Dita: Scaling Diffusion Transformer for Generalist Vision-Language-Action Policy
Overview
Dita introduces a scalable framework that leverages full Transformer architectures to directly denoise continuous action sequences through a unified multimodal diffusion process. Prior diffusion-based VLA methods condition denoising on fused embeddings via shallow MLP networks, limiting their capacity for fine-grained alignment between actions and observations. Dita instead uses "in-context conditioning" -- language tokens, visual features, and timestep embeddings are concatenated before the noisy action sequence within a causal Transformer, enabling the full attention mechanism to align denoised actions with raw visual tokens from historical observations.
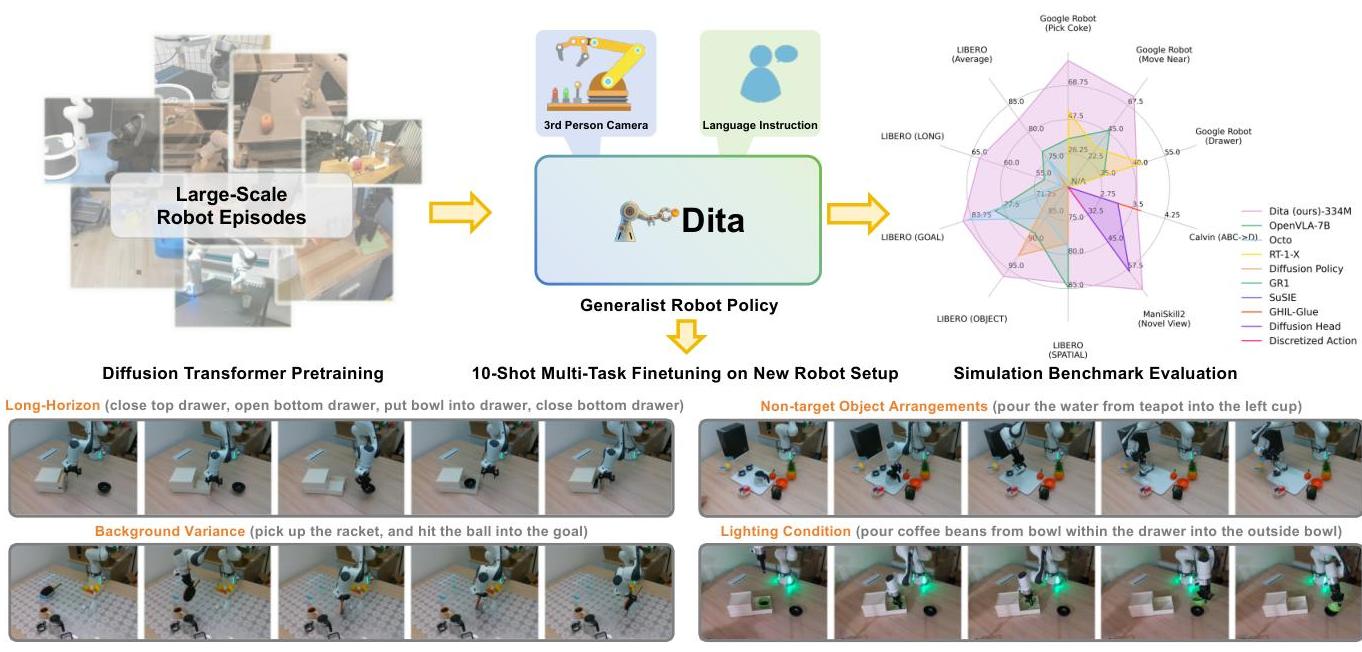
This architectural choice makes Dita inherently scalable: by scaling the diffusion action denoiser alongside the Transformer, the model effectively integrates cross-embodiment datasets spanning diverse camera perspectives, observation scenes, tasks, and action spaces. At only 334M parameters (221M trainable), Dita achieves state-of-the-art or competitive performance across extensive simulation benchmarks and demonstrates robust real-world adaptation to environmental variances and complex long-horizon tasks through just 10-shot finetuning with only third-person camera inputs.
