A Generalist Agent
Citation
Reed et al., Transactions on Machine Learning Research (TMLR), 2022.
Canonical link
Overview
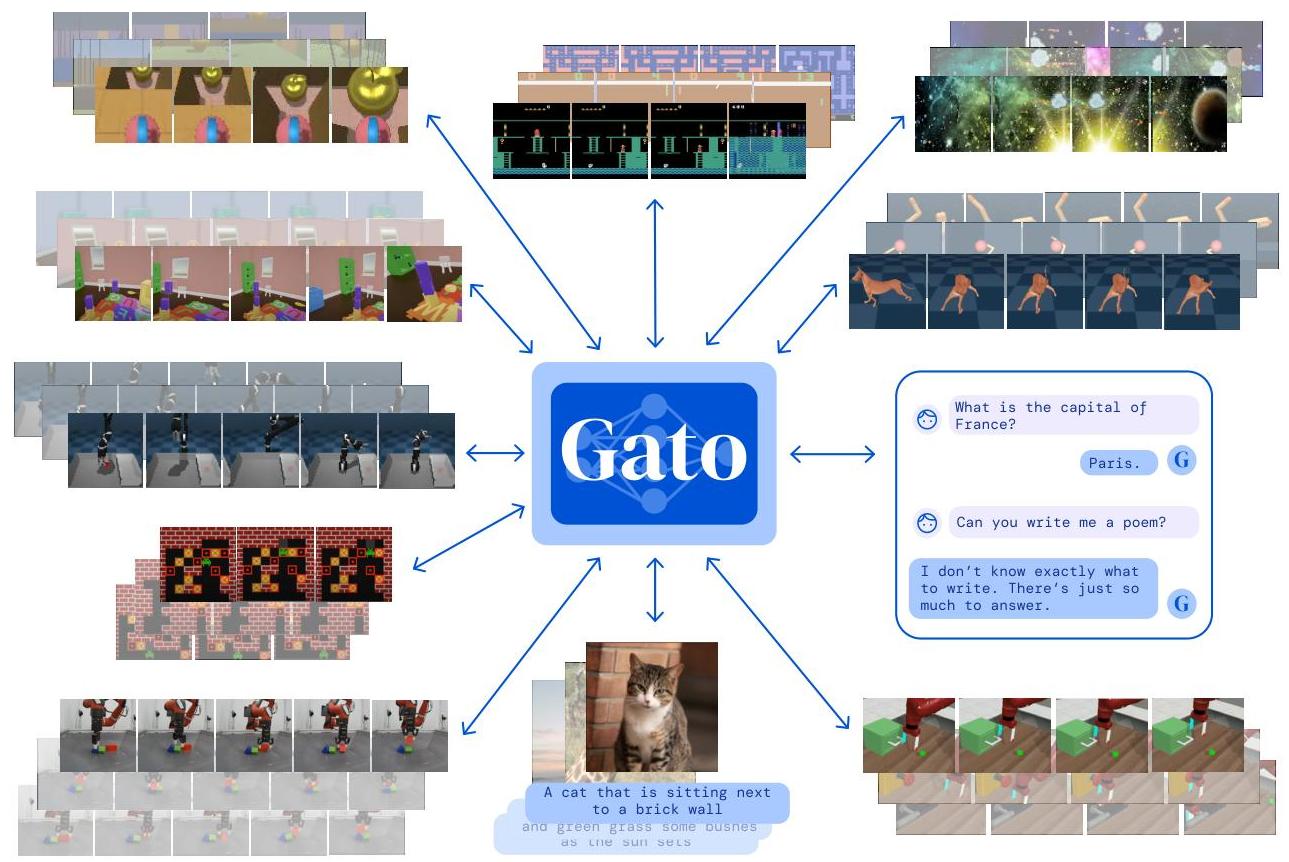
Gato, developed by DeepMind, is a single transformer-based agent capable of performing 604 distinct simulated control tasks (plus language and vision tasks) spanning text generation, image captioning, playing 51 Atari games, stacking blocks with a real robot arm, and navigating in 3D environments. Rather than training separate specialist models for each domain, Gato serializes all inputs and outputs -- text tokens, image patches, continuous control actions, button presses -- into a single flat sequence of tokens, then trains a single decoder-only transformer to predict the next token across all tasks simultaneously.
