3D-VLA: A 3D Vision-Language-Action Generative World Model
Overview
3D-VLA addresses a fundamental limitation of existing vision-language-action models: their reliance on 2D visual representations, which lack the spatial depth understanding necessary for effective embodied interaction. While models like RT-2 and PaLM-E demonstrated that VLMs can be adapted for robotic control, they operate primarily on 2D image features, losing critical 3D geometric information about object distances, shapes, and spatial relationships. 3D-VLA proposes that injecting explicit 3D perception into the VLA framework — and coupling it with a generative world model — produces agents that can better reason about and interact with the physical world.
The core approach builds a unified architecture with three key components: (1) a 3D-aware vision encoder that processes RGBD data or point clouds, (2) a large language model backbone for multimodal reasoning, and (3) diffusion-based generative heads that can predict future visual states (RGBD images) and goal point clouds. Special interaction tokens (<scene>, <obj>, <img>, <pcd>) bridge 3D perception with language reasoning, while a Q-Former module extracts compact 3D features for the LLM. This enables the model to not only perceive and act but also "imagine" the consequences of actions — a world-modeling capability that goes beyond the standard perception-to-action pipeline.
The paper also contributes a large-scale 3D embodied instruction dataset, constructed by augmenting existing robotics datasets with depth information, 3D bounding boxes, and language-action pairings. Experiments across embodied reasoning, multimodal generation, and robotic manipulation tasks show that 3D-VLA outperforms 2D baselines, validating the importance of 3D representations for embodied AI. With ~140 citations at ICML 2024, the paper has been influential in motivating 3D-grounded approaches in both robotics and driving VLA research.
Key Contributions
- 3D-grounded VLA architecture: First framework to integrate explicit 3D perception (point clouds, depth) into a vision-language-action model via interaction tokens and Q-Former-based feature extraction, moving beyond 2D-only VLAs
- Generative world model: Uses diffusion models to predict future RGBD images and goal point clouds, enabling the agent to reason about action consequences before executing — a key step toward model-based embodied planning
- 3D embodied instruction dataset: Large-scale dataset created by extracting and augmenting existing robotics data with depth, 3D bounding boxes, and structured language-action pairs
