Overview
Octo is a transformer-based generalist robot policy trained on 800,000 robot trajectories from the Open X-Embodiment dataset, spanning 25 diverse datasets and multiple robot embodiments. The paper addresses a critical gap in the robotics foundation model landscape: prior generalist policies like RT-2 were either proprietary and inaccessible, constrained users to predefined sensory inputs, or lacked effective fine-tuning support. Octo is designed from the ground up to be open-source, modular, and readily adaptable to new robots, sensors, and action spaces.
The core architectural insight is a fully transformer-based design (ViT backbone + transformer readout) with a flexible tokenization scheme that handles heterogeneous observation modalities (images from varying camera configurations, language instructions, proprioceptive state) through modality-specific tokenizers feeding into a shared transformer backbone. Actions are predicted via a diffusion-based decoding head, which outperforms both MSE regression and discretized action prediction for continuous control. This design allows Octo to be fine-tuned to new robot setups -- including novel sensors, action spaces, and embodiments -- using as few as ~100 demonstrations in under 5 hours on a single consumer GPU.
Octo-Base (93M parameters) achieves a 29% higher success rate than RT-1-X on language-conditioned tasks and is competitive with the 55B-parameter RT-2-X, demonstrating that careful architecture and data curation can compensate for orders-of-magnitude differences in model scale. The complete release -- model checkpoints, training pipeline, and fine-tuning scripts -- established Octo as the de facto open-source baseline for generalist robot policy research in 2024, directly enabling subsequent work like OpenVLA.
Key Contributions
- Open-source generalist robot policy: First fully open (weights, code, training pipeline) generalist policy trained on 800K trajectories from the Open X-Embodiment dataset, making large-scale robot policy research accessible to the broader community
- Modular transformer architecture: Flexible tokenization scheme supporting heterogeneous observations (multi-view images, language, proprioception) with a shared transformer backbone, enabling adaptation to new modalities without architectural changes
- Diffusion-based action decoding: Conditional diffusion head for action prediction that significantly outperforms MSE regression and discretized action heads, particularly for multi-modal action distributions
- Efficient fine-tuning: Demonstrated adaptation to 9 novel robot platforms across 4 institutions using ~100 demonstrations and <5 hours on a consumer NVIDIA A5000 GPU
- Scaling analysis: Systematic ablations showing performance scales with training data diversity, dataset size, and model capacity, with transformer-first ViT architectures outperforming ResNet-based alternatives
Architecture / Method
Octo Architecture
─────────────────
┌──────────────┐ ┌──────────────┐ ┌──────────┐
│ Image(s) │ │ Language │ │ Readout │
│ (cameras) │ │ Instruction │ │ Token │
└──────┬───────┘ └──────┬───────┘ │ [ACT] │
│ │ └────┬─────┘
▼ ▼ │
