Flamingo: a Visual Language Model for Few-Shot Learning
Overview
Flamingo, developed by DeepMind, is a family of visual language models that extend the in-context few-shot learning ability of large language models to multimodal (image and video) inputs. The central problem Flamingo addresses is that while LLMs like GPT-3 demonstrated remarkable few-shot learning from text-only prompts, there was no equivalent capability for tasks requiring joint vision-and-language understanding. Prior multimodal models required expensive fine-tuning on each downstream task with large labeled datasets -- Flamingo showed that a single model can rapidly adapt to new vision-language tasks given only a handful of input-output examples, with no parameter updates.
The core architectural insight is to keep powerful pretrained components frozen -- a vision encoder (NFNet-F6 trained contrastively, similar to CLIP) and a large language model (Chinchilla, 70B parameters) -- and connect them through two lightweight trainable modules: a Perceiver Resampler that compresses variable-length visual features into a fixed set of 64 visual tokens, and gated cross-attention dense (GATED XATTN-DENSE) layers interleaved with the frozen LM layers that allow the language model to attend to visual information. The gating mechanism uses a learned tanh gate initialized to zero, ensuring the model starts as the original LM and gradually learns to incorporate visual information during training.
Flamingo set a new state of the art on 16 multimodal benchmarks spanning visual question answering (VQAv2, OK-VQA, TextVQA, VizWiz), image captioning (COCO, Flickr30k), and video understanding (MSRVTT, VATEX, YouCook2, etc.) -- often surpassing prior systems that were fine-tuned on thousands of task-specific labeled examples, using only 4-32 few-shot examples. The 80B-parameter Flamingo model even outperformed fine-tuned state-of-the-art on 6 of 16 benchmarks with just 32 shots. Flamingo is a foundational work in the multimodal foundation model lineage, directly influencing subsequent models like PaLM-E, GPT-4V, and the entire VLA paradigm that connects vision-language understanding to action generation.
Key Contributions
- Few-shot multimodal learning: Demonstrated that in-context learning -- previously shown only for text -- extends to interleaved image/video and text inputs, enabling rapid adaptation to new vision-language tasks without fine-tuning
- Perceiver Resampler: A transformer-based module using learned latent queries to compress variable-length visual feature maps (from single images or video frames) into a fixed set of 64 visual tokens, providing an efficient and resolution-agnostic visual interface to the language model
- Gated cross-attention layers: Novel GATED XATTN-DENSE layers interleaved with frozen LM layers, where a tanh gate initialized to zero allows the model to smoothly transition from pure language modeling to visually-grounded generation during training
- Frozen backbone strategy: By keeping both the vision encoder and language model frozen and training only the cross-modal bridges (~10.2B trainable parameters out of 80B total for the largest model), Flamingo preserves the generalization capabilities of both pretrained components while achieving strong multimodal performance
- Multi-image and video support: A single architecture handles interleaved sequences of images and text (e.g., multi-turn visual dialogue) as well as video inputs, using a simple "assign visual tokens to the most recent preceding image" attention masking scheme
Architecture / Method
┌─────────────────────────────────────────────────────────────────┐
│ Flamingo Architecture │
│ │
│ ┌──────────────┐ │
│ │ Image / Video│ │
│ └──────┬───────┘ │
│ ▼ │
│ ┌──────────────────┐ │
│ │ Vision Encoder │ (frozen NFNet-F6, │
│ │ (contrastive) │ CLIP-style pretrained) │
│ └──────┬───────────┘ │
│ │ spatial features (variable size) │
│ ▼ │
│ ┌──────────────────┐ │
│ │ Perceiver │ 64 learned latent queries │
│ │ Resampler │ cross-attend to visual features │
│ │ │ ──► fixed 64 visual tokens │
│ └──────┬───────────┘ │
│ │ 64 visual tokens │
│ │ │
│ │ ┌───────────────────────────────────────────┐ │
│ │ │ Frozen LM (Chinchilla 70B) │ │
│ │ │ │ │
│ │ │ ┌─────────────────────────────────┐ │ │
│ │ │ │ GATED XATTN-DENSE Layer │ │ │
│ └───►│ │ text ──cross-attn──► 64 visual │ │ │
│ │ │ output x tanh(alpha), alpha=0 │ │ │
│ │ │ + residual │ │ │
│ │ └─────────────────────────────────┘ │ │
│ │ ▼ │ │
│ │ ┌─────────────────────────────────┐ │ │
│ │ │ Frozen LM Layer (self-attention │ │ │
│ │ │ + FFN) │ │ │
│ │ └─────────────────────────────────┘ │ │
│ │ ... repeat for each LM layer ... │ │
│ │ │ │
│ │ ▼ │ │
│ │ Text token output │ │
│ └───────────────────────────────────────────┘ │
│ │
│ Trainable: Perceiver Resampler + GATED XATTN-DENSE (~10.2B) │
│ Frozen: Vision encoder + LM backbone (~70B) │
└─────────────────────────────────────────────────────────────────┘

Flamingo's architecture connects a frozen vision encoder to a frozen language model through two trainable bridges:
Vision Encoder: A Normalizer-Free ResNet (NFNet-F6) pretrained with a contrastive image-text objective (similar to CLIP). For images, features are extracted from the final spatial feature map. For videos, frames are sampled at 1 FPS, processed independently by the vision encoder, and augmented with learned temporal embeddings. The vision encoder is frozen during Flamingo training.