- Unified multi-task framework: A single model handles embodied reasoning (3D QA, scene understanding), multimodal generation (image/point cloud prediction), and action generation (robotic manipulation)
- Empirical validation of 3D for embodied AI: Demonstrates that 3D-aware representations consistently outperform 2D baselines across reasoning, generation, and control tasks
Architecture / Method
┌─────────────────────────────────────────────────────────────────────┐
│ 3D-VLA Architecture │
├─────────────────────────────────────────────────────────────────────┤
│ │
│ RGBD / Point Cloud Text Instruction │
│ │ │ │
│ ▼ ▼ │
│ ┌──────────────┐ ┌─────────────┐ │
│ │ 3D Vision │ │ Tokenizer │ │
│ │ Encoder │ └──────┬──────┘ │
│ └──────┬───────┘ │ │
│ ▼ │ │
│ ┌──────────────┐ Interaction Tokens │ │
│ │ Q-Former │ <scene> <obj> <img> │ │
│ │ Bridge │ <pcd> │ │
│ └──────┬───────┘ │ │
│ │ ┌───────────────┐ │ │
│ └─────────►│ LLM │◄──────┘ │
│ │ Backbone │ │
│ └───┬───┬───┬──┘ │
│ │ │ │ │
│ ┌─────────┘ │ └──────────┐ │
│ ▼ ▼ ▼ │
│ ┌───────────────┐ ┌────────────┐ ┌────────────┐ │
│ │ Diffusion: │ │ Diffusion: │ │ Action │ │
│ │ RGBD Predict │ │ Point Cloud │ │ Head │ │
│ └───────────────┘ └────────────┘ └────────────┘ │
│ Future Images Goal PCD Motor Commands │
└─────────────────────────────────────────────────────────────────────┘
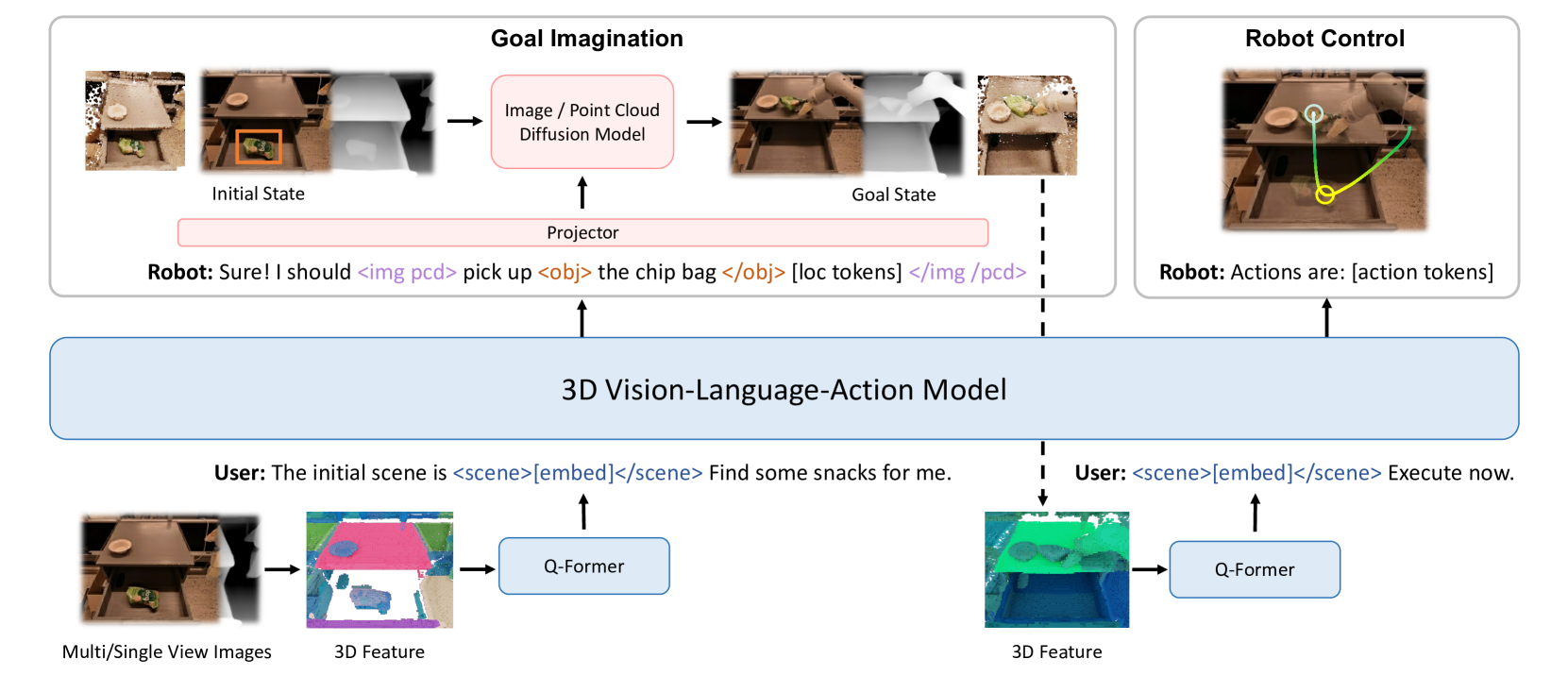
The architecture consists of five interconnected modules:
3D Vision Encoder. Processes RGBD images or point clouds to extract spatially-grounded visual features. Unlike standard VLAs that use 2D image encoders (e.g., ViT), 3D-VLA encodes depth and geometry explicitly, preserving the spatial structure needed for manipulation tasks.
Q-Former Bridge. A cross-attention module (following the BLIP-2 pattern) that compresses the high-dimensional 3D features into a fixed set of learnable query tokens. These tokens become the visual input to the LLM, enabling efficient integration of 3D information without overwhelming the language model's context window.
LLM Backbone. A large language model that processes interleaved sequences of text tokens, 3D visual tokens (from the Q-Former), and special interaction tokens. The interaction tokens (<scene>, <obj>, <img>, <pcd>) serve as typed delimiters that signal to the model what kind of information follows or what kind of output to generate. This allows the same model to handle diverse tasks (QA, generation, action) through a unified autoregressive interface.
