VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models
Overview
VoxPoser addresses a fundamental bottleneck in robot manipulation: translating open-ended natural language instructions into precise physical actions without requiring task-specific training data or predefined skill libraries. Prior approaches either rely on a fixed set of manipulation primitives (limiting generalization) or require expensive per-task demonstrations (limiting scalability). VoxPoser proposes an elegant alternative -- use LLMs to compose dense 3D value maps that directly define spatial objectives for motion planning.
The core insight is that LLMs, when prompted to generate Python code, can dynamically create voxelized affordance and constraint maps over the robot's workspace. These 3D value maps encode where the end-effector should go (affordances) and where it should not go (constraints), grounded in the current visual scene via open-vocabulary detectors like OWL-ViT and depth sensors. A model predictive controller (MPC) then optimizes trajectories through these composed value maps at 5 Hz, providing closed-loop robustness against disturbances and perception errors.
VoxPoser achieves an 88.0% average success rate on everyday manipulation tasks in real-world static environments and 70.0% under dynamic disturbances, dramatically outperforming a primitives-based baseline (24.0% static, 0.0% disturbed). In simulation, it demonstrates superior zero-shot generalization to unseen instructions and object attributes. For tasks requiring contact-rich dynamics beyond what zero-shot value maps can handle, VoxPoser uses its synthesized trajectories as priors for efficient online learning, acquiring dynamics models in under 3 minutes of interaction.
Key Contributions
- LLM-generated 3D value maps: Introduces the concept of using LLMs to write code that composes dense 3D voxel grids (affordance maps and constraint maps) as spatial objective functions for robot motion planning, bypassing the need for predefined skills or task-specific training
- Zero-shot open-vocabulary manipulation: Achieves manipulation of arbitrary objects described in natural language by grounding LLM-generated code through open-vocabulary vision models (OWL-ViT) and depth sensing, requiring no robot-specific training data
- Closed-loop MPC on value maps: Combines composed value maps with model predictive control at 5 Hz, enabling real-time replanning and robustness to perturbations -- a key advantage over open-loop trajectory generation
- Efficient few-shot dynamics learning: Demonstrates that zero-shot VoxPoser trajectories serve as intelligent exploration priors, enabling rapid online learning of contact-rich dynamics in under 3 minutes
- Composability of spatial objectives: Shows that complex manipulation behaviors emerge from composing simple affordance and constraint primitives (e.g., "move to X while avoiding Y while rotating Z"), with the LLM handling the compositional reasoning
Architecture
┌──────────────────────────────────────────────────────────┐
│ VoxPoser Pipeline │
│ │
│ "Open the top drawer" │
│ │ │
│ ▼ │
│ ┌──────────────┐ │
│ │ LLM (GPT-4)│ Generates Python code │
│ │ Code Gen │ specifying spatial objectives │
│ └──────┬───────┘ │
│ │ Python code │
│ ▼ │
│ ┌──────────────┐ ┌──────────────┐ │
│ │ OWL-ViT │ │ Depth Camera │ │
│ │ (detect obj)│ │ (3D localize)│ │
│ └──────┬───────┘ └──────┬───────┘ │
│ └────────┬──────────┘ │
│ ▼ │
│ ┌────────────────────────────────┐ │
│ │ 3D Voxel Grid (100x100x100) │ │
│ │ ┌────────────┐ ┌───────────┐ │ │
│ │ │ Affordance │ │ Constraint│ │ │
│ │ │ Map (go to)│+│ Map(avoid)│ │ │
│ │ └────────────┘ └───────────┘ │ │
│ │ + Rotation map + Gripper map │ │
│ └──────────────┬─────────────────┘ │
│ │ Composed value landscape │
│ ▼ │
│ ┌────────────────────────────────┐ │
│ │ MPPI Controller (5 Hz) │ │
│ │ Sample trajectories │ │
│ │ Score against value maps │ │
│ │ Execute best, replan │ │
│ └──────────────┬─────────────────┘ │
│ ▼ │
│ End-effector motion (closed-loop) │
└──────────────────────────────────────────────────────────┘
Architecture / Method

VoxPoser operates through three stages: (1) instruction parsing and code generation, (2) 3D value map composition, and (3) trajectory optimization.
Instruction to code. Given a natural language instruction (e.g., "open the top drawer"), an LLM (GPT-4) generates Python code that specifies which objects to detect and how to compose spatial objectives. The code calls a perception API that uses OWL-ViT for open-vocabulary object detection and depth cameras for 3D localization. The generated code defines affordance maps (regions the end-effector should move toward) and constraint maps (regions to avoid).
3D value map composition. The workspace is voxelized into a 3D grid (typically 100x100x100). The LLM-generated code assigns values to voxels based on their spatial relationship to detected objects. Affordance maps have high values near target locations; constraint maps have high costs near obstacles. These maps are composed additively, creating a single objective landscape. Crucially, the maps are generated dynamically per instruction -- the same perception pipeline supports arbitrary language-specified tasks.
Trajectory optimization. A model predictive controller (MPPI -- Model Predictive Path Integral) optimizes end-effector trajectories through the composed value map. The controller samples trajectory rollouts, scores them against the value map, and executes the best action at 5 Hz, replanning at each step with updated observations. This closed-loop execution provides robustness against perturbations and perception noise.
