoning-via-RL approach that proved transformative for language models also applies to embodied driving agents, opening a new direction for driving VLA research beyond pure imitation learning.
Key Contributions
- First GRPO-based RL for driving VLMs: Adapts the Group Relative Policy Optimization technique from language model reasoning (DeepSeek R1) to autonomous driving planning
- Four domain-specific reward functions: (1) planning accuracy (F1-score alignment with ground truth actions), (2) action-weighted reward (higher weight for safety-critical ops like braking/steering), (3) planning diversity (encourages multiple viable strategies to avoid mode collapse), (4) planning format (structured, consistent output formatting)
- Two-stage training: SFT stage for basic driving competence from expert data, then RL stage with GRPO rewards for planning reasoning refinement
- Emergent multimodal planning capabilities: RL discovers reasoning patterns not present in training data, developing novel planning strategies beyond imitation
- No separate reward model required: GRPO uses group relative rankings, avoiding the need for a trained reward model (unlike PPO/RLHF)
Architecture / Method
┌──────────────────────────────────────────────────────────────────┐
│ AlphaDrive Training Pipeline │
├──────────────────────────────────────────────────────────────────┤
│ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Stage 1: Supervised Fine-Tuning (SFT) │ │
│ │ │ │
│ │ Multi-Camera Images ──► VLM ──► CoT Reasoning │ │
│ │ + Expert Demos (GPT-4o) + Trajectory Tokens │ │
│ │ │ │
│ │ Loss: Next-token prediction on reasoning + trajectory │ │
│ └────────────────────────────┬────────────────────────────┘ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────────┐ │
│ │ Stage 2: RL with GRPO │ │
│ │ │ │
│ │ For each scenario, generate K candidates: │ │
│ │ ┌─────┐ ┌─────┐ ┌─────┐ ┌─────┐ │ │
│ │ │ c_1 │ │ c_2 │ │ c_3 │ . . . │ c_K │ │ │
│ │ └──┬──┘ └──┬──┘ └──┬──┘ └──┬──┘ │ │
│ │ └───────┴───────┴─────┬───────┘ │ │
│ │ ▼ │ │
│ │ ┌─────────────────────────────────────────────────┐ │ │
│ │ │ 4 Reward Functions: │ │ │
│ │ │ R1: Planning Accuracy (L2 to expert) │ │ │
│ │ │ R2: Action-Weighted (safety-critical ops) │ │ │
│ │ │ R3: Planning Diversity (multiple strategies) │ │ │
│ │ │ R4: Format Reward (structured output) │ │ │
│ │ └──────────────────────┬──────────────────────────┘ │ │
│ │ ▼ │ │
│ │ Group Relative Policy Optimization │ │
│ │ (rank candidates, update policy) │ │
│ └─────────────────────────────────────────────────────────┘ │
└──────────────────────────────────────────────────────────────────┘

AlphaDrive follows a two-stage training pipeline. In Stage 1 (SFT), a VLM is fine-tuned on expert driving demonstrations to develop basic driving competence. The model learns to process multi-camera driving images, generate chain-of-thought reasoning about the scene, and predict trajectory waypoints. This stage uses standard supervised fine-tuning with next-token prediction loss on both reasoning text and trajectory tokens.
In Stage 1, advanced models (like GPT-4o) generate high-quality planning reasoning from real driving data, providing the SFT warm-up dataset. This minimizes hallucinations and early RL instability, providing stronger RL foundations.
In Stage 2 (RL), GRPO is applied to refine the model's planning capabilities. For each driving scenario, the model generates a group of K candidate outputs (each containing reasoning text + trajectory). Each candidate is scored by four specialized planning reward functions: (1) Planning Accuracy Reward aligns model actions with ground truth data; (2) Action-Weighted Reward prioritizes safety-critical operations like braking and steering; (3) Planning Diversity Reward generates multiple viable driving strategies; (4) Planning Format Reward ensures structured, consistent output formatting. The final reward is a weighted combination of all four.
GRPO computes advantages relative to the group mean reward (rather than against a learned value function as in PPO), then updates the policy to increase the probability of higher-reward candidates and decrease lower-reward ones. This avoids training a separate critic network, simplifying the RL pipeline while maintaining effective policy improvement.