┌──────────────┐ ┌──────────────┐ │
│ CNN + Patch │ │ T5-base │ │
│ Tokenizer │ │ Encoder │ │
│ (ViT-S/B) │ │ (111M) │ │
└──────┬───────┘ └──────┬───────┘ │
│ │ │
└────────┬────────┘ │
│ Concatenate │
└────────┬──────────────┘
│◄─────────────────────────────────
▼
┌────────────────────────────┐
│ Transformer Backbone │
│ (Causal Attention, │
│ 2-frame temporal window) │
└────────────┬───────────────┘
│ readout embeddings
▼
┌────────────────────────────┐
│ Diffusion Action Head │
│ ┌──────────────────┐ │
│ │ Noise z ~ N(0,1) │ │
│ └────────┬─────────┘ │
│ ▼ │
│ Iterative Denoising │
│ (conditioned on readout) │
└────────────┬───────────────┘
▼
Action Chunk (k steps)
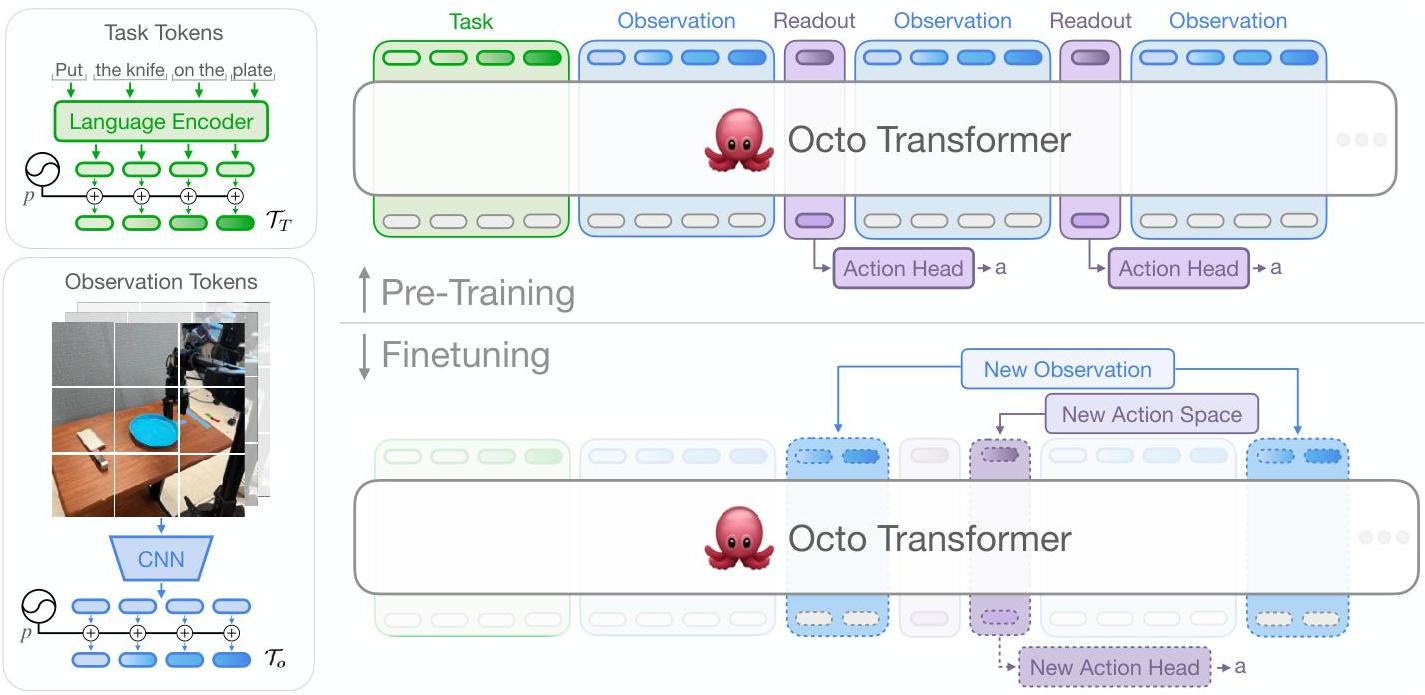
Octo uses a modular encoder-decoder architecture:
Observation Tokenization. Each input modality is processed by a dedicated tokenizer. Images are encoded via a shallow CNN followed by 16×16 pixel patch tokenization using a "transformer-first" approach (ViT-S/B backbone). Language instructions are encoded via a pretrained T5-base transformer (111M parameters). Proprioceptive state was explored but excluded from the final model due to causal confusion issues. A learned readout token is appended to the sequence as the action query.
Transformer Backbone. All tokenized observations are concatenated into a single sequence and processed by a standard transformer with causal attention masking. The backbone processes temporal windows of observations (typically 2 frames) to capture short-horizon dynamics. The shared backbone learns cross-modal representations that ground language instructions in visual context.
Diffusion Action Head. The readout tokens from the transformer are passed to a conditional diffusion decoder that generates action chunks (sequences of future actions). The diffusion head iteratively denoises a Gaussian noise sample conditioned on the readout embeddings, producing continuous multi-step action predictions. This is critical for handling the inherent multi-modality of robot behavior -- a single observation can correspond to multiple valid action sequences, which MSE regression averages destructively.
Model Variants:
| Variant | Parameters | Backbone |
|---|---|---|
| Octo-Small | 27M | ViT-S |
| Octo-Base | 93M | ViT-B |
Training: Octo is trained on a curated subset of the Open X-Embodiment dataset (800K trajectories from 25 datasets) using behavior cloning with the diffusion loss. Training takes approximately 14 hours on a TPU v4-128 pod.
Results

Octo was evaluated across 9 robotic platforms at 4 institutions, testing both zero-shot generalization and fine-tuning transfer:
Zero-shot performance
| Method | Parameters | Language-conditioned Success |
|---|---|---|
| RT-1-X | 35M | Baseline |
| Octo-Base | 93M | +29% over RT-1-X |
| RT-2-X | 55B | Comparable to Octo-Base |
Fine-tuning results
Octo demonstrates strong fine-tuning transfer to novel robots including WidowX, Franka, and custom platforms. Fine-tuning with ~100 demonstrations on a single A5000 GPU in <5 hours outperforms training from scratch and state-of-the-art visual representation fine-tuning (VC-1) by an average of 52% across six diverse fine-tuning setups.