The core insight is that if you tokenize everything uniformly (text via SentencePiece, images via 16x16 patches mapped to 1024 discrete bins, continuous values via mu-law encoding into 1024 bins, and discrete actions directly), then a standard autoregressive transformer can serve as a generalist policy. Gato uses a 1.2B parameter transformer with 24 layers, 16 heads, and an embedding dimension of 2048. It processes up to 1024 tokens per context window. The model is trained on a large offline dataset of expert demonstrations and text corpora, with no online RL fine-tuning.
Gato matters as the cleanest early demonstration that a single set of weights can function as a generalist agent across perception, language, and embodied control. While specialist models outperform Gato on most individual tasks, the paper showed that multi-task generalization across fundamentally different modalities is feasible with a unified architecture. This work is a direct conceptual precursor to the Vision-Language-Action (VLA) paradigm that later became dominant in robotics and autonomous driving.
Key Contributions
- Universal tokenization scheme: A single method to serialize text, images, continuous actions, and discrete actions into a flat token sequence, enabling a single model to process all modalities
- Single-model multi-domain agent: Demonstrated that one 1.2B parameter transformer can play Atari (51 games), control a Sawyer robot arm for block stacking, caption images, and chat -- all with the same weights
- Prompted in-context task specification: At inference time, the desired task is specified by prepending a prompt of expert demonstrations (for control tasks) or text context (for language tasks), requiring no task-specific heads or fine-tuning
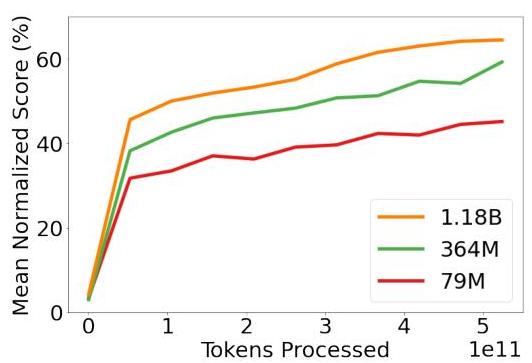
- Scaling analysis across domains: Showed that scaling model size from 79M to 1.2B parameters consistently improves performance across domains, with larger models achieving above 50% expert score on more than 450 of 604 total simulated control tasks
- Real-robot transfer: Gato controls a physical Sawyer robot for block stacking using the same weights used for Atari and language, demonstrating sim-to-real transfer within a generalist framework
Architecture / Method
┌───────────────────────────────────────────────────────────────┐
│ Gato: Universal Tokenization │
├───────────────────────────────────────────────────────────────┤
│ │
│ Text ──► SentencePiece (32K vocab) ──┐ │
│ │ │
│ Image ──► 16x16 patches ──► Linear ──┤ │
│ Projection + ResNet Embed │ │
│ ├──► Flat Token │
│ Continuous ──► mu-law encoding ──────┤ Sequence │
│ (1024 bins) │ │ │
│ │ ▼ │
│ Discrete ──► Direct embedding ───────┘ ┌──────────────┐ │
│ │ Decoder-Only │ │
│ │ Transformer │ │
│ ┌─────────────────────────────────┐ │ 24 layers │ │
│ │ Prompt: Expert Demo Tokens │────►│ 16 heads │ │
│ │ (task specification) │ │ d=2048 │ │
│ └─────────────────────────────────┘ │ 1.2B params │ │
│ └──────┬───────┘ │
│ │ │
│ ┌────────┬──────────┼──────────┐ │
│ ▼ ▼ ▼ ▼ │
│ Text Caption Action Button │
│ Token Token Token Press │