Results
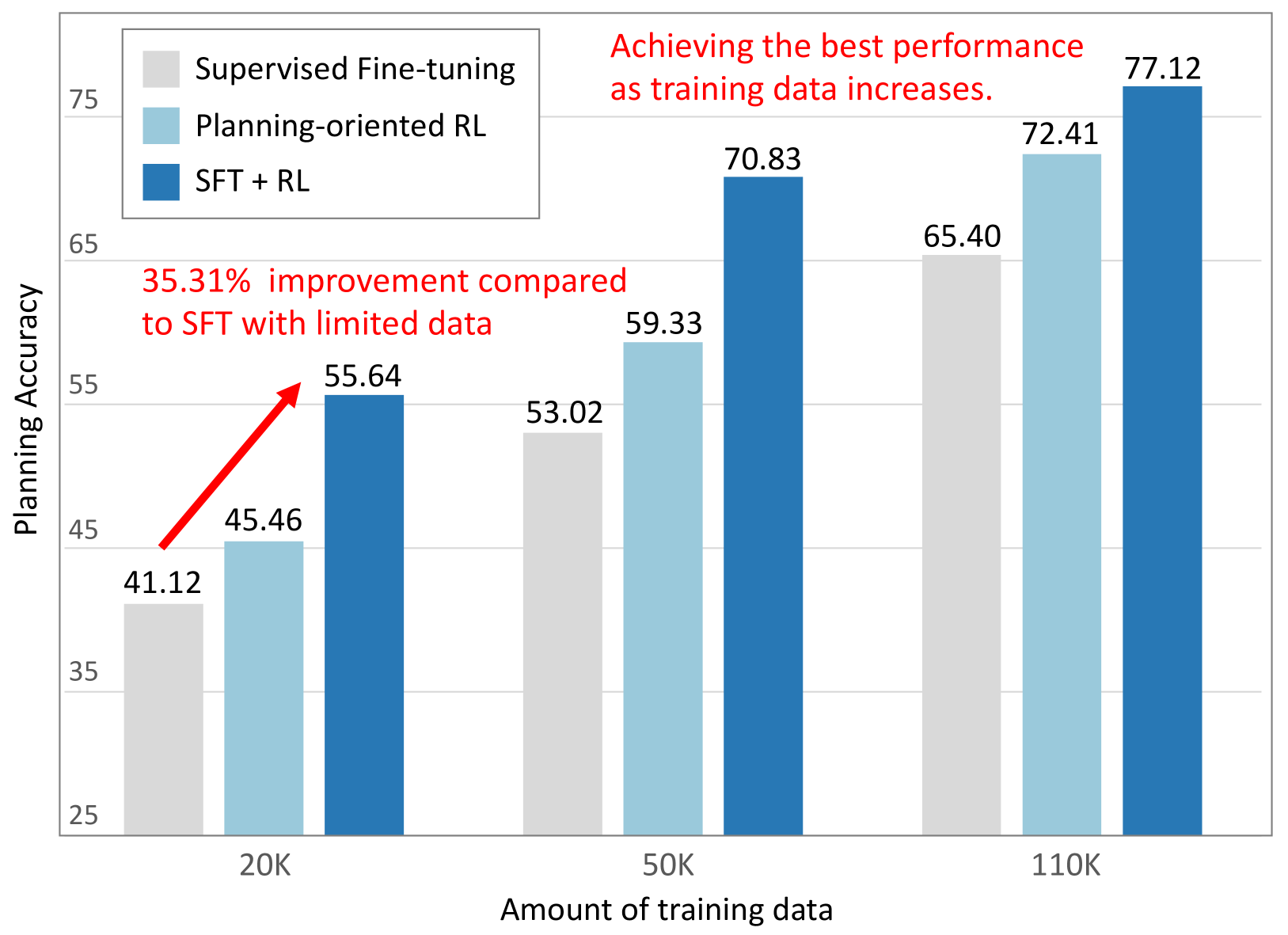

- Planning accuracy: AlphaDrive significantly outperforms SFT-only models, achieving up to 25.5% higher planning accuracy on the MetaAD dataset
- Data efficiency: With merely 20K training samples (~18% of total), AlphaDrive achieves 35.31% better planning accuracy than the SFT-only model, demonstrating remarkable sample efficiency
- Emergent multimodal planning capabilities: Following RL training, the model develops the ability to generate multiple reasonable driving plans per scenario (e.g., truck ahead: either stop or decelerate/change lanes; pedestrians present: either stop or careful left turn), a capability absent in SFT-trained models that generate single responses
- Reward validation: Ablation studies confirm each reward contributes positively; SFT warm-up plus RL exploration consistently outperforms isolated approaches
- Reasoning impact: Models incorporating reasoning demonstrate substantially better performance than those without
- Enhanced driving safety through reasoning-aware RL: Explicit safety rewards and multimodal planning (evaluating multiple options) improve safety and adaptability over imitation alone
- GRPO is effective for driving-domain RL: The group relative policy optimization framework transfers successfully from language reasoning to driving planning
Limitations & Open Questions
- RL training stage adds significant computational cost and complexity on top of SFT
- The quality and design of the four reward functions critically determines what the model learns -- reward engineering is a key challenge
- Emergent reasoning patterns may be difficult to interpret or verify for safety guarantees
- Evaluation details and benchmark comparisons are limited in the current arXiv version