Key Contributions
- In-context diffusion conditioning: Full Transformer processes language, visual, and action tokens in a unified sequence, replacing shallow conditioning networks with rich cross-modal attention
- Scalable cross-embodiment architecture: DiT-based design naturally scales to diverse robot configurations, camera perspectives, and action spaces present in large datasets
- 10-shot real-world adaptation: Achieves robust real-world manipulation from just 10 demonstrations per task via fine-tuning, using only third-person camera inputs
- Lightweight open-source baseline: 334M parameters providing an accessible foundation for generalist robot policy research
- Continuous action generation: Directly denoises continuous action sequences, avoiding discretization artifacts of token-based VLA approaches
Architecture / Method
┌──────────────────────────────────────────────────────────────┐
│ Dita (334M params) │
│ │
│ ┌────────────┐ ┌────────────┐ ┌──────────────────────┐ │
│ │ CLIP Text │ │ DINOv2 │ │ Diffusion Timestep │ │
│ │ Encoder │ │ + Q-Former │ │ Embedding │ │
│ │ (frozen) │ │ (trained) │ │ │ │
│ └─────┬──────┘ └─────┬──────┘ └──────────┬───────────┘ │
│ │ │ │ │
│ ▼ ▼ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ In-Context Token Sequence │ │
│ │ [lang tokens | image features | timestep | noisy │ │
│ │ actions] │ │
│ └──────────────────────┬──────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Causal Transformer (LLaMA-style) │ │
│ │ ┌─────────────────────────────────────────────┐ │ │
│ │ │ Full self-attention across all tokens │ │ │
│ │ │ (language ◄─► vision ◄─► actions) │ │ │
│ │ │ Enables fine-grained cross-modal alignment │ │ │
│ │ └─────────────────────────────────────────────┘ │ │
│ └──────────────────────┬──────────────────────────────┘ │
│ │ │
│ ▼ │
│ ┌─────────────────────────────────────────────────────┐ │
│ │ Denoised Action Sequence (7D continuous) │ │
│ │ [Δx, Δy, Δz, Δroll, Δpitch, Δyaw, gripper] │ │
│ └─────────────────────────────────────────────────────┘ │
│ │
│ DDIM Sampling: 20 denoising steps at inference (T_eval=20) │
└──────────────────────────────────────────────────────────────┘
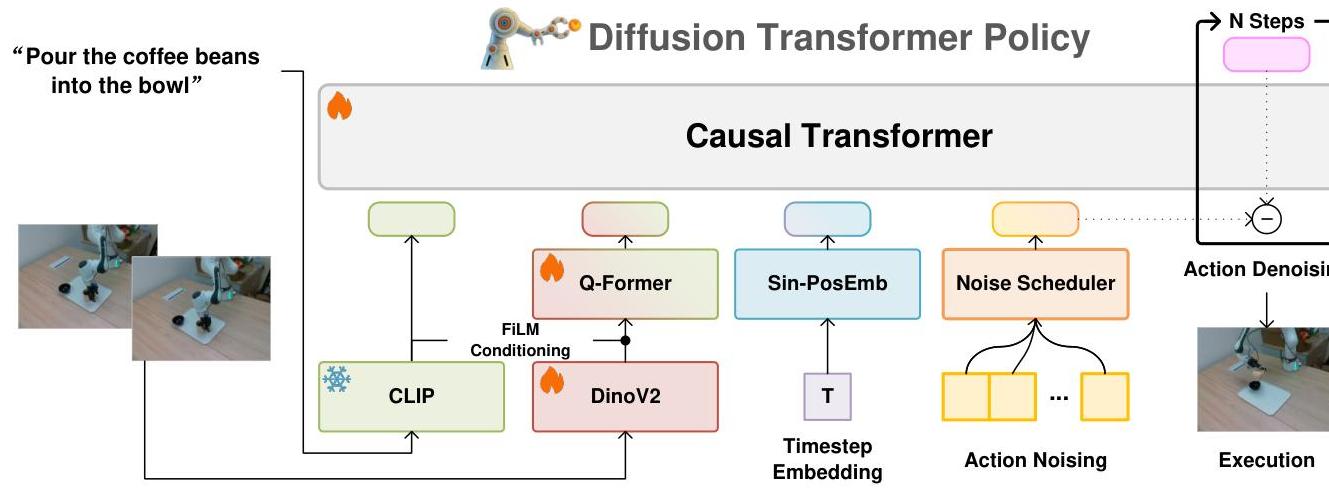
Input Processing: - Language: Frozen CLIP tokenization for task instructions - Vision: DINOv2 feature extraction (jointly optimized during training) with Q-Former for computational efficiency and feature selection - Actions: 7D continuous vectors (3D translation, 3D rotation, 1D gripper position)
Core Design: - Causal Transformer (LLaMA-style architecture, trained from scratch) - In-context conditioning: language tokens + image features + diffusion timestep embeddings are concatenated and placed before the noisy action sequence in the input - Standard denoising diffusion objective with MSE loss - DDIM sampling with T_eval = 20 denoising steps at inference (versus 1000-step DDPM training schedule)
Training: 100,000 steps, batch size 8,192, across 32 A100 GPUs. The model explicitly models action deltas and environmental nuances through fine-grained visual-action alignment.