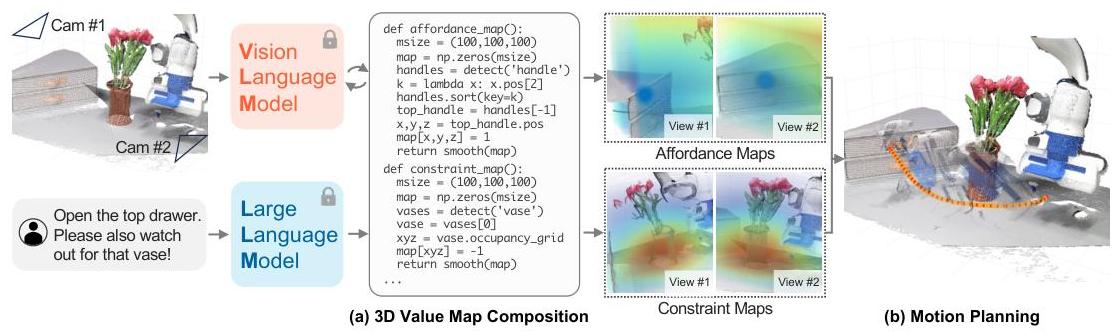
Rotation and gripper control. Beyond end-effector position, VoxPoser handles rotation via rotation value maps (specifying desired orientations at each voxel) and gripper state via velocity maps (specifying open/close actions at spatial locations). These additional channels compose naturally with the positional affordance/constraint maps.
Dynamics learning for contact-rich tasks. For tasks requiring precise contact dynamics (e.g., sweeping objects), VoxPoser's zero-shot trajectories serve as exploration priors. A dynamics model is learned online from a small number of interaction trials (~3 minutes), then used within MPC to produce physically grounded plans.
Results
Real-World Performance
| Condition | VoxPoser | Primitives Baseline |
|---|---|---|
| Static environment | 88.0% | 24.0% |
| Dynamic disturbances | 70.0% | 0.0% |
VoxPoser was evaluated on 5 representative real-world manipulation tasks: Move & Avoid, Set Up Table, Close Printer, Open Bottle, and Sweep Trash. The primitives baseline uses the same LLM to parameterize pre-defined motion primitives rather than composing value maps.
Simulation Generalization
VoxPoser was evaluated on 13 highly-randomizable simulated tasks with 2,766 unique instructions, enabling rigorous testing of zero-shot generalization. On object interaction tasks, VoxPoser achieves:
| Instruction/Attribute Setting | VoxPoser Success Rate |
|---|---|
| Seen instructions & attributes | 64.0% |
| Unseen object attributes | 60.0% |
| Entirely unseen combinations | 65.0% |
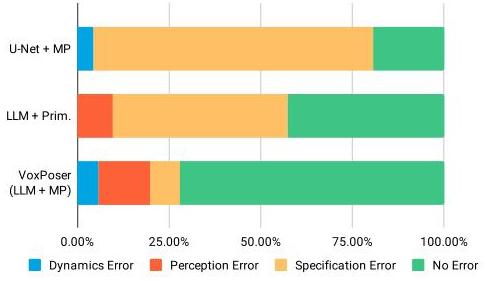
VoxPoser consistently outperformed baselines (LLM + Primitives and U-Net + Motion Planning) across generalization categories, particularly excelling at spatial reasoning tasks that require understanding 3D geometry.
Dynamics Learning Efficiency
For contact-rich tasks (e.g., sweeping), VoxPoser's zero-shot trajectories as exploration priors enable 80.0–91.7% success rates with under 3 minutes of online interaction, compared to baselines that exceeded 12-hour time limits without the intelligent prior.
Limitations & Open Questions
- LLM latency: The code generation step requires LLM inference (GPT-4), adding latency to the initial planning phase. Real-time replanning uses cached value maps but initial composition can take seconds
- Perception bottleneck: Relies on open-vocabulary detectors (OWL-ViT) for grounding, which can fail on small, occluded, or visually ambiguous objects. Depth sensing noise also affects value map quality
- Voxel resolution trade-off: The 100x100x100 voxel grid limits spatial precision. Fine manipulation tasks (e.g., threading a needle) may require higher resolution, which increases compute cost cubically
- No learned long-horizon planning: VoxPoser handles single-step instructions well but lacks explicit mechanisms for multi-step task decomposition beyond what the LLM provides through sequential code generation
- Closed-source LLM dependency: Relies on GPT-4 for code generation, raising reproducibility and deployment concerns. Whether open-source LLMs (LLaMA, etc.) can achieve comparable code quality for value map synthesis is untested in the paper
Connections
Related papers in the wiki: - Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control — RT-2 fine-tunes VLMs for action tokens; VoxPoser instead uses LLMs to compose spatial objectives without any robot-specific training - Palm E An Embodied Multimodal Language Model — PaLM-E uses an LLM as an embodied reasoning backbone; VoxPoser uses LLMs for spatial code generation rather than direct action prediction - Openvla An Open Source Vision Language Action Model — OpenVLA represents the end-to-end VLA paradigm; VoxPoser represents the complementary "LLM as planner" paradigm that avoids task-specific training - A Generalist Agent — Gato tokenizes actions; VoxPoser avoids tokenization entirely by using 3D value maps as the action interface - Learning Transferable Visual Models From Natural Language Supervision — CLIP/OWL-ViT style open-vocabulary vision is a key enabler for VoxPoser's object grounding - Robotics — Broader context on the robotics VLA landscape - Vision Language Action — VoxPoser represents a "language as runtime control" approach distinct from end-to-end VLAs - Planning — VoxPoser's MPC-based trajectory optimization connects to planning concepts