Overview
OpenDriveVLA introduces a Vision-Language Action model specifically designed for end-to-end autonomous driving. Unlike previous approaches that use VLMs as supplementary components or apply generic 2D models, OpenDriveVLA creates a 3D spatial-aware driving system that explicitly models instance-aware scene representations while maintaining the reasoning capabilities of large language models. The architecture leverages open-source LLMs (Qwen 2.5-Instruct in 0.5B, 3B, and 7B variants) as the decision-making backbone with specialized visual encoders for spatial grounding.
The visual system employs a vision-centric design using ResNet-101 to extract multi-scale features from multi-view cameras, transformed into Bird's-Eye-View representation. Three specialized visual query modules mitigate hallucinations: a Global Scene Sampler for overall scene context, an Agent QueryTransformer for dynamic agent detection and tracking, and a Map QueryTransformer for static infrastructure extraction. A four-stage training pipeline progressively builds capabilities from vision-language alignment through driving instruction tuning, interaction modeling, and finally end-to-end trajectory planning.
Notably, the compact 0.5B variant achieves competitive 0.35m L2 error with low collision rates (0.09% average), often matching or exceeding larger models, suggesting that the multi-stage training strategy and architectural design are more critical than raw model scale for this domain.
Key Contributions
- First open-source VLA for driving with hierarchical 3D scene representation (global scene, agents, map) integrated into an LLM backbone
- Four-stage progressive training pipeline: vision-language alignment, driving instruction tuning, agent-environment interaction modeling, and E2E trajectory planning
- Demonstrates that a 0.5B model can match 7B performance via architectural design, challenging the "bigger is better" assumption
- Achieves state-of-the-art L2 displacement error (0.33m for 3B/7B) on nuScenes, outperforming DriveVLM (0.40m)
- Provides interpretable QA outputs alongside trajectory prediction (BLEU-4 of 27.6 for 7B variant)
Architecture / Method
OpenDriveVLA Architecture
────────────────────────
Multi-view ┌───────────────────┐
Camera ─────────►│ ResNet-101 │
Images │ (Multi-scale │
│ Feature Extrac.) │
└─────────┬─────────┘
│ BEV Features
┌────────────┼────────────┐
▼ ▼ ▼
┌─────────────┐ ┌─────────┐ ┌─────────────┐
│ Global Scene│ │ Agent │ │ Map │
│ Sampler │ │ Query │ │ Query │
│ (Q_scene) │ │ Transf. │ │ Transf. │
│ │ │(Q_agent)│ │ (Q_map) │
└──────┬──────┘ └────┬────┘ └──────┬──────┘
│ │ │
└──────┬──────┴──────┬───────┘
│ Projectors │
▼ ▼
Ego State ──► ┌───────────────────────────────────┐
(text) ──► │ Qwen 2.5-Instruct LLM │
Language ──► │ (0.5B / 3B / 7B) │
Command ──► └───────────────┬───────────────────┘
│
┌──────────┴──────────┐
▼ ▼
QA Text Output Trajectory Waypoints
(interpretable) (autoregressive tokens)
Training: Stage 1 ──► Stage 2 ──► Stage 2.5 ──► Stage 3
VL Align Instruct Interaction E2E Plan
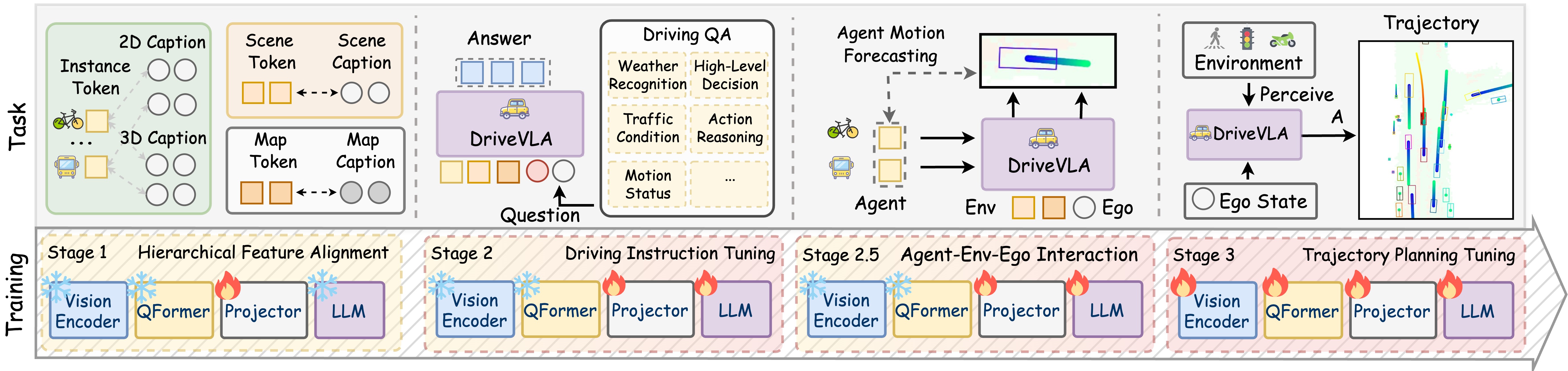
The architecture processes multiple input modalities: multi-view camera images through a 3D perception pipeline, ego state (position, velocity, orientation) as text, language commands for high-level instructions, and historical trajectory context for temporal consistency.
