pi0: A Vision-Language-Action Flow Model for General Robot Control
Overview
pi0 is a vision-language-action flow model developed by Physical Intelligence that represents a foundational step toward general-purpose robot control. The key innovation is replacing autoregressive action prediction with flow matching -- a continuous generative approach related to diffusion models -- enabling high-frequency control (up to 50 Hz) necessary for dexterous manipulation. Built on a PaliGemma 3B VLM backbone (with an additional ~300M-parameter action expert, totaling ~3.3B parameters), pi0 is pre-trained on over 10,000 hours (903 million timesteps) of diverse robot interaction data spanning 7 robot platforms and 68 tasks, then fine-tuned for specific downstream applications. The model takes multiple RGB camera images, language instructions, and proprioceptive state (joint angles) as inputs.
The model addresses three interconnected challenges in robotics: data scarcity compared to text/image domains, limited generalization across environments and embodiments, and lack of robustness in unexpected situations. By scaling up robot data and implementing a pre-train/fine-tune paradigm mirroring LLM development, pi0 demonstrates that a single generalist policy can achieve strong performance across diverse manipulation tasks including dexterous multi-finger control, bimanual coordination, and long-horizon sequential tasks.
Key Contributions
- Flow matching for VLA: First VLA to use flow matching instead of autoregressive token prediction for action generation, enabling continuous action output at up to 50 Hz -- critical for dexterous tasks requiring smooth, precise movements
- Cross-embodiment pre-training at scale: Pre-trained on 10,000+ hours of diverse robot data across 7 platforms (single-arm, bimanual, mobile manipulators), establishing the pre-train/fine-tune paradigm for robot foundation models
- 68-task generalist policy: Single model handles 68 tasks spanning table-top manipulation, laundry folding, box assembly, and bussing, demonstrating breadth previously unseen in a single robot policy
- Language-conditioned dexterous control: Combines high-level language understanding from the VLM backbone with fine-grained motor control through the flow matching action head
Architecture / Method
┌──────────┐ ┌───────────────────┐
│ Camera │ │ Language Instruction│
│ Images │ │ "fold the shirt" │
└────┬─────┘ └────────┬──────────┘
│ │
▼ ▼
┌────────────────────────────────┐
│ PaliGemma 3B VLM Backbone │
│ (Vision Encoder + LM Decoder) │
└──────────────┬─────────────────┘
│ multimodal features
▼
┌────────────────────────────────┐
│ Flow Matching Action Head │
│ │
│ Noise z ~ N(0,I) │
│ │ │
│ ▼ │
│ ┌──────────────────┐ │
│ │ Learned Velocity │ ◄─ VLM │
│ │ Field v(x_t, t) │ features│
│ └────────┬─────────┘ │
│ │ iterative denoise │
│ ▼ │
│ Action Chunk (50 steps @50Hz) │
└──────────────┬─────────────────┘
│
▼
┌─────────────────┐
│ Robot Actions │
│ (continuous) │
└─────────────────┘
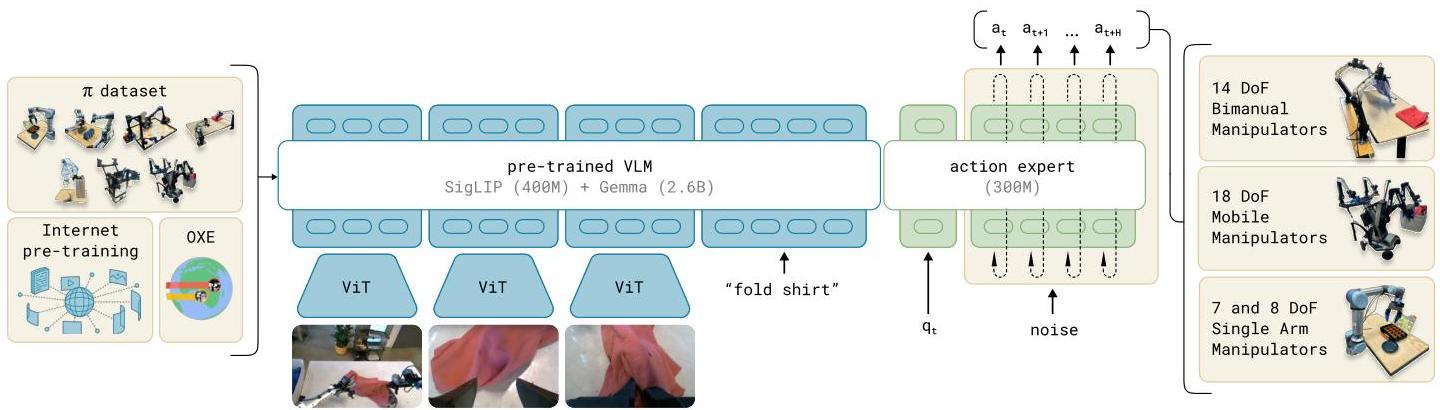
pi0 builds on PaliGemma 3B as the vision-language backbone (~3B parameters), augmented by a dedicated action expert module (~300M parameters), for a total of ~3.3B parameters. Multiple RGB camera images, language instructions, and proprioceptive state (joint angles) are processed through the VLM to produce rich multimodal representations. Rather than discretizing actions into tokens and predicting them autoregressively (as in RT-2 or OpenVLA), pi0 attaches a flow matching head that generates continuous action trajectories. A blockwise causal attention mask separates VLM processing from robotics-specific action generation, preserving pre-trained VLM capabilities.