Perceiver Resampler: Takes the variable-size spatial features from the vision encoder (e.g., a grid of features from different resolution images or varying numbers of video frames) and produces a fixed set of 64 visual tokens. It uses a small transformer with learned latent query vectors that cross-attend to the visual features. This design is inspired by Perceiver IO and ensures constant computational cost regardless of input resolution or number of video frames.
Gated Cross-Attention Dense Layers (GATED XATTN-DENSE): These are inserted before every Kth frozen LM layer (typically every 4th-7th layer in practice). Each layer performs:
1. Cross-attention from the text hidden state to the 64 visual tokens produced by the Perceiver Resampler
2. The cross-attention output is multiplied by tanh(α_xattn) (a learned scalar initialized to 0) and added to the residual stream
3. A dense FFN sub-layer follows, also gated by a separate tanh(α_dense) scalar initialized to 0
4. Both gates starting at zero ensure the block has no effect at initialization, preserving the frozen LM behavior at the start of training
The zero initialization is critical: at the start of training, the gated cross-attention has no effect, so the model behaves exactly like the original frozen LM. This ensures training stability and allows the model to gradually learn how to use visual information.
Interleaved attention masking: When processing sequences with multiple images interleaved with text, each text token only attends to the visual tokens from the most recent preceding image. This simple scheme enables the model to handle multi-image prompts (for few-shot learning) and visual dialogue naturally.
Model scales: Flamingo comes in three sizes -- 3B (1.4B Chinchilla LM), 9B (7B Chinchilla LM), and 80B (70B Chinchilla LM). The 80B model has approximately 10.2B trainable parameters (the cross-attention layers and Perceiver Resampler), with the remaining ~70B frozen.
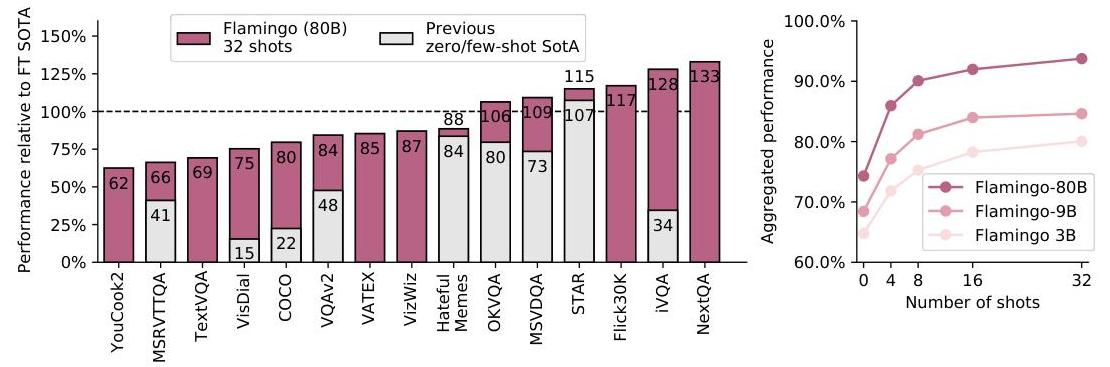
Results
Flamingo was evaluated on 16 multimodal benchmarks across three categories:
Visual Question Answering
| Benchmark | Flamingo-80B (32-shot) | Prior SOTA (fine-tuned) | Flamingo better? |
|---|---|---|---|
| VQAv2 | 67.6 | 80.0 (PaLI) | No |
| OK-VQA | 57.8 | 54.4 | Yes |
| TextVQA | 54.1 | 73.7 | No |
| VizWiz | 65.7 | 57.4 | Yes |
| HatefulMemes | 70.0 | 64.7 | Yes |
Image/Video Captioning
| Benchmark | Flamingo-80B (32-shot) | Prior SOTA (fine-tuned) | Flamingo better? |
|---|---|---|---|
| COCO (CIDEr) | 138.1 | 145.3 | No |
| Flickr30k (CIDEr) | 99.0 | — | Competitive |
| MSRVTT (CIDEr) | 47.4 | — | SOTA |
| VATEX (CIDEr) | 76.0 | — | SOTA |
Key findings: - Flamingo-80B surpasses fine-tuned SOTA on 6 of 16 benchmarks using only 32 examples - Performance scales log-linearly with the number of few-shot examples (4 to 32 shots) - The 80B model significantly outperforms the 9B model, which in turn outperforms the 3B model, confirming that scaling the frozen LM backbone is critical - When fine-tuned on full downstream datasets, Flamingo-80B sets a new SOTA on 5 additional benchmarks
Key Ablations
- Gating mechanism: Removing the tanh gating degrades performance significantly; without it, the model struggles to preserve the LM's language capabilities
- Perceiver Resampler vs. alternatives: The Perceiver Resampler outperforms MLP projection and vanilla transformer pooling, while being more compute-efficient