Three specialized query modules ground visual features into the LLM's semantic space: - Global Scene Sampler (Q_scene): Encodes overall driving context into a global scene token - Agent QueryTransformer (Q_agent): Detects and tracks dynamic agents with 2D appearance and 3D spatial position captions - Map QueryTransformer (Q_map): Extracts static infrastructure (lane boundaries, road elements)
The four-stage training strategy: 1. Stage 1 -- Hierarchical Vision-Language Alignment: Token-specific projectors map visual features to LLM space. Encoder and LLM frozen; only projectors train. 2. Stage 2 -- Driving Instruction Tuning: Supervised tuning on TOD3Cap, nuCaption, nuScenesQA, nuX, and GPT-Driver. Projectors and LLM trainable. 3. Stage 2.5 -- Interaction Modeling: Conditional agent trajectory forecasting to instill spatially-grounded interaction priors. 4. Stage 3 -- E2E Trajectory Planning: Full pipeline trains end-to-end. Waypoints tokenized as text for autoregressive generation.
Training uses mixed-precision (bf16) and gradient checkpointing on 4x NVIDIA H100 GPUs with batch size 1 per GPU, completing in approximately two days for the 0.5B variant.
Results

| Model | L2 Error (m) | Collision Rate (%) | BLEU-4 |
|---|---|---|---|
| DriveVLM | 0.40 | -- | -- |
| LiDAR-LLM | -- | -- | ~20 |
| OpenDriveVLA-0.5B | 0.35 | 0.09 | -- |
| OpenDriveVLA-3B | 0.33 | -- | -- |
| OpenDriveVLA-7B | 0.33 | 0.10 | 27.6 |
Ablation studies confirm the importance of each training stage, with the most substantial gains in collision avoidance occurring after hierarchical vision-language alignment and interaction modeling stages. Comparative visualizations with UniAD show smoother, more semantically consistent trajectories, particularly in challenging scenarios involving narrow roads with parked vehicles or complex intersection navigation.
Limitations & Open Questions
- Evaluation is limited to open-loop settings, which cannot capture interactive dynamics where ego actions influence other agents' behaviors
- Autoregressive LLM inference introduces latency that may challenge real-time deployment in high-speed scenarios
- Scaling model size alone does not consistently improve performance, suggesting the bottleneck is domain-specific training data rather than model capacity
Connections
- Drivevlm The Convergence Of Autonomous Driving And Large Vision Language Models -- DriveVLM baseline surpassed by OpenDriveVLA
- Lmdrive Closed Loop End To End Driving With Large Language Models -- Prior language-conditioned driving system
- Openvla An Open Source Vision Language Action Model -- General-purpose open-source VLA that OpenDriveVLA specializes for driving
- Planning Oriented Autonomous Driving -- UniAD joint training paradigm extended here with VLA backbone
- Bevformer Learning Birds Eye View Representation From Multi Camera Images Via Spatiotemporal Transformers -- BEV representation foundation used in the perception pipeline
- Emma End To End Multimodal Model For Autonomous Driving -- Alternative everything-as-tokens VLA approach