Self-Improving Embodied Foundation Models
Overview
This Google DeepMind paper addresses a fundamental limitation of Embodied Foundation Models (EFMs): while they demonstrate impressive semantic generalization (understanding what tasks to perform), they typically struggle with behavioral generalization (learning entirely new ways to act). Drawing inspiration from the three-stage LLM training pipeline -- pretraining, supervised fine-tuning, and reinforcement learning -- the authors observe that current EFMs have focused primarily on the first two stages, missing the crucial RL component that has proven transformative for language models.
The paper proposes a two-stage post-training framework. Stage 1 performs supervised fine-tuning on robot demonstration data using standard behavioral cloning plus a novel "steps-to-go" prediction task that trains the model to estimate how many timesteps remain until goal completion. Stage 2 introduces Self-Improvement, where robots practice tasks autonomously using a data-driven reward function derived from the learned steps-to-go predictions -- eliminating the need for manual reward engineering.
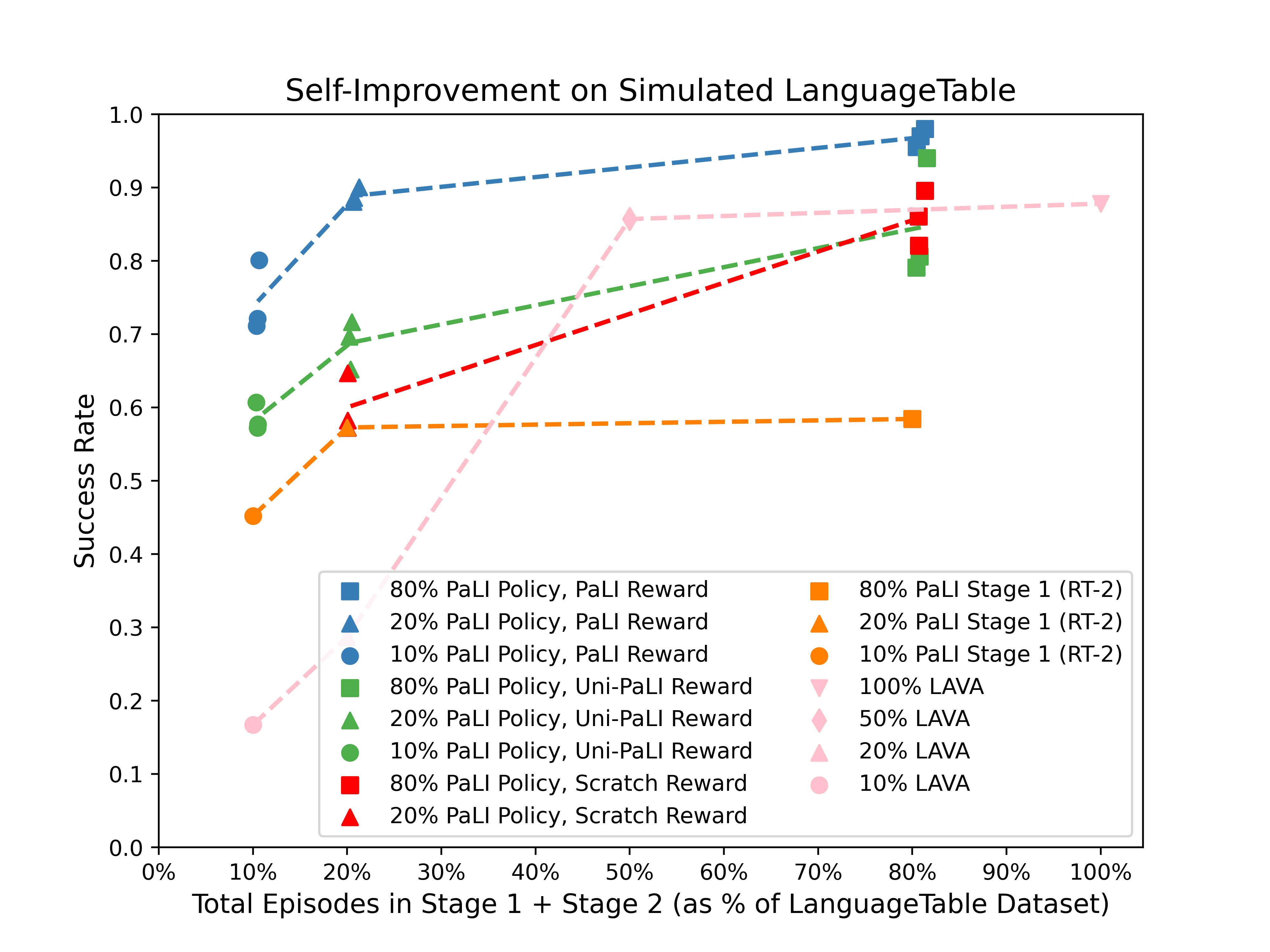
The results are remarkable: policies trained with just 10% of the imitation dataset plus 1% additional robot interaction through Self-Improvement outperform behavioral cloning policies trained on 20-80% of the full dataset. Most significantly, robots achieve true behavioral generalization, learning to manipulate novel objects (bananas) never seen in training data by discovering effective strategies autonomously. This establishes a clear path toward adaptive robots that continuously improve with minimal human intervention.