Flow matching works by learning a velocity field that transforms a simple noise distribution into the target action distribution. During inference, the model iteratively denoises a random sample through the learned flow to produce an action chunk -- a sequence of future actions predicted in parallel. This approach handles multimodal action distributions naturally (unlike MSE regression) and avoids the quantization artifacts of discrete tokenization.
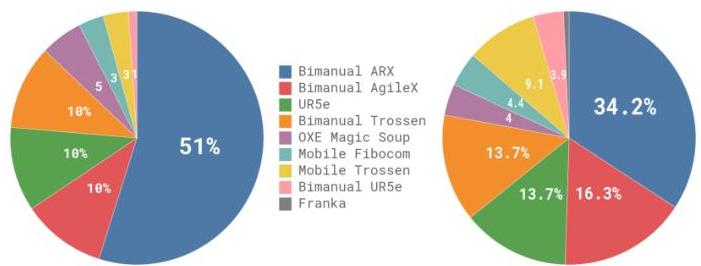
The training follows a two-stage recipe: (1) large-scale pre-training on 903 million timesteps of proprietary dexterous manipulation data (68 tasks, 7 robot configurations, up to 50 Hz) combined with a 9.1% mixture of open-source data from OXE, Bridge v2, and DROID datasets; and (2) task-specific fine-tuning on targeted demonstrations. Task-robot combinations are weighted by n^0.43 to prevent over-represented configurations from dominating. Action chunking with chunks of 50 steps at 50 Hz (1 second lookahead) provides temporal coherence and enables the model to plan short-horizon trajectories rather than reacting step-by-step.
Results
| Task Category | Platforms | Success Rate | Notes |
|---|---|---|---|
| Table-top manipulation | Single-arm | High | Standard pick-place, stacking |
| Laundry folding | Bimanual | Moderate | Long-horizon, deformable objects |
| Box assembly | Bimanual | Moderate | Multi-step sequential |
| Dexterous manipulation | Multi-finger | Demonstrated | High-DoF continuous control |
| Bussing tasks | Mobile manipulator | Demonstrated | Combined navigation + manipulation |
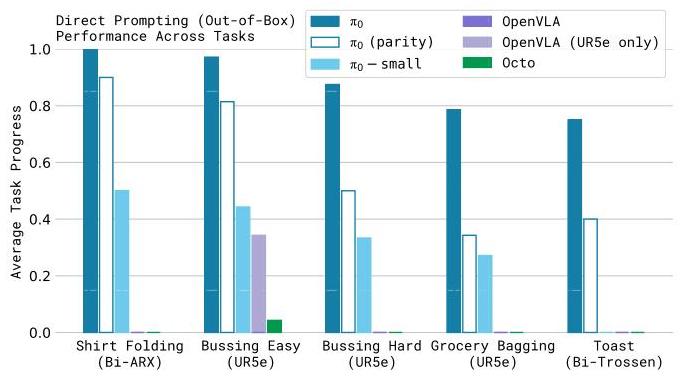
- Pre-training on diverse data followed by fine-tuning consistently outperforms training from scratch on individual tasks
- Flow matching enables smooth 50 Hz control needed for contact-rich dexterous tasks that autoregressive VLAs cannot handle
- The same pretrained model is evaluated across single-arm, bimanual, and mobile-manipulation settings, but the paper does not isolate cross-embodiment transfer in a dedicated ablation
- Language conditioning enables zero-shot task specification for seen task categories with novel object instances
Limitations
- Requires large-scale proprietary robot data (10,000+ hours) not publicly available, limiting reproducibility
- Fine-tuning still needed for each new task family; true zero-shot generalization to novel task categories remains limited
- No temporal history of observations; the model processes only current images without memory of past frames, limiting reasoning about dynamics and task progress
- Evaluation primarily on in-house platforms; limited third-party benchmarking compared to open models like OpenVLA
- The paper does not cleanly separate the effect of cross-embodiment transfer from the effect of simply scaling data and model size
Connections
- Vision Language Action -- pi0 is the reference VLA architecture from Physical Intelligence
- Robotics -- primary application domain spanning 7 robot platforms
- Foundation Models -- demonstrates the pre-train/fine-tune paradigm for robot foundation models
- Openvla An Open Source Vision Language Action Model -- OpenVLA uses autoregressive tokens; pi0 uses flow matching, a fundamentally different action generation approach
- Rt 2 Vision Language Action Models Transfer Web Knowledge To Robotic Control -- RT-2 pioneered VLA; pi0 advances beyond autoregressive action generation
- Palm E An Embodied Multimodal Language Model -- PaLM-E provided embodied multimodal foundations; pi0 focuses on action generation quality