Scaling and ablations
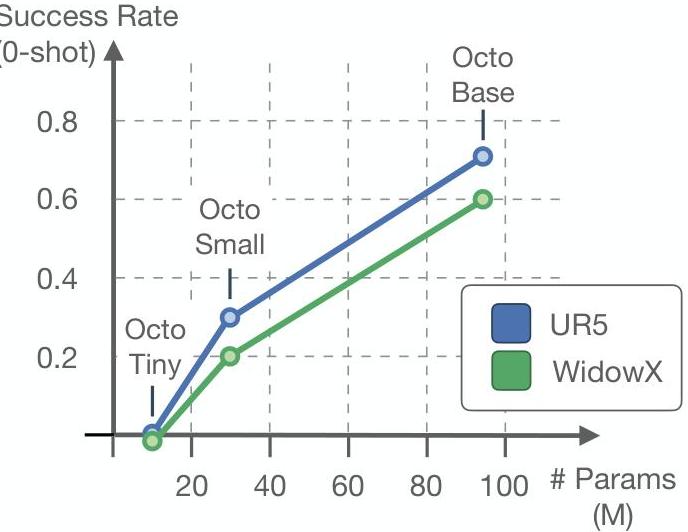
Key ablation findings: - Architecture matters: ViT-based backbone significantly outperforms ResNet-based alternatives, even at matched parameter counts - Data diversity scales: Adding more diverse datasets improves generalization, even when individual dataset quality varies - Diffusion > MSE > Discretized: Diffusion action head consistently outperforms alternatives, especially on tasks with multi-modal action distributions - Model size scales: Octo-Base (93M) substantially outperforms Octo-Small (27M) across evaluations
Limitations & Open Questions
- No language generation: Unlike RT-2, Octo does not produce language outputs, limiting interpretability and chain-of-thought reasoning capabilities
- Single-image observation: While Octo supports multi-camera inputs, the primary evaluation uses single-camera setups; performance with richer sensory configurations is less explored
- Action space constraints: The diffusion head predicts fixed-length action chunks; adaptive-horizon prediction could improve efficiency
- Scale ceiling: At 93M parameters, Octo is orders of magnitude smaller than RT-2-X (55B); whether Octo's architecture scales gracefully to billions of parameters is untested
- Fine-tuning vs. zero-shot gap: Zero-shot performance on truly novel embodiments remains limited; fine-tuning is still necessary for deployment on new robots
Connections
Related papers in the wiki: - Rt 1 Robotics Transformer For Real World Control At Scale — RT-1 provides the foundational scaling insight (more data > better architecture) that Octo builds upon, and RT-1-X serves as the primary baseline - Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control — RT-2 established the VLA paradigm; Octo democratizes a similar capability at 600x fewer parameters with open weights - Openvla An Open Source Vision Language Action Model — OpenVLA (2024) directly builds on Octo's open-source ethos, scaling to 7B parameters with a VLM backbone; Octo is the predecessor open-source baseline - Pi0 A Vision Language Action Flow Model For General Robot Control — pi0 uses flow matching (vs. Octo's diffusion) for action decoding and scales to 68 tasks across 7 platforms; represents the next generation of generalist policies - Hpt Scaling Proprioceptive Visual Learning With Heterogeneous Pre Trained Transformers — HPT's stem-trunk-head architecture addresses the same cross-embodiment challenge as Octo's modular tokenization, with complementary scaling law evidence - Uniact Universal Actions For Enhanced Embodied Foundation Models — UniAct proposes universal action spaces via VQ codebooks as an alternative to Octo's diffusion-based continuous actions for cross-embodiment transfer - Dita Scaling Diffusion Transformer For Generalist Vla Policy — Dita extends the diffusion transformer approach to VLA with in-context conditioning, achieving stronger few-shot adaptation - Robocat A Self Improving Generalist Agent For Robotic Manipulation — RoboCat (DeepMind, 2023) shares Octo's multi-embodiment goal but uses self-improvement loops rather than open-source community adaptation - Robotics — Broader context on the VLA revolution in robotics - Vision Language Action — Design axes and paradigm evolution for VLA models - Foundation Models — Octo as a robotics foundation model