Diffusion-based Generative Heads. Separate diffusion models for generating future RGBD images and goal point clouds. A projector module connects the LLM's output representations to these diffusion decoders. When the model is asked to "imagine" a future state — e.g., what will the scene look like after picking up an object — the LLM produces a latent representation that conditions the diffusion process to generate the predicted observation.
Action Head. Generates motor commands for robotic manipulation, conditioned on the LLM's reasoning and optionally on the imagined goal state from the generative heads.

Training procedure. The model is trained in a multi-task fashion across three categories: (1) embodied reasoning tasks (3D scene QA, object grounding), (2) multimodal generation tasks (RGBD prediction, point cloud generation), and (3) action generation tasks (robotic manipulation). The training leverages the constructed 3D embodied instruction dataset, with task-specific prompts and the interaction token vocabulary directing the model's behavior. The LLM backbone is initialized from a pretrained checkpoint and fine-tuned jointly with the 3D encoder, Q-Former, and generative heads.
Results
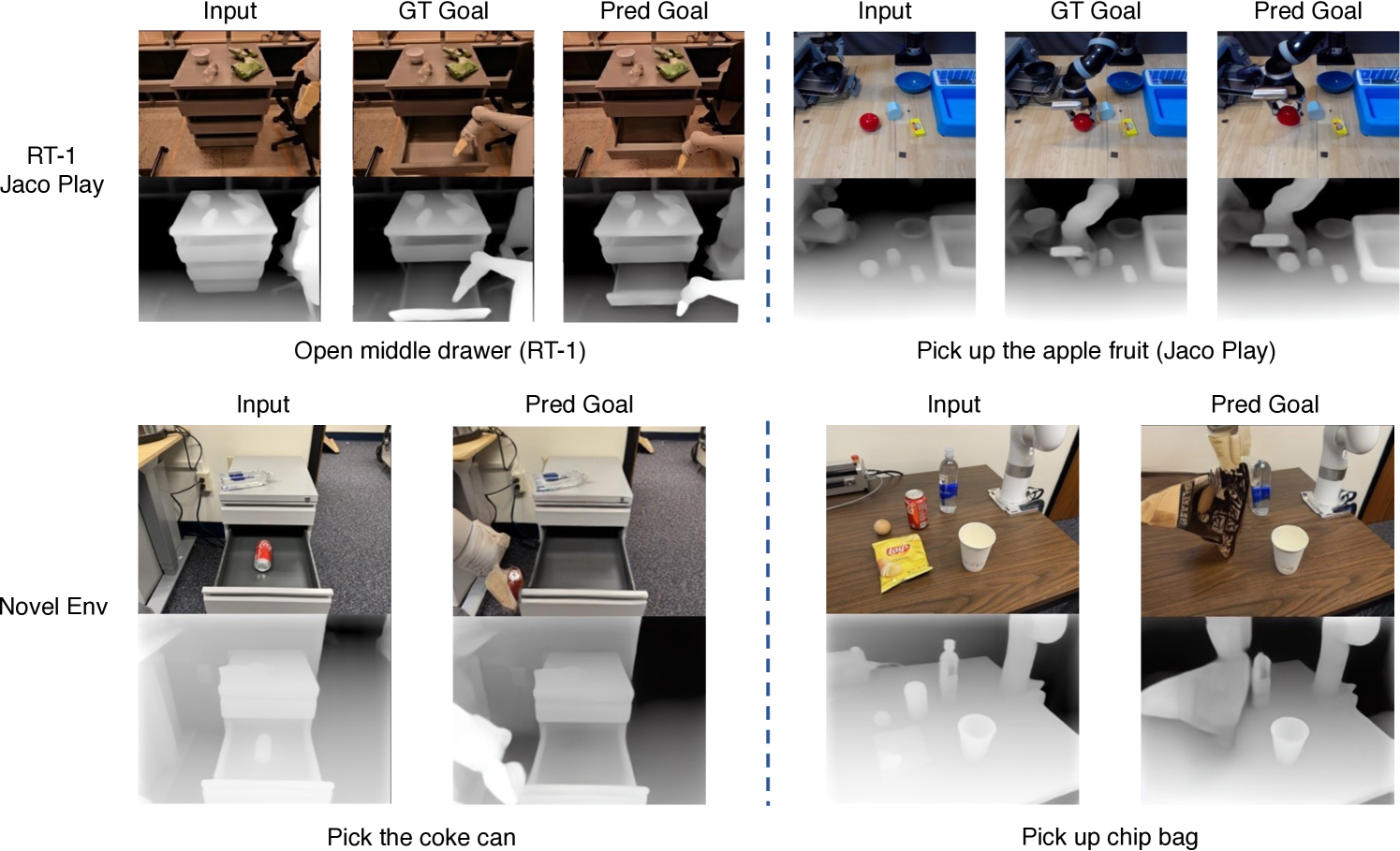
3D-VLA demonstrates improvements over 2D baselines across all three task categories:
Embodied Reasoning. On 3D scene understanding and question answering tasks, the 3D-grounded representations enable more accurate spatial reasoning (e.g., understanding object relationships, distances, and orientations) compared to models that rely solely on 2D image features.