- Cross-attention frequency: Inserting XATTN layers every 4th-7th LM layer provides the optimal balance; inserting at every single LM layer is not required and adding them too sparsely (e.g., every-8th) reduces performance
- Training data mixture: The combination of all three web corpora (interleaved webpages, image-text pairs, video-text pairs) outperforms any single source; the interleaved webpage data (MultiModal MassiveWeb) is particularly important for few-shot ability
Training
Flamingo is trained on a mixture of three large-scale web datasets: - MultiModal MassiveWeb (M3W): 43 million webpages with interleaved images and text, scraped from the web. This is the key data source for few-shot generalization -- it provides naturally interleaved multi-image sequences - LTIP (Long Text & Image Pairs): 312 million image-text pairs - VTP (Video & Text Pairs): 27 million short video clips paired with text descriptions
Training uses a multi-objective approach with dataset-specific weights. The model is trained for approximately 500K steps. Only the Perceiver Resampler and GATED XATTN-DENSE layers are trained; vision encoder and LM remain frozen throughout.
Limitations & Open Questions
- Closed-source: Neither the model weights, training data (M3W), nor the contrastive vision encoder were publicly released, limiting reproducibility
- Hallucination: Like all VLMs, Flamingo can generate plausible but factually incorrect descriptions of visual content
- Computational cost: The 80B model requires substantial compute for both training and inference, making few-shot deployment expensive despite avoiding fine-tuning
- Classification ceiling: On traditional classification benchmarks (e.g., ImageNet), few-shot Flamingo underperforms contrastive models like CLIP that are specifically designed for zero-shot classification
- Bias and safety: The model inherits biases from its web-scraped training data and frozen LM backbone; the paper acknowledges but does not fully address these risks
- Open question: How does the Perceiver Resampler's fixed 64-token bottleneck limit performance on tasks requiring fine-grained spatial understanding?
Connections
Related papers in the wiki: - Learning Transferable Visual Models From Natural Language Supervision — CLIP provides the contrastive vision-language pretraining paradigm that Flamingo's vision encoder builds on; Flamingo extends this from matching to generation - Language Models Are Few Shot Learners — GPT-3 demonstrated text-only few-shot learning; Flamingo is the multimodal generalization of this capability - Attention Is All You Need — The transformer architecture underlying both Flamingo's frozen LM and the Perceiver Resampler - Training Compute Optimal Large Language Models — Chinchilla is Flamingo's frozen LM backbone; its compute-optimal training directly enables Flamingo's strong language capabilities - A Generalist Agent — Gato (2022, also DeepMind) took a different approach to multimodal generalism: tokenize everything into a single sequence, rather than Flamingo's frozen-backbone-with-bridges approach - Palm E An Embodied Multimodal Language Model — PaLM-E (2023) follows Flamingo's paradigm of injecting visual tokens into a frozen LM, extending it to embodied robotics tasks - Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control — RT-2 builds on VLM pretraining (in the lineage Flamingo established) to produce a vision-language-action model for robotics - Foundation Models — Flamingo is a landmark in the vision-language foundation model trajectory from CLIP to modern VLAs