└───────────────────────────────────────────────────────────────┘
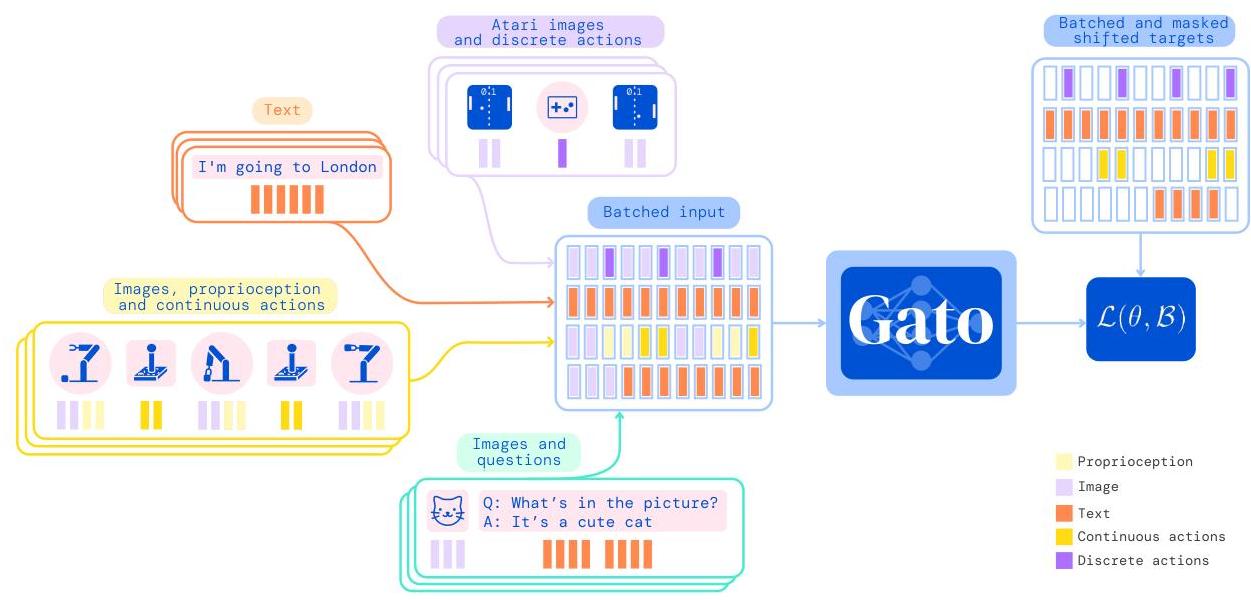
Gato's architecture is a decoder-only transformer with 24 layers, 16 attention heads, and d_model=2048 (1.2B parameters total). All inputs are converted to tokens: text uses SentencePiece (32,000 vocab), images are divided into 16x16 patches and each patch is flattened and linearly projected, continuous values are discretized into 1024 bins via mu-law encoding, and discrete actions are embedded directly. Each token receives a learned embedding plus a learned position encoding. For image tokens, an additional ResNet-style embedding encodes the patch position within the image grid.
Training uses a standard next-token prediction objective (cross-entropy loss) across all tasks simultaneously on approximately 1.5 trillion tokens. The training dataset is a mixture of: (1) large text corpora, (2) vision-language datasets (image captioning, VQA), (3) 604 simulated control tasks (DM Control Suite, Atari, DM Lab), (4) real-world robotics demonstrations, and (5) vision-language data. Data mixing ratios are tuned per domain. The model is trained for approximately 1M gradient steps with batch size 512.
At inference time for control tasks, the model receives a prompt consisting of a few expert trajectory segments (observation-action sequences), followed by the current observation. It then autoregressively generates the next action tokens. For language tasks, standard text prompting is used. No task ID or task-specific head is needed -- the prompt implicitly specifies the task.
Results
- Atari: Gato achieves human-level or better performance on 23 of the 51 Atari games it was trained on, and more than double human scores on 11 games. Across all 604 simulated control tasks, Gato achieves above 50% expert score on more than 450 tasks
- DM Control Suite: Competitive with specialist agents on continuous control tasks including cartpole, cheetah run, and walker, though not surpassing state-of-the-art RL agents
- Real robot block stacking: Successfully stacks blocks with a physical Sawyer arm, achieving a 50.2% success rate on unseen object shapes, comparable to specialist behavioral cloning baselines
- Image captioning: Produces reasonable captions on MS-COCO, though below specialist captioning models (CIDEr score not SOTA)
- Dialogue: Generates coherent conversational responses, though not matching dedicated language models of similar scale
- Scaling: Performance improves consistently from 79M to 364M to 1.2B parameters across all domains, with no sign of negative transfer between domains
Limitations & Open Questions
- Gato underperforms domain-specific specialists on most individual tasks -- the generalist tax is real, and it remains unclear how to close this gap without losing generality
- The model relies entirely on offline expert data with no online RL; it cannot improve beyond its training demonstrations, limiting its ability to discover novel strategies
- Context window of 1024 tokens is restrictive for long-horizon control tasks and limits the amount of in-context demonstration that can be provided