Multimodal Generation. The diffusion-based world model generates plausible future RGBD images and goal point clouds, demonstrating that the model has learned a useful internal representation of how actions change the 3D scene. The generated goals are coherent with the language instructions.
Robotic Manipulation. On manipulation benchmarks, 3D-VLA outperforms 2D VLA baselines, with the world-modeling component providing additional benefit — the model can verify its planned actions against imagined outcomes before execution.
The ablation studies confirm that both the 3D representation (vs. 2D-only) and the generative world model (vs. direct perception-to-action) contribute meaningfully to performance.
Limitations & Open Questions
- Computational cost: The combination of 3D encoder, LLM, and diffusion heads is expensive; the paper does not extensively address inference latency or deployment constraints
- Depth quality dependence: Performance relies on accurate depth information, which varies significantly across sensor setups and environments
- Dataset scale: While the constructed 3D dataset is large, it is derived from existing robotics datasets — the diversity and complexity of tasks may be limited compared to what emerges from truly large-scale in-the-wild data
- Sim-to-real gap: The generative world model's accuracy in predicting real-world scene changes (as opposed to synthetic/lab environments) is not thoroughly evaluated
- Action space generality: The manipulation tasks evaluated are relatively constrained; whether the 3D-VLA framework scales to more complex, long-horizon tasks (e.g., mobile manipulation, humanoid control) remains open
- Driving domain transfer: The paper focuses on robotic manipulation; whether 3D-VLA's approach of explicit 3D perception + world modeling transfers to driving VLAs (where 3D perception is also critical) is an interesting direction explored by later work like OpenDriveVLA
Connections
Related papers in the wiki:
- Palm E An Embodied Multimodal Language Model — PaLM-E pioneered injecting continuous sensor observations into LLMs for embodied reasoning; 3D-VLA extends this by adding explicit 3D perception and generative world modeling
- Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control — RT-2 established the "actions as tokens" VLA paradigm that 3D-VLA builds upon, but with 2D-only visual representations
- Openvla An Open Source Vision Language Action Model — OpenVLA democratized VLA research with an open 7B model; 3D-VLA argues that 3D perception is a missing ingredient in such models
- Opendrivevla Towards End To End Autonomous Driving With Large Vision Language Action Model — OpenDriveVLA brings 3D-grounded queries into driving VLAs, a direction motivated by 3D-VLA's findings
- Voxposer Composable 3D Value Maps For Robotic Manipulation With Language Models — VoxPoser also combines 3D spatial representations with LLMs for manipulation, but through code-generated value maps rather than end-to-end training
- Cosmos World Foundation Model Platform For Physical Ai — Cosmos extends world modeling for physical AI at platform scale; 3D-VLA is an earlier example of integrating world models into VLA architectures
- Hermes A Unified Self Driving World Model For Simultaneous 3D Scene Understanding And Generation — HERMES pursues a similar goal of unified 3D understanding and generation for driving
- Vision Language Action — Broader VLA concept page; 3D-VLA contributes the argument that 3D perception is essential for embodied VLAs
- Robotics — Robotics concept page; 3D-VLA fits in the trajectory from RT-2 to 3D-grounded embodied agents
- Foundation Models — 3D-VLA combines foundation model components (LLM + diffusion) for embodied AI