Key Contributions
- Two-stage post-training framework: Extends EFM training beyond behavioral cloning with a self-improvement stage using autonomous RL, mirroring the proven LLM training pipeline
- Steps-to-go reward function: Derives dense, shaped rewards from the model's own learned distance-to-goal predictions, eliminating manual reward engineering:
r(o_t, a_t, o_{t+1}, g) = d(o_t, g) - d(o_{t+1}, g) - Dramatic sample efficiency: 10% imitation data + 1% autonomous practice outperforms 20-80% imitation data alone, demonstrating that small amounts of RL practice yield outsized improvements
- Behavioral generalization: Robots learn entirely new manipulation strategies for novel objects (bananas) not present in training data, discovering effective approaches like pushing from tips to prevent rotation
- Foundation model pretraining is critical: Ablation shows models initialized from scratch or with unimodal pretraining fail at self-improvement; multimodal foundation model knowledge is essential
Architecture / Method
┌─────────────────────────────────────────────────────────────┐
│ Self-Improving Embodied Foundation Model │
│ (PaLI-3B backbone) │
├─────────────────────────────────────────────────────────────┤
│ │
│ Stage 1: Supervised Fine-Tuning │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ ┌─────────────┐ ┌──────────────────────────────┐ │ │
│ │ │ Robot Demos │──►│ PaLI-3B Foundation Model │ │ │
│ │ │ (obs, goal) │ │ │ │ │
│ │ └─────────────┘ │ Loss 1: Behavioral Cloning │ │ │
│ │ │ Loss 2: Steps-to-Go d(o,g) │ │ │
│ │ └──────────────────────────────┘ │ │
│ └──────────────────────────────────────────────────────┘ │
│ │ │
│ ▼ │
│ Stage 2: Self-Improvement (Autonomous RL) │
│ ┌──────────────────────────────────────────────────────┐ │
│ │ │ │
│ │ ┌────────┐ act ┌────────────┐ observe │ │
│ │ │ Policy │──────►│ Environment │──────┐ │ │
│ │ │(PaLI-3B│◄──────│ │ │ │ │
│ │ └────────┘reward └────────────┘ │ │ │
│ │ ▲ │ │ │
│ │ │ ▼ │ │
│ │ ┌────┴──────────────────────────────────────┐ │ │
│ │ │ Reward: r = d(o_t, g) - d(o_{t+1}, g) │ │ │
│ │ │ (decrease in predicted steps-to-go) │ │ │
│ │ │ No manual reward engineering needed │ │ │
│ │ └───────────────────────────────────────────┘ │ │
│ └──────────────────────────────────────────────────────┘ │
│ │
│ Result: 10% BC data + 1% RL practice > 80% BC data alone │
└─────────────────────────────────────────────────────────────┘
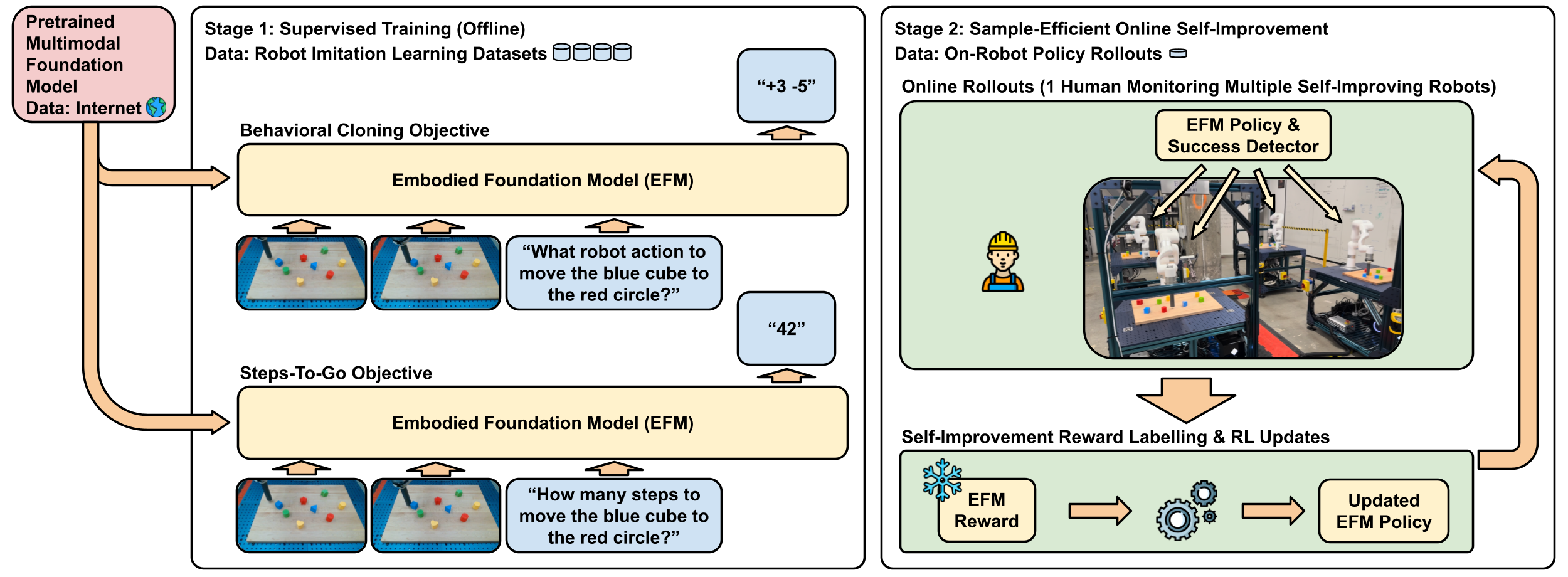
The framework builds on PaLI-3B as the foundation model backbone.
Stage 1 -- Supervised Fine-Tuning: The model is fine-tuned on robot demonstrations with two objectives: (1) standard behavioral cloning loss predicting actions from observations and goals, and (2) a steps-to-go prediction loss training the model to estimate remaining timesteps to goal completion. The steps-to-go objective creates an internal distance metric that the model can later use for reward generation.