Results
| Benchmark | Dita | OpenVLA | Improvement |
|---|---|---|---|
| SimplerEnv (coke can) | 83.7% | 16.3% | +67.4% |
| LIBERO overall | 82.4% | 76.5% | +5.9% |
| LIBERO-LONG | 63.8% | ~54% | +10% |
| ManiSkill2 | 65.8% | - | - |
| CALVIN avg length | 3.61 | - | - |
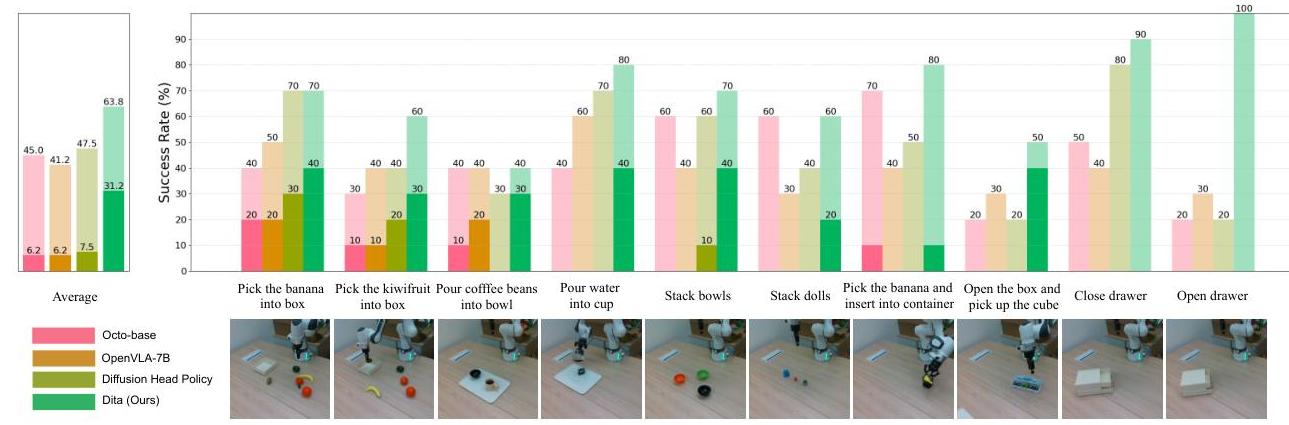
- Real-world (Franka Panda, 10-shot): 63.8% average success rate on complex two-step manipulation tasks
- Robust adaptation across pick-and-place, pouring, stacking, and rotation tasks
- Superior performance on long-horizon multi-step sequences
- Faster convergence and lower final training loss compared to diffusion action head baselines
Limitations
- 334M parameter model is small by VLA standards; scaling behavior at 1B+ parameters is not explored
- 10-shot adaptation, while impressive, is evaluated on relatively simple two-step tasks; complex multi-stage tasks may need more data
- Relies on frozen CLIP for language and jointly-trained DINOv2 for vision; end-to-end training of all components could improve alignment
- Real-world evaluation limited to Franka Panda with third-person camera; generalization to diverse embodiments and viewpoints in the real world is not validated
Connections
- Openvla An Open Source Vision Language Action Model -- Dita significantly outperforms OpenVLA on SimplerEnv and LIBERO while being 20x smaller
- Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control -- RT-2 uses token-based action discretization; Dita uses continuous diffusion
- Uniact Universal Actions For Enhanced Embodied Foundation Models -- Both address cross-embodiment action spaces; UniAct uses VQ codebooks while Dita uses continuous diffusion
- Groot N1 An Open Foundation Model For Generalist Humanoid Robots -- GR00T N1 also uses a diffusion transformer (System 1) for motor control at high frequency
- Robotics -- Advances cross-embodiment generalist policy learning
- Vision Language Action -- Demonstrates diffusion-based alternative to autoregressive action generation