Stage 2 -- Self-Improvement: The robot practices tasks autonomously. At each timestep, the reward is computed as the decrease in predicted steps-to-go: r = d(o_t, g) - d(o_{t+1}, g). This reward is dense (available at every timestep), shaped (provides gradient signal throughout the trajectory), and requires no manual engineering. Success detection also derives from the steps-to-go predictions, enabling fully autonomous practice sessions.
The RL training uses standard policy gradient methods on top of the foundation model, with the key insight that the pretrained representations provide a stable foundation for RL that prevents catastrophic forgetting of semantic knowledge while enabling behavioral adaptation.

Results
| Domain | Metric | Before Self-Improvement | After Self-Improvement |
|---|---|---|---|
| LanguageTable (sim) | Equivalent data | 10% BC data | Outperforms 80% BC data |
| LanguageTable (real) | Success rate | 62-63% | 87-88% |
| BananaTable (novel objects) | Success rate | ~63% | ~85% |
| Aloha (bimanual) | Insertion success | Baseline BC | Improved with RL |
In simulation, 10% imitation data + 1% autonomous interaction outperforms 20% and even 80% imitation-only baselines, demonstrating a roughly 2-8x reduction in required imitation data rather than scaling demonstrations alone. Real-world LanguageTable experiments show success rates improving from ~62% to ~88%. The BananaTable experiment demonstrates behavioral generalization: robots trained only on geometric blocks learn to manipulate bananas, discovering effective strategies never shown in demonstrations.

Limitations & Open Questions
- Foundation model dependency: The approach critically requires multimodal foundation model pretraining; it does not work from scratch or with unimodal pretraining, limiting applicability to groups with access to large pretrained models
- Task scope: Validated primarily on tabletop manipulation and insertion tasks; scaling to more complex, longer-horizon tasks (like driving) remains open
- Safety during practice: Autonomous self-improvement requires the robot to explore, which may be unsafe in uncontrolled environments or safety-critical domains like driving
Connections
- Extends the VLA paradigm from Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control (RT-2) with a self-improvement stage, completing the LLM training pipeline analogy
- Builds on Palm E An Embodied Multimodal Language Model (PaLM-E) foundation model approach for robotics
- The steps-to-go reward relates to goal-conditioned RL and hindsight experience replay literature
- Relevant to the RL-for-driving trend seen in Alphadrive Unleashing The Power Of Vlms In Autonomous Driving (AlphaDrive), which applies GRPO to driving VLMs
- Democratization potential connects to Openvla An Open Source Vision Language Action Model (OpenVLA) open-source VLA efforts